 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePriorVLA: Prior-Preserving Adaptation for Vision-Language-Action Models
May 11, 2026Large-scale pretraining has made Vision-Language-Action (VLA) models promising foundations for generalist robot manipulation, yet adapting them to downstream tasks remains necessary. However, the common practice of full fine-tuning treats pretraining as initialization and can shift broad priors toward narrow training-distribution patterns. We propose PriorVLA, a novel framework that preserves pretrained priors and learns to leverage them for effective adaptation. PriorVLA keeps a frozen Prior Expert as a read-only prior source and trains an Adaptation Expert for downstream specialization. Expert Queries capture scene priors from the pretrained VLM and motor priors from the Prior Expert, integrating both into the Adaptation Expert to guide adaptation. Together, PriorVLA updates only 25% of the parameters updated by full fine-tuning. Across RoboTwin 2.0, LIBERO, and real-world tasks, PriorVLA achieves stronger overall performance than full fine-tuning and state-of-the-art VLA baselines, with the largest gains under out-of-distribution (OOD) and few-shot settings. PriorVLA improves over pi0.5 by 11 points on RoboTwin 2.0-Hard and achieves 99.1% average success on LIBERO. Across eight real-world tasks and two embodiments, PriorVLA reaches 81% in-distribution (ID) and 57% OOD success with standard data. With only 10 demonstrations per task, PriorVLA reaches 48% ID and 32% OOD success, surpassing pi0.5 by 24 and 22 points, respectively.
M$^{2}$GRPO: Mamba-based Multi-Agent Group Relative Policy Optimization for Biomimetic Underwater Robots Pursuit
Apr 21, 2026Traditional policy learning methods in cooperative pursuit face fundamental challenges in biomimetic underwater robots, where long-horizon decision making, partial observability, and inter-robot coordination require both expressiveness and stability. To address these issues, a novel framework called Mamba-based multi-agent group relative policy optimization (M$^{2}$GRPO) is proposed, which integrates a selective state-space Mamba policy with group-relative policy optimization under the centralized-training and decentralized-execution (CTDE) paradigm. Specifically, the Mamba-based policy leverages observation history to capture long-horizon temporal dependencies and exploits attention-based relational features to encode inter-agent interactions, producing bounded continuous actions through normalized Gaussian sampling. To further improve credit assignment without sacrificing stability, the group-relative advantages are obtained by normalizing rewards across agents within each episode and optimized through a multi-agent extension of GRPO, significantly reducing the demand for training resources while enabling stable and scalable policy updates. Extensive simulations and real-world pool experiments across team scales and evader strategies demonstrate that M$^{2}$GRPO consistently outperforms MAPPO and recurrent baselines in both pursuit success rate and capture efficiency. Overall, the proposed framework provides a practical and scalable solution for cooperative underwater pursuit with biomimetic robot systems.
USIM and U0: A Vision-Language-Action Dataset and Model for General Underwater Robots
Oct 09, 2025



Underwater environments present unique challenges for robotic operation, including complex hydrodynamics, limited visibility, and constrained communication. Although data-driven approaches have advanced embodied intelligence in terrestrial robots and enabled task-specific autonomous underwater robots, developing underwater intelligence capable of autonomously performing multiple tasks remains highly challenging, as large-scale, high-quality underwater datasets are still scarce. To address these limitations, we introduce USIM, a simulation-based multi-task Vision-Language-Action (VLA) dataset for underwater robots. USIM comprises over 561K frames from 1,852 trajectories, totaling approximately 15.6 hours of BlueROV2 interactions across 20 tasks in 9 diverse scenarios, ranging from visual navigation to mobile manipulation. Building upon this dataset, we propose U0, a VLA model for general underwater robots, which integrates binocular vision and other sensor modalities through multimodal fusion, and further incorporates a convolution-attention-based perception focus enhancement module (CAP) to improve spatial understanding and mobile manipulation. Across tasks such as inspection, obstacle avoidance, scanning, and dynamic tracking, the framework achieves a success rate of 80%, while in challenging mobile manipulation tasks, it reduces the distance to the target by 21.2% compared with baseline methods, demonstrating its effectiveness. USIM and U0 show that VLA models can be effectively applied to underwater robotic applications, providing a foundation for scalable dataset construction, improved task autonomy, and the practical realization of intelligent general underwater robots.
UC-OWOD: Unknown-Classified Open World Object Detection
Jul 23, 2022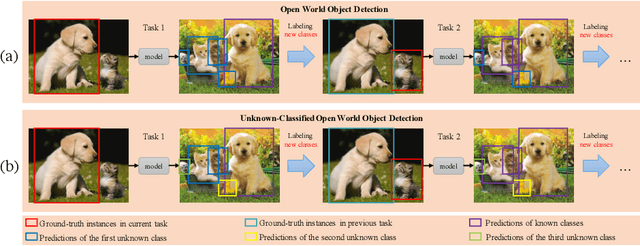



Open World Object Detection (OWOD) is a challenging computer vision problem that requires detecting unknown objects and gradually learning the identified unknown classes. However, it cannot distinguish unknown instances as multiple unknown classes. In this work, we propose a novel OWOD problem called Unknown-Classified Open World Object Detection (UC-OWOD). UC-OWOD aims to detect unknown instances and classify them into different unknown classes. Besides, we formulate the problem and devise a two-stage object detector to solve UC-OWOD. First, unknown label-aware proposal and unknown-discriminative classification head are used to detect known and unknown objects. Then, similarity-based unknown classification and unknown clustering refinement modules are constructed to distinguish multiple unknown classes. Moreover, two novel evaluation protocols are designed to evaluate unknown-class detection. Abundant experiments and visualizations prove the effectiveness of the proposed method. Code is available at https://github.com/JohnWuzh/UC-OWOD.
HybrUR: A Hybrid Physical-Neural Solution for Unsupervised Underwater Image Restoration
Jul 06, 2021
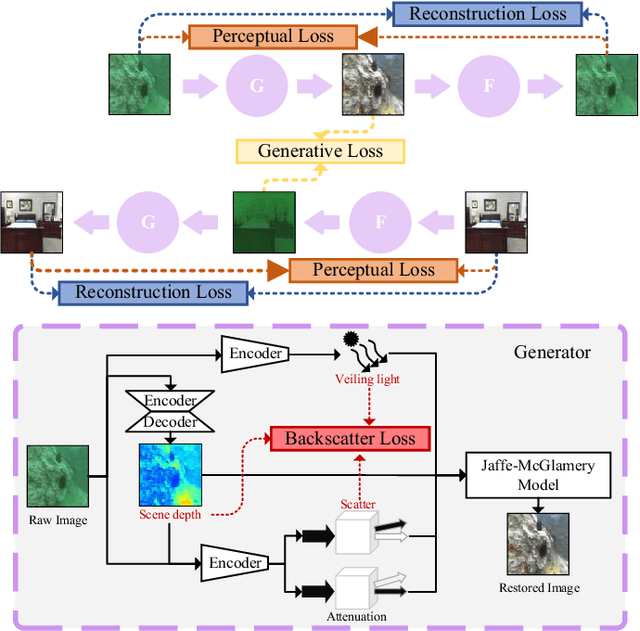
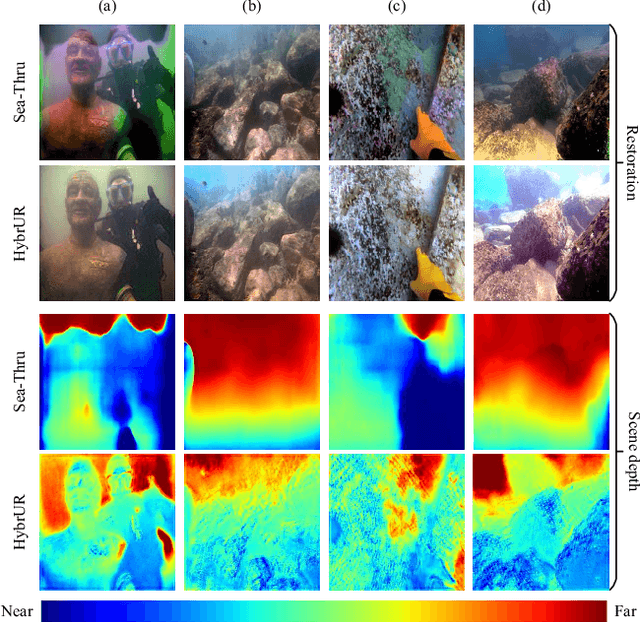

Robust vision restoration for an underwater image remains a challenging problem. For the lack of aligned underwater-terrestrial image pairs, the unsupervised method is more suited to this task. However, the pure data-driven unsupervised method usually has difficulty in achieving realistic color correction for lack of optical constraint. In this paper, we propose a data- and physics-driven unsupervised architecture that learns underwater vision restoration from unpaired underwater-terrestrial images. For sufficient domain transformation and detail preservation, the underwater degeneration needs to be explicitly constructed based on the optically unambiguous physics law. Thus, we employ the Jaffe-McGlamery degradation theory to design the generation models, and use neural networks to describe the process of underwater degradation. Furthermore, to overcome the problem of invalid gradient when optimizing the hybrid physical-neural model, we fully investigate the intrinsic correlation between the scene depth and the degradation factors for the backscattering estimation, to improve the restoration performance through physical constraints. Our experimental results show that the proposed method is able to perform high-quality restoration for unconstrained underwater images without any supervision. On multiple benchmarks, we outperform several state-of-the-art supervised and unsupervised approaches. We also demonstrate that our methods yield encouraging results on real-world applications.
Reveal of Domain Effect: How Visual Restoration Contributes to Object Detection in Aquatic Scenes
Mar 04, 2020

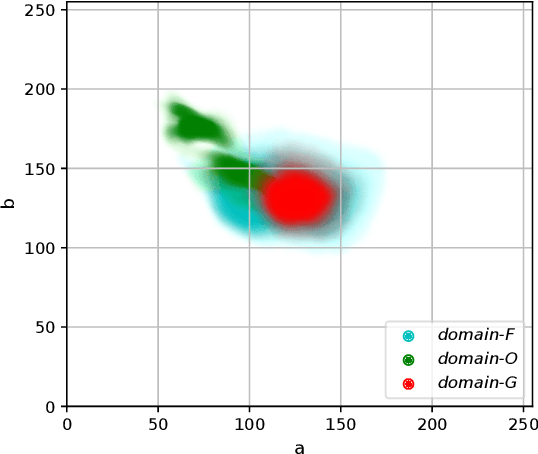

Underwater robotic perception usually requires visual restoration and object detection, both of which have been studied for many years. Meanwhile, data domain has a huge impact on modern data-driven leaning process. However, exactly indicating domain effect, the relation between restoration and detection remains unclear. In this paper, we generally investigate the relation of quality-diverse data domain to detection performance. In the meantime, we unveil how visual restoration contributes to object detection in real-world underwater scenes. According to our analysis, five key discoveries are reported: 1) Domain quality has an ignorable effect on within-domain convolutional representation and detection accuracy; 2) low-quality domain leads to higher generalization ability in cross-domain detection; 3) low-quality domain can hardly be well learned in a domain-mixed learning process; 4) degrading recall efficiency, restoration cannot improve within-domain detection accuracy; 5) visual restoration is beneficial to detection in the wild by reducing the domain shift between training data and real-world scenes. Finally, as an illustrative example, we successfully perform underwater object detection with an aquatic robot.
Continuity, Stability, and Integration: Novel Tracking-Based Perspectives for Temporal Object Detection
Dec 22, 2019
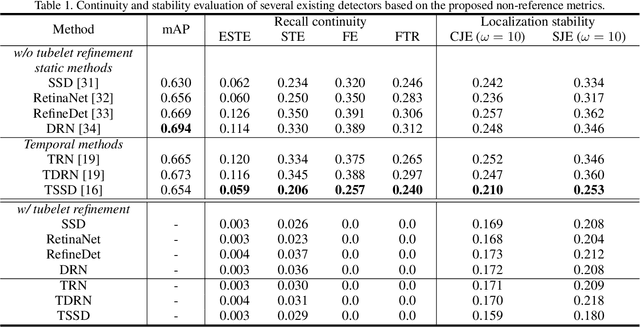
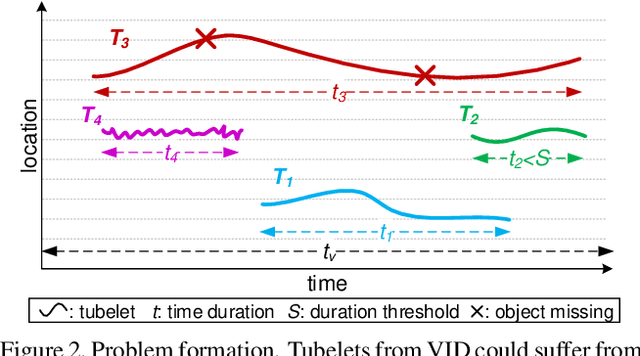
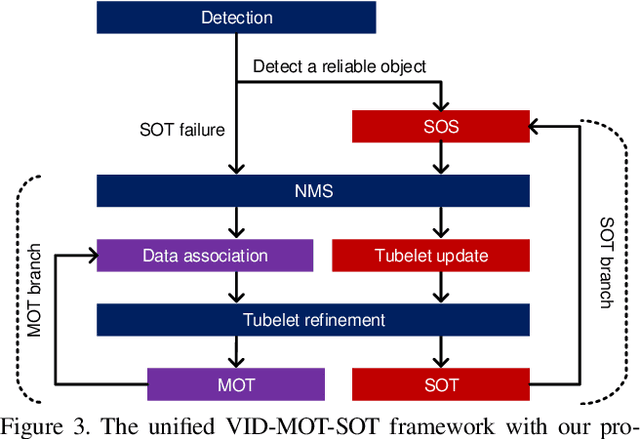
Video object detection (VID) has been vigorously studied for years but almost all literature adopts a static accuracy-based evaluation, i.e., mean average precision (mAP). From a temporal perspective, the importance of recall continuity and localization stability is equal to that of accuracy, but the mAP is insufficient to reflect detectors' performance across time. In this paper, non-reference assessments are proposed for continuity and stability based on tubelets from multi-object tracking (MOT). These temporal evaluations can serve as supplements to static mAP. Further, we develop tubelet refinement for improving detectors' performance on temporal continuity and stability through short tubelet suppression, fragment filling, and history-present fusion. In addition, we propose a small-overlap suppression to extend VID methods to single object tracking (SOT) task. The VID-based SOT does not need MOT or traditional SOT model. A unified VID-MOT-SOT framework is then formed. Extensive experiments are conducted on ImageNet VID dataset, where the superiority of our proposed approaches are validated and verified. Codes will be publicly available.
Towards Real-Time Accurate Object Detection in Both Images and Videos Based on Dual Refinement
Dec 17, 2018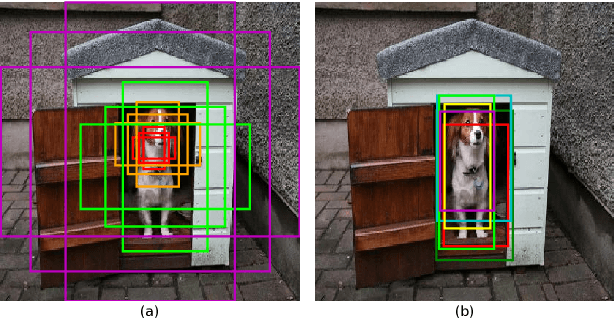
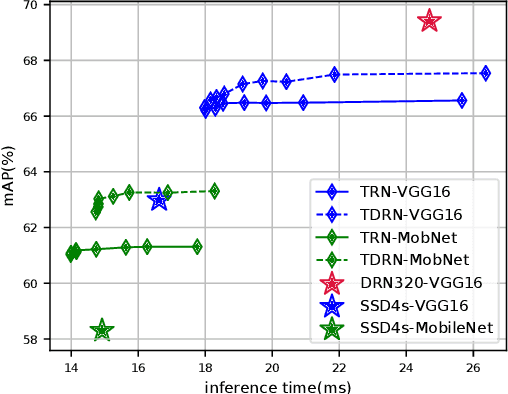

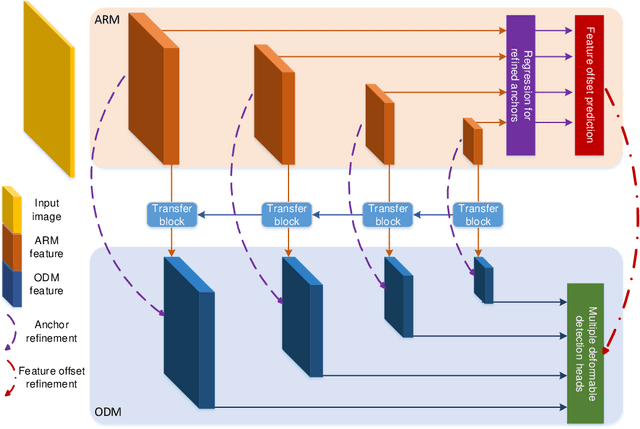
Object detection has been vigorously studied for years but fast accurate detection for real-world applications remains a very challenging problem: i) Most existing methods have either high accuracy or fast speed; ii) Most prior-art approaches focus on static images, ignoring temporal information in real-world scenes. Overcoming drawbacks of single-stage detectors, we take aim at precisely detecting objects in both images and videos in real time. Firstly, as a dual refinement mechanism, a novel anchor-offset detection including an anchor refinement, a feature offset refinement, and a deformable detection head is designed for two-step regression and capturing accurate detection features. Based on the anchor-offset detection, a dual refinement network (DRN) is developed for high-performance static detection, where a multi-deformable head is further designed to leverage contextual information for describing objects. As for video detection, temporal refinement networks (TRN) and temporal dual refinement networks (TDRN) are developed by propagating the refinement information across time. Our proposed methods are evaluated on PASCAL VOC, COCO, and ImageNet VID datasets. Extensive comparison on static and temporal detection validate the superiority of the DRN, TRN and TDRN. Consequently, our developed approaches achieve a significantly enhanced detection accuracy and make prominent progress in accuracy vs. speed trade-off. Codes will be publicly available.
Temporally Identity-Aware SSD with Attentional LSTM
Apr 26, 2018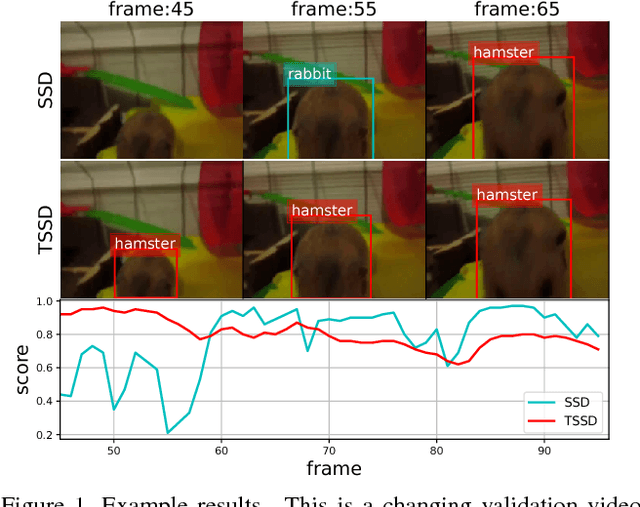
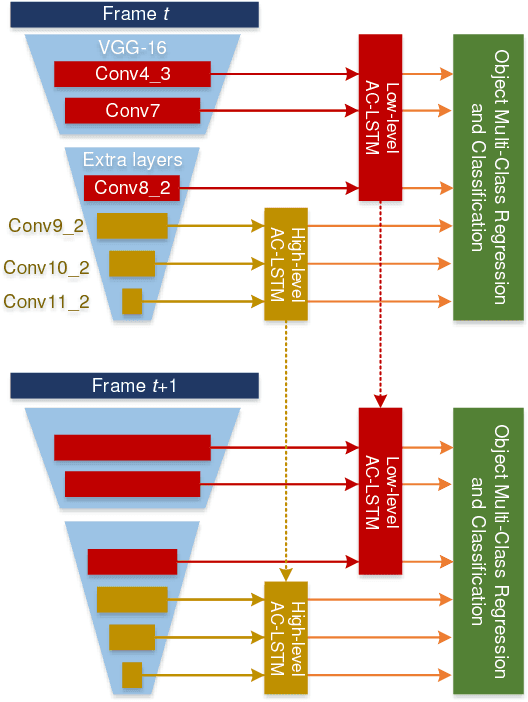
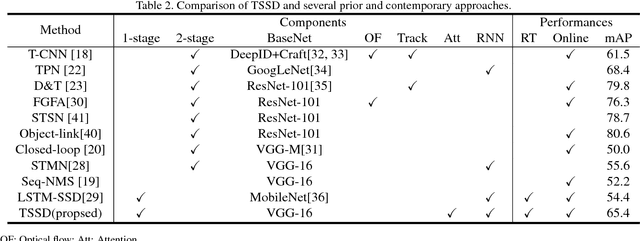
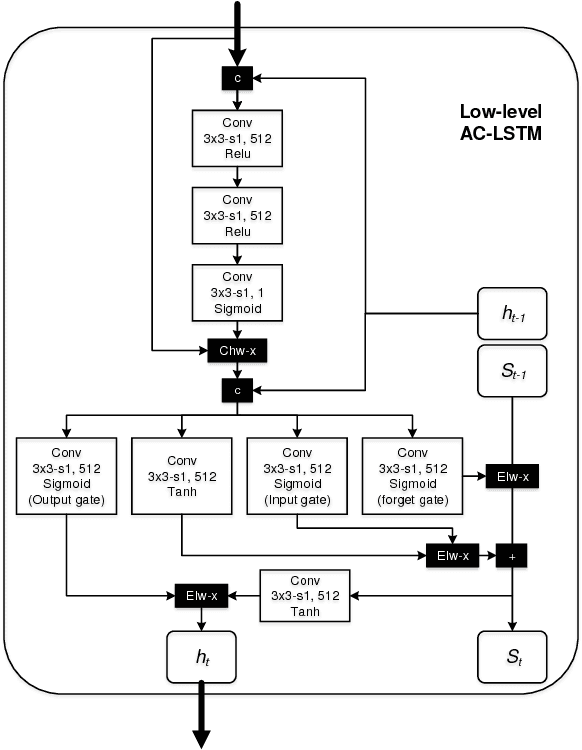
Temporal object detection has attracted significant attention, but most popular detection methods can not leverage the rich temporal information in videos. Very recently, many different algorithms have been developed for video detection task, but real-time online approaches are frequently deficient. In this paper, based on attention mechanism and convolutional long short-term memory (ConvLSTM), we propose a temporal signal-shot detector (TSSD) for real-world detection. Distinct from previous methods, we take aim at temporally integrating pyramidal feature hierarchy using ConvLSTM, and design a novel structure including a low-level temporal unit as well as a high-level one (HL-TU) for multi-scale feature maps. Moreover, we develop a creative temporal analysis unit, namely, attentional ConvLSTM (AC-LSTM), in which a temporal attention module is specially tailored for background suppression and scale suppression while a ConvLSTM integrates attention-aware features through time. An association loss is designed for temporal coherence. Besides, online tubelet analysis (OTA) is exploited for identification. Finally, our method is evaluated on ImageNet VID dataset and 2DMOT15 dataset. Extensive comparisons on the detection and tracking capability validate the superiority of the proposed approach. Consequently, the developed TSSD-OTA is fairly faster and achieves an overall competitive performance in terms of detection and tracking. The source code will be made available.
Towards Quality Advancement of Underwater Machine Vision with Generative Adversarial Networks
Jan 16, 2018
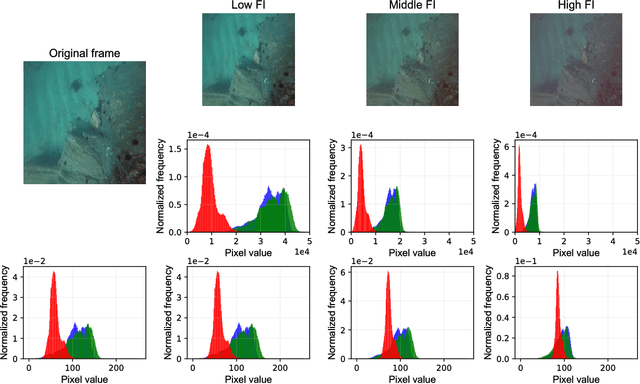
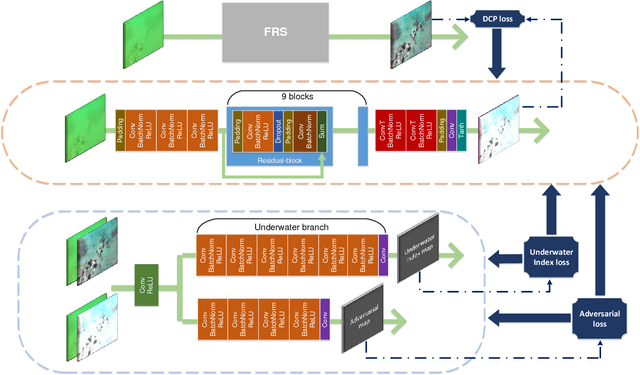
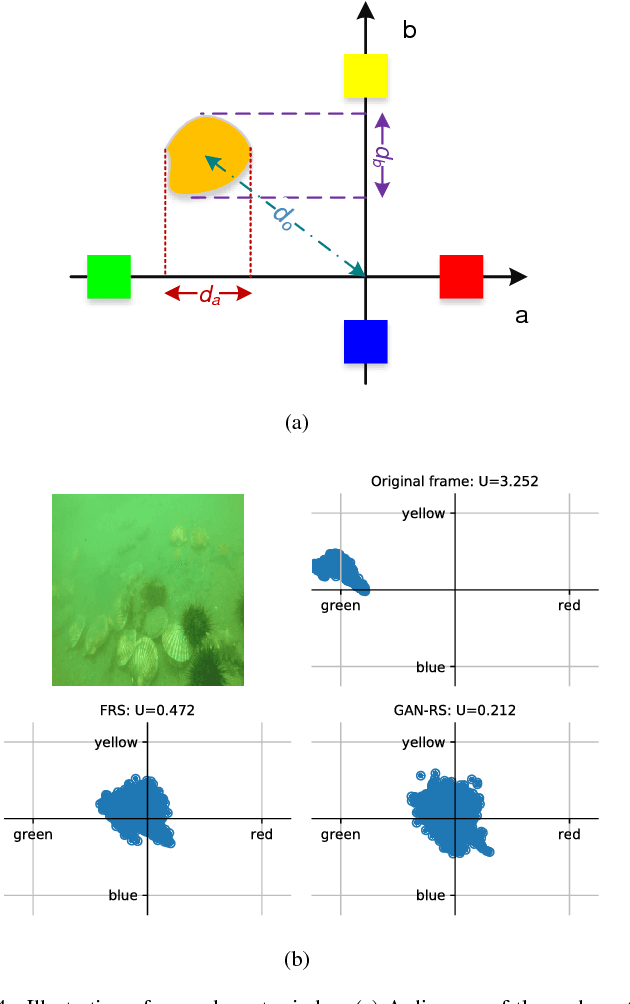
Underwater machine vision has attracted significant attention, but its low quality has prevented it from a wide range of applications. Although many different algorithms have been developed to solve this problem, real-time adaptive methods are frequently deficient. In this paper, based on filtering and the use of generative adversarial networks (GANs), two approaches are proposed for the aforementioned issue, i.e., a filtering-based restoration scheme (FRS) and a GAN-based restoration scheme (GAN-RS). Distinct from previous methods, FRS restores underwater images in the Fourier domain, which is composed of a parameter search, filtering, and enhancement. Aiming to further improve the image quality, GAN-RS can adaptively restore underwater machine vision in real time without the need for pretreatment. In particular, information in the Lab color space and the dark channel is developed as loss functions, namely, underwater index loss and dark channel prior loss, respectively. More specifically, learning from the underwater index, the discriminator is equipped with a carefully crafted underwater branch to predict the underwater probability of an image. A multi-stage loss strategy is then developed to guarantee the effective training of GANs. Through extensive comparisons on the image quality and applications, the superiority of the proposed approaches is confirmed. Consequently, the GAN-RS is considerably faster and achieves a state-of-the-art performance in terms of the color correction, contrast stretch, dehazing, and feature restoration of various underwater scenes. The source code will be made available.