 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePessimism Meets Risk: Risk-Sensitive Offline Reinforcement Learning
Paper and Code
Jul 10, 2024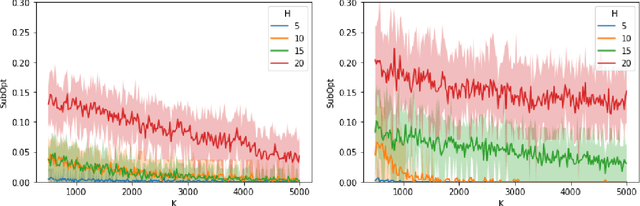
We study risk-sensitive reinforcement learning (RL), a crucial field due to its ability to enhance decision-making in scenarios where it is essential to manage uncertainty and minimize potential adverse outcomes. Particularly, our work focuses on applying the entropic risk measure to RL problems. While existing literature primarily investigates the online setting, there remains a large gap in understanding how to efficiently derive a near-optimal policy based on this risk measure using only a pre-collected dataset. We center on the linear Markov Decision Process (MDP) setting, a well-regarded theoretical framework that has yet to be examined from a risk-sensitive standpoint. In response, we introduce two provably sample-efficient algorithms. We begin by presenting a risk-sensitive pessimistic value iteration algorithm, offering a tight analysis by leveraging the structure of the risk-sensitive performance measure. To further improve the obtained bounds, we propose another pessimistic algorithm that utilizes variance information and reference-advantage decomposition, effectively improving both the dependence on the space dimension $d$ and the risk-sensitivity factor. To the best of our knowledge, we obtain the first provably efficient risk-sensitive offline RL algorithms.