 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKungfuBot: Physics-Based Humanoid Whole-Body Control for Learning Highly-Dynamic Skills
Jun 15, 2025Humanoid robots are promising to acquire various skills by imitating human behaviors. However, existing algorithms are only capable of tracking smooth, low-speed human motions, even with delicate reward and curriculum design. This paper presents a physics-based humanoid control framework, aiming to master highly-dynamic human behaviors such as Kungfu and dancing through multi-steps motion processing and adaptive motion tracking. For motion processing, we design a pipeline to extract, filter out, correct, and retarget motions, while ensuring compliance with physical constraints to the maximum extent. For motion imitation, we formulate a bi-level optimization problem to dynamically adjust the tracking accuracy tolerance based on the current tracking error, creating an adaptive curriculum mechanism. We further construct an asymmetric actor-critic framework for policy training. In experiments, we train whole-body control policies to imitate a set of highly-dynamic motions. Our method achieves significantly lower tracking errors than existing approaches and is successfully deployed on the Unitree G1 robot, demonstrating stable and expressive behaviors. The project page is https://kungfu-bot.github.io.
MoRE: Mixture of Residual Experts for Humanoid Lifelike Gaits Learning on Complex Terrains
Jun 12, 2025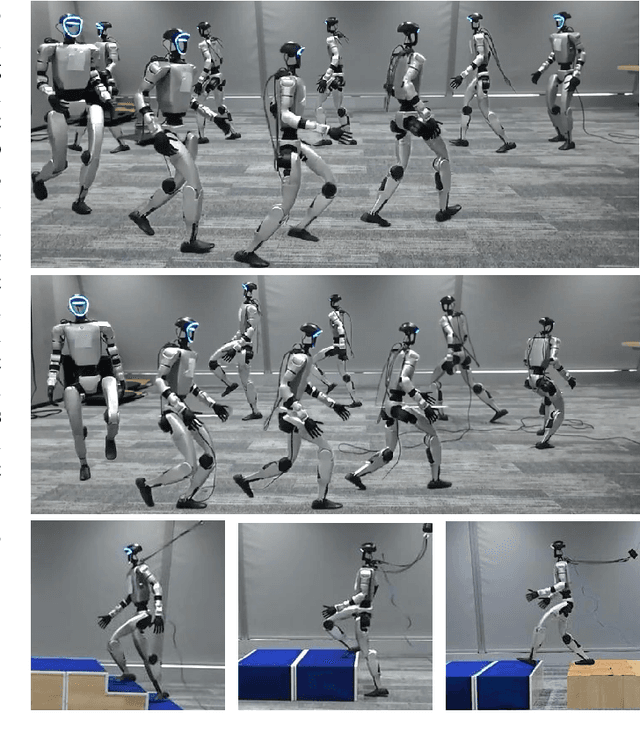
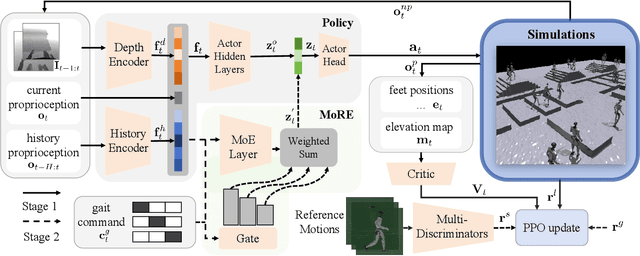
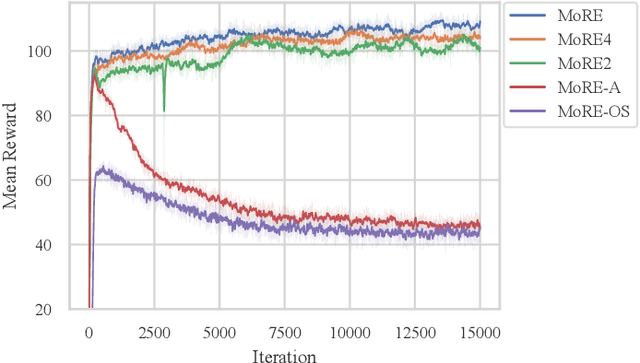
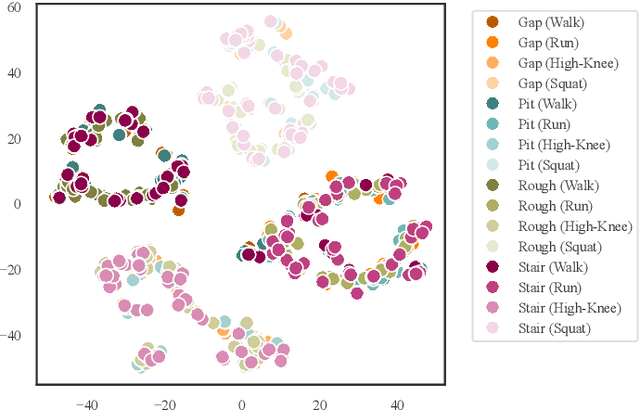
Humanoid robots have demonstrated robust locomotion capabilities using Reinforcement Learning (RL)-based approaches. Further, to obtain human-like behaviors, existing methods integrate human motion-tracking or motion prior in the RL framework. However, these methods are limited in flat terrains with proprioception only, restricting their abilities to traverse challenging terrains with human-like gaits. In this work, we propose a novel framework using a mixture of latent residual experts with multi-discriminators to train an RL policy, which is capable of traversing complex terrains in controllable lifelike gaits with exteroception. Our two-stage training pipeline first teaches the policy to traverse complex terrains using a depth camera, and then enables gait-commanded switching between human-like gait patterns. We also design gait rewards to adjust human-like behaviors like robot base height. Simulation and real-world experiments demonstrate that our framework exhibits exceptional performance in traversing complex terrains, and achieves seamless transitions between multiple human-like gait patterns.
Adversarial Locomotion and Motion Imitation for Humanoid Policy Learning
Apr 19, 2025Humans exhibit diverse and expressive whole-body movements. However, attaining human-like whole-body coordination in humanoid robots remains challenging, as conventional approaches that mimic whole-body motions often neglect the distinct roles of upper and lower body. This oversight leads to computationally intensive policy learning and frequently causes robot instability and falls during real-world execution. To address these issues, we propose Adversarial Locomotion and Motion Imitation (ALMI), a novel framework that enables adversarial policy learning between upper and lower body. Specifically, the lower body aims to provide robust locomotion capabilities to follow velocity commands while the upper body tracks various motions. Conversely, the upper-body policy ensures effective motion tracking when the robot executes velocity-based movements. Through iterative updates, these policies achieve coordinated whole-body control, which can be extended to loco-manipulation tasks with teleoperation systems. Extensive experiments demonstrate that our method achieves robust locomotion and precise motion tracking in both simulation and on the full-size Unitree H1 robot. Additionally, we release a large-scale whole-body motion control dataset featuring high-quality episodic trajectories from MuJoCo simulations deployable on real robots. The project page is https://almi-humanoid.github.io.
Humanoid Whole-Body Locomotion on Narrow Terrain via Dynamic Balance and Reinforcement Learning
Feb 24, 2025Humans possess delicate dynamic balance mechanisms that enable them to maintain stability across diverse terrains and under extreme conditions. However, despite significant advances recently, existing locomotion algorithms for humanoid robots are still struggle to traverse extreme environments, especially in cases that lack external perception (e.g., vision or LiDAR). This is because current methods often rely on gait-based or perception-condition rewards, lacking effective mechanisms to handle unobservable obstacles and sudden balance loss. To address this challenge, we propose a novel whole-body locomotion algorithm based on dynamic balance and Reinforcement Learning (RL) that enables humanoid robots to traverse extreme terrains, particularly narrow pathways and unexpected obstacles, using only proprioception. Specifically, we introduce a dynamic balance mechanism by leveraging an extended measure of Zero-Moment Point (ZMP)-driven rewards and task-driven rewards in a whole-body actor-critic framework, aiming to achieve coordinated actions of the upper and lower limbs for robust locomotion. Experiments conducted on a full-sized Unitree H1-2 robot verify the ability of our method to maintain balance on extremely narrow terrains and under external disturbances, demonstrating its effectiveness in enhancing the robot's adaptability to complex environments. The videos are given at https://whole-body-loco.github.io.
Forward KL Regularized Preference Optimization for Aligning Diffusion Policies
Sep 09, 2024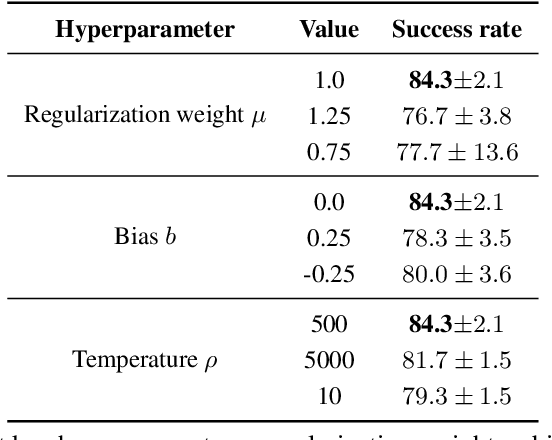
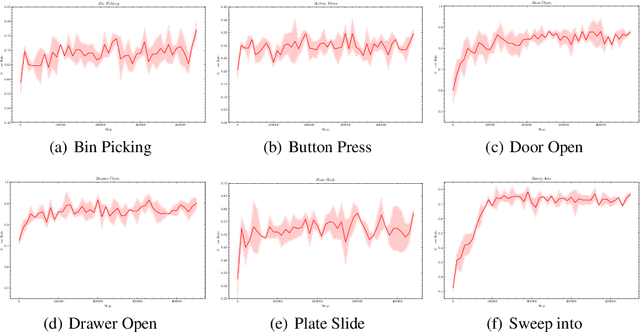
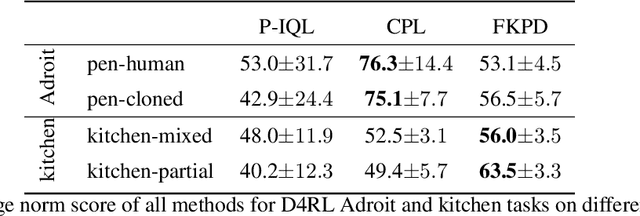
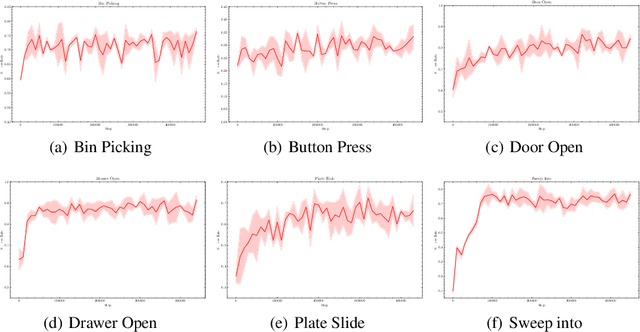
Diffusion models have achieved remarkable success in sequential decision-making by leveraging the highly expressive model capabilities in policy learning. A central problem for learning diffusion policies is to align the policy output with human intents in various tasks. To achieve this, previous methods conduct return-conditioned policy generation or Reinforcement Learning (RL)-based policy optimization, while they both rely on pre-defined reward functions. In this work, we propose a novel framework, Forward KL regularized Preference optimization for aligning Diffusion policies, to align the diffusion policy with preferences directly. We first train a diffusion policy from the offline dataset without considering the preference, and then align the policy to the preference data via direct preference optimization. During the alignment phase, we formulate direct preference learning in a diffusion policy, where the forward KL regularization is employed in preference optimization to avoid generating out-of-distribution actions. We conduct extensive experiments for MetaWorld manipulation and D4RL tasks. The results show our method exhibits superior alignment with preferences and outperforms previous state-of-the-art algorithms.
Robust Quadrupedal Locomotion via Risk-Averse Policy Learning
Sep 01, 2023
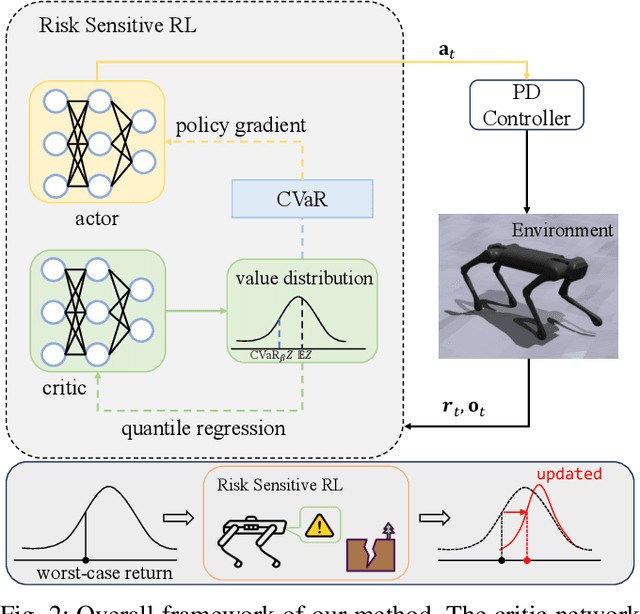
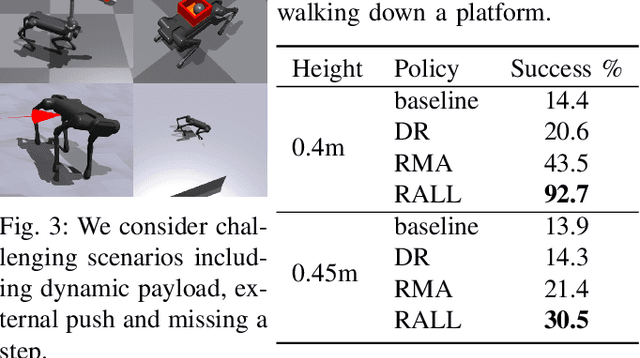

The robustness of legged locomotion is crucial for quadrupedal robots in challenging terrains. Recently, Reinforcement Learning (RL) has shown promising results in legged locomotion and various methods try to integrate privileged distillation, scene modeling, and external sensors to improve the generalization and robustness of locomotion policies. However, these methods are hard to handle uncertain scenarios such as abrupt terrain changes or unexpected external forces. In this paper, we consider a novel risk-sensitive perspective to enhance the robustness of legged locomotion. Specifically, we employ a distributional value function learned by quantile regression to model the aleatoric uncertainty of environments, and perform risk-averse policy learning by optimizing the worst-case scenarios via a risk distortion measure. Extensive experiments in both simulation environments and a real Aliengo robot demonstrate that our method is efficient in handling various external disturbances, and the resulting policy exhibits improved robustness in harsh and uncertain situations in legged locomotion. Videos are available at https://risk-averse-locomotion.github.io/.