 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreference Aligned Diffusion Planner for Quadrupedal Locomotion Control
Oct 17, 2024



Diffusion models demonstrate superior performance in capturing complex distributions from large-scale datasets, providing a promising solution for quadrupedal locomotion control. However, offline policy is sensitive to Out-of-Distribution (OOD) states due to the limited state coverage in the datasets. In this work, we propose a two-stage learning framework combining offline learning and online preference alignment for legged locomotion control. Through the offline stage, the diffusion planner learns the joint distribution of state-action sequences from expert datasets without using reward labels. Subsequently, we perform the online interaction in the simulation environment based on the trained offline planer, which significantly addresses the OOD issues and improves the robustness. Specifically, we propose a novel weak preference labeling method without the ground-truth reward or human preferences. The proposed method exhibits superior stability and velocity tracking accuracy in pacing, trotting, and bounding gait under both slow- and high-speed scenarios and can perform zero-shot transfer to the real Unitree Go1 robots. The project website for this paper is at https://shangjaven.github.io/preference-aligned-diffusion-legged/.
Task-agnostic Pre-training and Task-guided Fine-tuning for Versatile Diffusion Planner
Sep 30, 2024



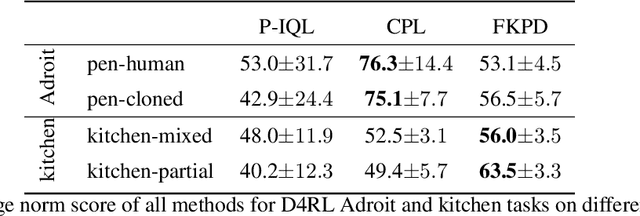
Diffusion models have demonstrated their capabilities in modeling trajectories of multi-tasks. However, existing multi-task planners or policies typically rely on task-specific demonstrations via multi-task imitation, or require task-specific reward labels to facilitate policy optimization via Reinforcement Learning (RL). To address these challenges, we aim to develop a versatile diffusion planner that can leverage large-scale inferior data that contains task-agnostic sub-optimal trajectories, with the ability to fast adapt to specific tasks. In this paper, we propose \textbf{SODP}, a two-stage framework that leverages \textbf{S}ub-\textbf{O}ptimal data to learn a \textbf{D}iffusion \textbf{P}lanner, which is generalizable for various downstream tasks. Specifically, in the pre-training stage, we train a foundation diffusion planner that extracts general planning capabilities by modeling the versatile distribution of multi-task trajectories, which can be sub-optimal and has wide data coverage. Then for downstream tasks, we adopt RL-based fine-tuning with task-specific rewards to fast refine the diffusion planner, which aims to generate action sequences with higher task-specific returns. Experimental results from multi-task domains including Meta-World and Adroit demonstrate that SODP outperforms state-of-the-art methods with only a small amount of data for reward-guided fine-tuning.
Forward KL Regularized Preference Optimization for Aligning Diffusion Policies
Sep 09, 2024
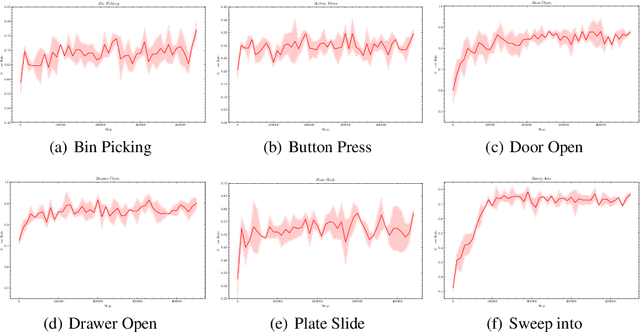
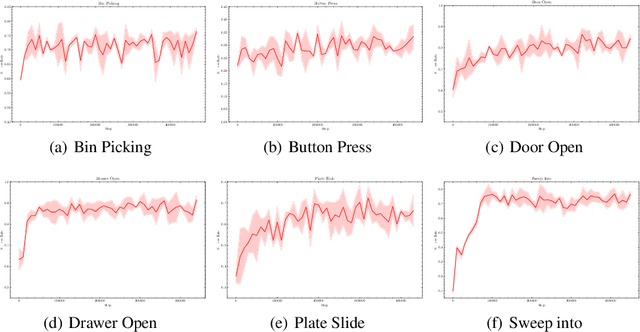
Diffusion models have achieved remarkable success in sequential decision-making by leveraging the highly expressive model capabilities in policy learning. A central problem for learning diffusion policies is to align the policy output with human intents in various tasks. To achieve this, previous methods conduct return-conditioned policy generation or Reinforcement Learning (RL)-based policy optimization, while they both rely on pre-defined reward functions. In this work, we propose a novel framework, Forward KL regularized Preference optimization for aligning Diffusion policies, to align the diffusion policy with preferences directly. We first train a diffusion policy from the offline dataset without considering the preference, and then align the policy to the preference data via direct preference optimization. During the alignment phase, we formulate direct preference learning in a diffusion policy, where the forward KL regularization is employed in preference optimization to avoid generating out-of-distribution actions. We conduct extensive experiments for MetaWorld manipulation and D4RL tasks. The results show our method exhibits superior alignment with preferences and outperforms previous state-of-the-art algorithms.
An Advanced Reinforcement Learning Framework for Online Scheduling of Deferrable Workloads in Cloud Computing
Jun 03, 2024
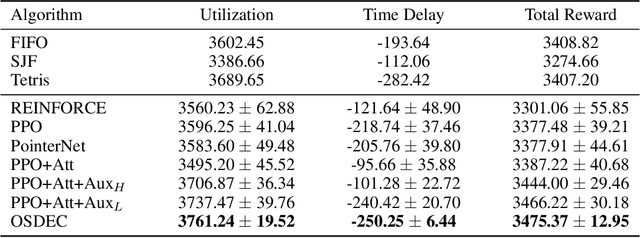
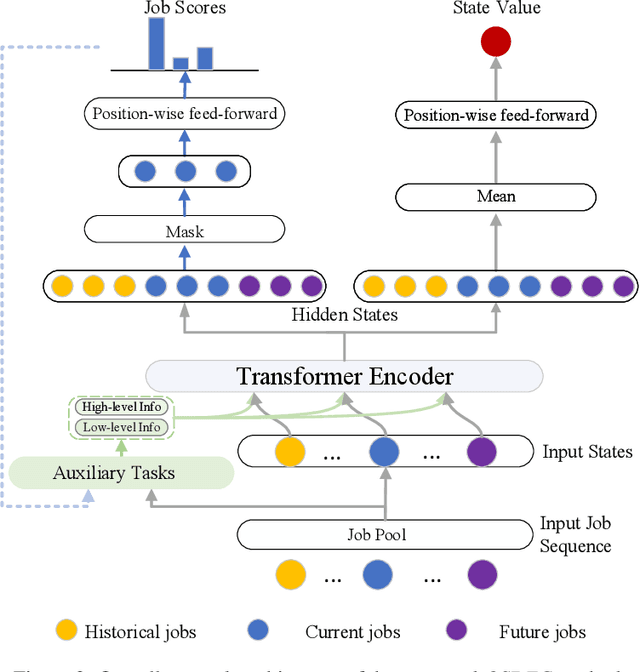
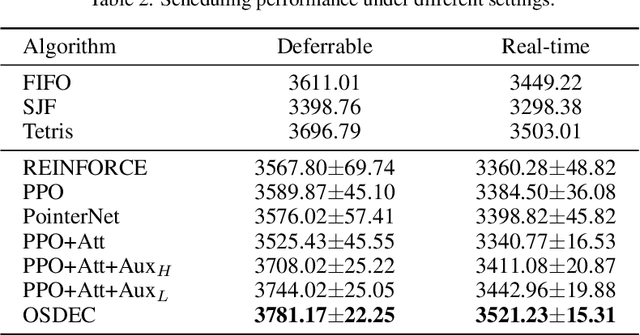
Efficient resource utilization and perfect user experience usually conflict with each other in cloud computing platforms. Great efforts have been invested in increasing resource utilization but trying not to affect users' experience for cloud computing platforms. In order to better utilize the remaining pieces of computing resources spread over the whole platform, deferrable jobs are provided with a discounted price to users. For this type of deferrable jobs, users are allowed to submit jobs that will run for a specific uninterrupted duration in a flexible range of time in the future with a great discount. With these deferrable jobs to be scheduled under the remaining capacity after deploying those on-demand jobs, it remains a challenge to achieve high resource utilization and meanwhile shorten the waiting time for users as much as possible in an online manner. In this paper, we propose an online deferrable job scheduling method called \textit{Online Scheduling for DEferrable jobs in Cloud} (\OSDEC{}), where a deep reinforcement learning model is adopted to learn the scheduling policy, and several auxiliary tasks are utilized to provide better state representations and improve the performance of the model. With the integrated reinforcement learning framework, the proposed method can well plan the deployment schedule and achieve a short waiting time for users while maintaining a high resource utilization for the platform. The proposed method is validated on a public dataset and shows superior performance.
a cognitive frequency allocation strategy for multi-carrier radar against communication interference
Dec 23, 2022



Modern radars often adopt multi-carrier waveform which has been widely discussed in the literature. However, with the development of civil communication, more and more spectrum resource has been occupied by communication networks. Thus, avoiding the interference from communication users is an important and challenging task for the application of multi-carrier radar. In this paper, a novel frequency allocation strategy based on the historical experiences is proposed, which is formulated as a Markov decision process (MDP). In a decision step, the multi-carrier radar needs to choose more than one frequencies, leading to a combinatorial action space. To address this challenge, we use a novel iteratively selecting technique which breaks a difficult decision task into several easy tasks. Moreover, an efficient deep reinforcement learning algorithm is adopted to handle the complicated spectrum dynamics. Numerical results show that our proposed method outperforms the existing ones.