 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement learning in linear embedding space unlocks generalizable control across soft robot configurations
Jun 06, 2026Soft-bodied organisms such as octopuses and elephant trunks exhibit remarkable morphological adaptability, dynamically reconfiguring body shape and stiffness, and flexibly adjusting their control strategies to enable versatile behaviors. Inspired by these biological systems, various soft robots have emerged in recent decades, featuring diverse materials, stiffnesses, and morphologies tailored to specific tasks. Despite substantial advances in the materials and structural designs of soft robots, developing a generalizable control framework capable of rapid adaptation across diverse configurations remains a long-standing challenge. Existing controllers are limited to fixed configurations, demanding laborious configuration-specific remodelling and policy redesign for new configurations. Here, we introduce a generalizable control system that enables rapid adaptation across diverse soft robot configurations via reinforcement learning in a shared linear Koopman embedding space. By encoding robot dynamics into this embedding space, our method decouples control policies from specific morphologies, allowing real-time, model-free policy adaptation across diverse configurations without retraining from scratch. We validate our system across 33 distinct robot configurations. Our system achieves a 75 times reduction in transfer samples across configurations, while sustaining robust performance under high-speed motion, heavy payloads, and multiactuator faults, and achieving real-world skills previously unattainable in soft robotics. This work establishes a unified and adaptable control paradigm for diverse soft robot configurations, bridging mechanical reconfigurability with control flexibility, and may offer broader insights for generalizable control in complex physical systems.
A Bioinspired Underwater Robot with a Latch-Mediated Soft Bistable Mechanism
May 26, 2026Underwater robotics has advanced significantly over recent decades. however, the development of miniaturized underwater robots remains limited by low energy densities of traditional power sources. Nature offers compelling solutions-organisms like mantis shrimps and fleas utilize latch-mediated spring actuation (LaMSA) systems that achieve rapid movements through a decoupled energy storage and release mechanism. Despite extensive studies of LaMSA, replicating such rapid, asymmetric actuation within simple, compact structures remains challenging. In this work, we introduce a bioinspired, soft bistable actuator with an integrated latch mechanism that enables asymmetric energy input and release using a single motor. Coupled with fin structures, this design facilitates efficient underwater propulsion and maneuverability. Experimental results demonstrate stable periodic flapping, precise steering, and a maximum thrust of 0.528 N, impulse of 0.147 Ns, and vertical displacement of 30 mm. By modulating fin angles, the robot achieves versatile motions, including vertical ascent, diagonal forward movement, and lateral translation. This study presents a novel, energy-efficient approach for controlling motion in compact underwater robots, paving the way for advanced biomimetic designs with potential applications in exploration, environmental monitoring, and inspection.
ManiSoft: Towards Vision-Language Manipulation for Soft Continuum Robotics
May 18, 2026Most existing vision-language manipulation research targets rigid robotic arms, whose fixed morphology limits adaptability in cluttered or confined spaces. Soft robotic arms offer an appealing alternative due to their deformability, but confront challenges such as unreliable proprioception and distributed low-level actuation. To investigate these challenges, we introduce \ManiSoft, a benchmark for vision-language manipulation with soft arms. ManiSoft features a tailored simulator that couples realistic soft-body dynamics with contact-rich interactions via an elastic force constraint. On this basis, ManiSoft defines four tasks, each highlighting distinct aspects of deformable control, from basic end-effector coordination to obstacle avoidance. To support policy training and evaluation, \ManiSoft{} includes an automated pipeline that generates $6{,}300$ diverse scenes and corresponding expert trajectories. To produce high-quality trajectories at scale, we first employ a high-level planner to decompose each task into a sequence of waypoints, followed by a low-level reinforcement learning policy that generates torque commands to track waypoints. Benchmarking three representative policy models shows relatively promising results in clean scenes but substantial performance drop under randomization. Visualization analysis indicates that failures stem primarily from inaccurate visual estimation of proprioceptive state and limited exploitation of deformability for adaptive obstacle avoiding. We anticipate ManiSoft to serve as a valuable testbed, bridging the gap between rigid and soft arms in the context of vision-language manipulation. Out codes and datasets are released at https://buaa-colalab.github.io/ManiSoft.
Consistency-Driven Dual LSTM Models for Kinematic Control of a Wearable Soft Robotic Arm
Mar 18, 2026In this paper, we introduce a consistency-driven dual LSTM framework for accurately learning both the forward and inverse kinematics of a pneumatically actuated soft robotic arm integrated into a wearable device. This approach effectively captures the nonlinear and hysteretic behaviors of soft pneumatic actuators while addressing the one-to-many mapping challenge between actuation inputs and end-effector positions. By incorporating a cycle consistency loss, we enhance physical realism and improve the stability of inverse predictions. Extensive experiments-including trajectory tracking, ablation studies, and wearable demonstrations-confirm the effectiveness of our method. Results indicate that the inclusion of the consistency loss significantly boosts prediction accuracy and promotes physical consistency over conventional approaches. Moreover, the wearable soft robotic arm demonstrates strong human-robot collaboration capabilities and adaptability in everyday tasks such as object handover, obstacle-aware pick-and-place, and drawer operation. This work underscores the promising potential of learning-based kinematic models for human-centric, wearable robotic systems.
Reveal of Domain Effect: How Visual Restoration Contributes to Object Detection in Aquatic Scenes
Mar 04, 2020

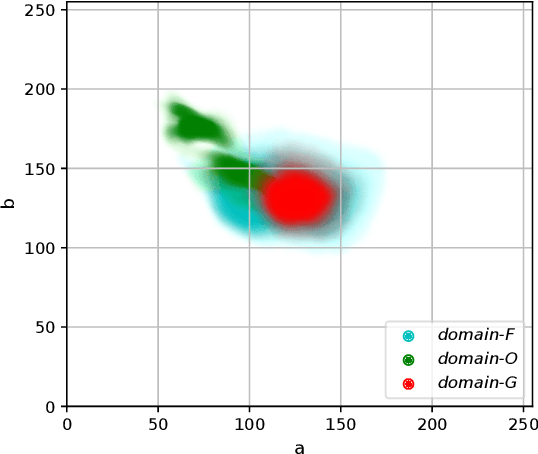

Underwater robotic perception usually requires visual restoration and object detection, both of which have been studied for many years. Meanwhile, data domain has a huge impact on modern data-driven leaning process. However, exactly indicating domain effect, the relation between restoration and detection remains unclear. In this paper, we generally investigate the relation of quality-diverse data domain to detection performance. In the meantime, we unveil how visual restoration contributes to object detection in real-world underwater scenes. According to our analysis, five key discoveries are reported: 1) Domain quality has an ignorable effect on within-domain convolutional representation and detection accuracy; 2) low-quality domain leads to higher generalization ability in cross-domain detection; 3) low-quality domain can hardly be well learned in a domain-mixed learning process; 4) degrading recall efficiency, restoration cannot improve within-domain detection accuracy; 5) visual restoration is beneficial to detection in the wild by reducing the domain shift between training data and real-world scenes. Finally, as an illustrative example, we successfully perform underwater object detection with an aquatic robot.
A Multimodal, Enveloping Soft Gripper: Shape Conformation, Bioinspired Adhesion, and Expansion-Driven Suction
Dec 14, 2019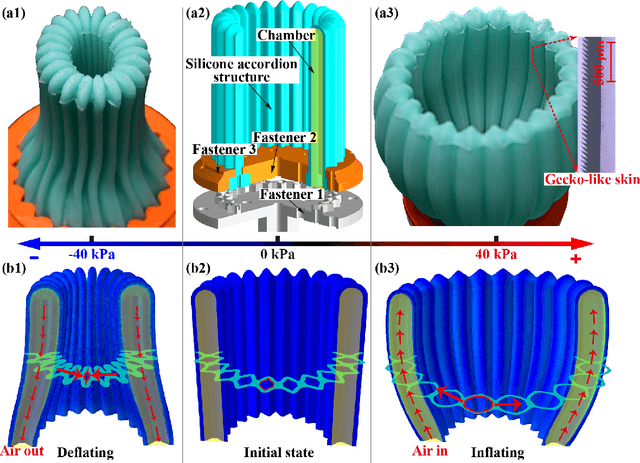
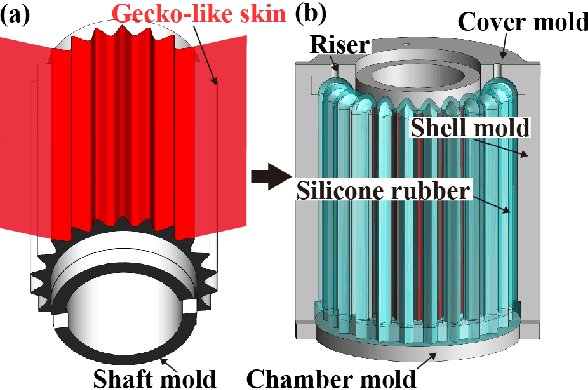
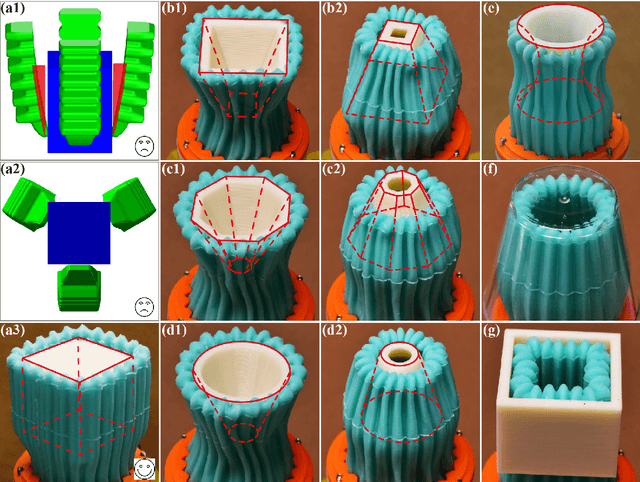
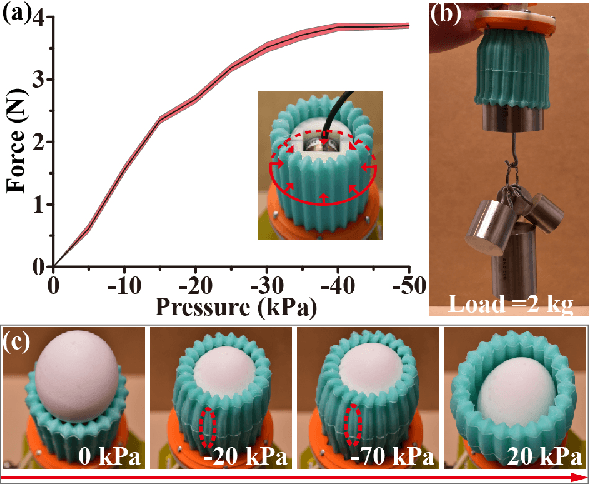
A key challenge in robotics is to create efficient methods for grasping objects with diverse shapes, sizes, poses, and properties. Grasping with hand-like end effectors often requires careful selection of hand orientation and finger placement. Here, we present a soft, fingerless gripper capable of efficiently generating multiple grasping modes. It is based on a soft, cylindrical accordion structure containing coupled, parallel fluidic channels. It is controlled via pressure supplied from a single fluidic port. Inflation opens the gripper orifice for enveloping an object, while deflation allows it to produce grasping forces. The interior is patterned with a gecko-like skin that increases friction, enabling the gripper to lift objects weighing up to 20 N. Our design ensures that fragile objects, such as eggs, can be safely handled, by virtue of a wall buckling mechanism. The gripper can integrate a lip that enables it to form a seal and, upon inflating, to generate suction for lifting objects with flat surfaces. The gripper may also be inflated to expand into an opening or orifice for grasping objects with handles or openings. We describe the design and fabrication of this device and present an analytical model of its behavior when operated from a single fluidic port. In experiments, we demonstrate its ability to grasp diverse objects, and show that its performance is well described by our model. Our findings show how a fingerless soft gripper can efficiently perform a variety of grasping operations. Such devices could improve the ability of robotic systems to meet applications in areas of great economic and societal importance.
Towards Real-Time Accurate Object Detection in Both Images and Videos Based on Dual Refinement
Dec 17, 2018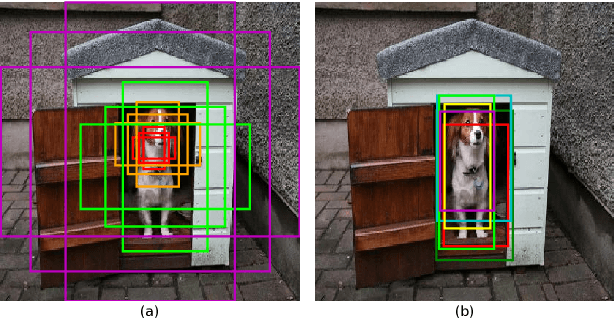
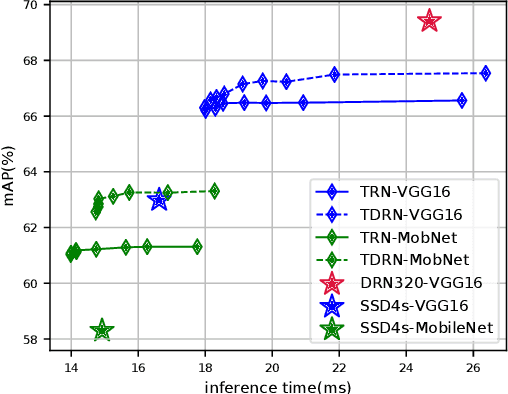

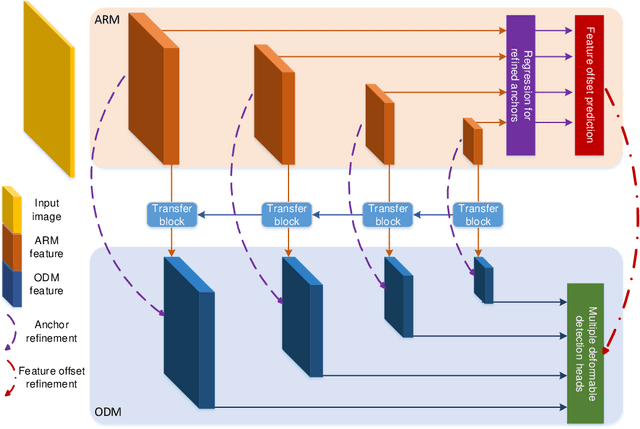
Object detection has been vigorously studied for years but fast accurate detection for real-world applications remains a very challenging problem: i) Most existing methods have either high accuracy or fast speed; ii) Most prior-art approaches focus on static images, ignoring temporal information in real-world scenes. Overcoming drawbacks of single-stage detectors, we take aim at precisely detecting objects in both images and videos in real time. Firstly, as a dual refinement mechanism, a novel anchor-offset detection including an anchor refinement, a feature offset refinement, and a deformable detection head is designed for two-step regression and capturing accurate detection features. Based on the anchor-offset detection, a dual refinement network (DRN) is developed for high-performance static detection, where a multi-deformable head is further designed to leverage contextual information for describing objects. As for video detection, temporal refinement networks (TRN) and temporal dual refinement networks (TDRN) are developed by propagating the refinement information across time. Our proposed methods are evaluated on PASCAL VOC, COCO, and ImageNet VID datasets. Extensive comparison on static and temporal detection validate the superiority of the DRN, TRN and TDRN. Consequently, our developed approaches achieve a significantly enhanced detection accuracy and make prominent progress in accuracy vs. speed trade-off. Codes will be publicly available.
Towards Quality Advancement of Underwater Machine Vision with Generative Adversarial Networks
Jan 16, 2018
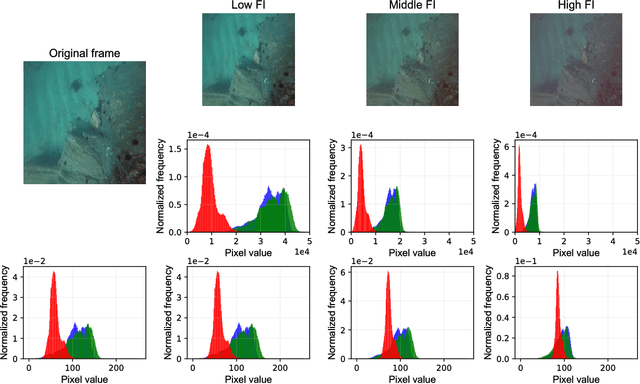
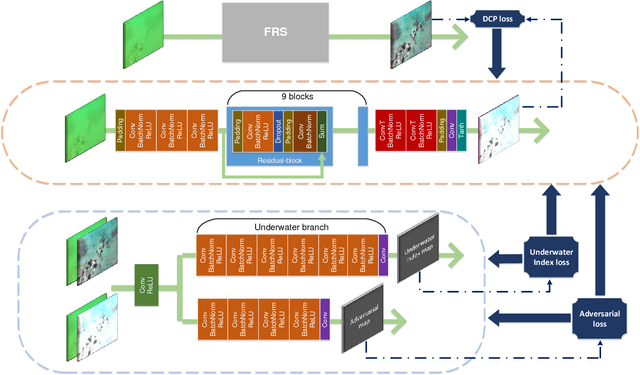
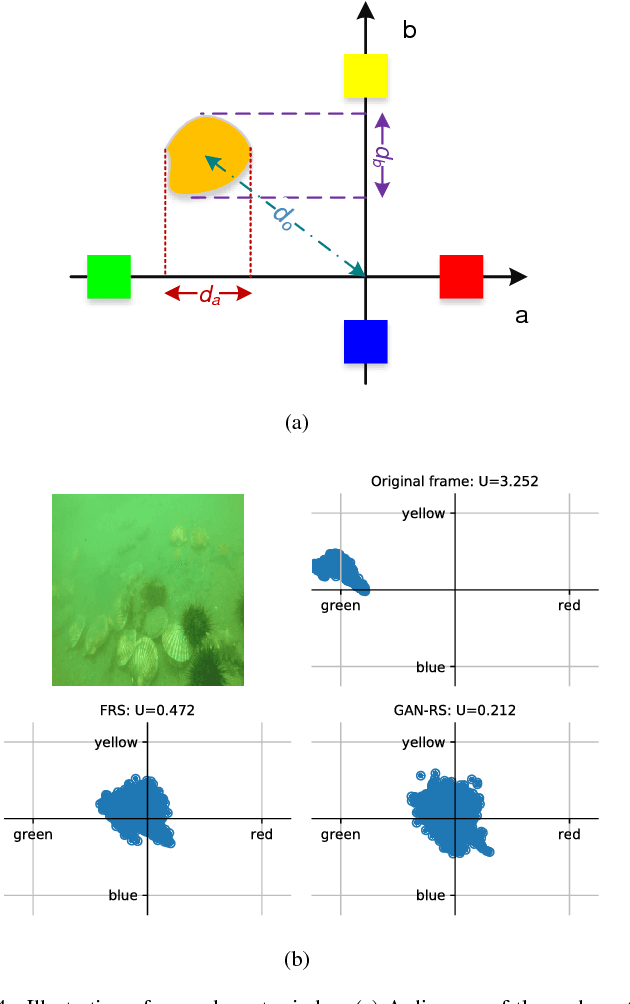
Underwater machine vision has attracted significant attention, but its low quality has prevented it from a wide range of applications. Although many different algorithms have been developed to solve this problem, real-time adaptive methods are frequently deficient. In this paper, based on filtering and the use of generative adversarial networks (GANs), two approaches are proposed for the aforementioned issue, i.e., a filtering-based restoration scheme (FRS) and a GAN-based restoration scheme (GAN-RS). Distinct from previous methods, FRS restores underwater images in the Fourier domain, which is composed of a parameter search, filtering, and enhancement. Aiming to further improve the image quality, GAN-RS can adaptively restore underwater machine vision in real time without the need for pretreatment. In particular, information in the Lab color space and the dark channel is developed as loss functions, namely, underwater index loss and dark channel prior loss, respectively. More specifically, learning from the underwater index, the discriminator is equipped with a carefully crafted underwater branch to predict the underwater probability of an image. A multi-stage loss strategy is then developed to guarantee the effective training of GANs. Through extensive comparisons on the image quality and applications, the superiority of the proposed approaches is confirmed. Consequently, the GAN-RS is considerably faster and achieves a state-of-the-art performance in terms of the color correction, contrast stretch, dehazing, and feature restoration of various underwater scenes. The source code will be made available.