 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Reasoning as Trajectories: Step-Specific Representation Geometry and Correctness Signals
Apr 07, 2026This work characterizes large language models' chain-of-thought generation as a structured trajectory through representation space. We show that mathematical reasoning traverses functionally ordered, step-specific subspaces that become increasingly separable with layer depth. This structure already exists in base models, while reasoning training primarily accelerates convergence toward termination-related subspaces rather than introducing new representational organization. While early reasoning steps follow similar trajectories, correct and incorrect solutions diverge systematically at late stages. This late-stage divergence enables mid-reasoning prediction of final-answer correctness with ROC-AUC up to 0.87. Furthermore, we introduce trajectory-based steering, an inference-time intervention framework that enables reasoning correction and length control based on derived ideal trajectories. Together, these results establish reasoning trajectories as a geometric lens for interpreting, predicting, and controlling LLM reasoning behavior.
GUI-360$^\circ$: A Comprehensive Dataset and Benchmark for Computer-Using Agents
Nov 10, 2025We introduce GUI-360$^\circ$, a large-scale, comprehensive dataset and benchmark suite designed to advance computer-using agents (CUAs). CUAs present unique challenges and is constrained by three persistent gaps: a scarcity of real-world CUA tasks, the lack of automated collection-and-annotation pipelines for multi-modal trajectories, and the absence of a unified benchmark that jointly evaluates GUI grounding, screen parsing, and action prediction. GUI-360$^\circ$ addresses these gaps with an LLM-augmented, largely automated pipeline for query sourcing, environment-template construction, task instantiation, batched execution, and LLM-driven quality filtering. The released corpus contains over 1.2M executed action steps across thousands of trajectories in popular Windows office applications, and includes full-resolution screenshots, accessibility metadata when available, instantiated goals, intermediate reasoning traces, and both successful and failed action trajectories. The dataset supports three canonical tasks, GUI grounding, screen parsing, and action prediction, and a hybrid GUI+API action space that reflects modern agent designs. Benchmarking state-of-the-art vision--language models on GUI-360$^\circ$ reveals substantial out-of-the-box shortcomings in grounding and action prediction; supervised fine-tuning and reinforcement learning yield significant gains but do not close the gap to human-level reliability. We release GUI-360$^\circ$ and accompanying code to facilitate reproducible research and accelerate progress on robust desktop CUAs. The full dataset has been made public on https://huggingface.co/datasets/vyokky/GUI-360.
GUI-360: A Comprehensive Dataset and Benchmark for Computer-Using Agents
Nov 06, 2025We introduce GUI-360$^\circ$, a large-scale, comprehensive dataset and benchmark suite designed to advance computer-using agents (CUAs). CUAs present unique challenges and is constrained by three persistent gaps: a scarcity of real-world CUA tasks, the lack of automated collection-and-annotation pipelines for multi-modal trajectories, and the absence of a unified benchmark that jointly evaluates GUI grounding, screen parsing, and action prediction. GUI-360$^\circ$ addresses these gaps with an LLM-augmented, largely automated pipeline for query sourcing, environment-template construction, task instantiation, batched execution, and LLM-driven quality filtering. The released corpus contains over 1.2M executed action steps across thousands of trajectories in popular Windows office applications, and includes full-resolution screenshots, accessibility metadata when available, instantiated goals, intermediate reasoning traces, and both successful and failed action trajectories. The dataset supports three canonical tasks, GUI grounding, screen parsing, and action prediction, and a hybrid GUI+API action space that reflects modern agent designs. Benchmarking state-of-the-art vision--language models on GUI-360$^\circ$ reveals substantial out-of-the-box shortcomings in grounding and action prediction; supervised fine-tuning and reinforcement learning yield significant gains but do not close the gap to human-level reliability. We release GUI-360$^\circ$ and accompanying code to facilitate reproducible research and accelerate progress on robust desktop CUAs. The full dataset has been made public on https://huggingface.co/datasets/vyokky/GUI-360.
Large Action Models: From Inception to Implementation
Dec 13, 2024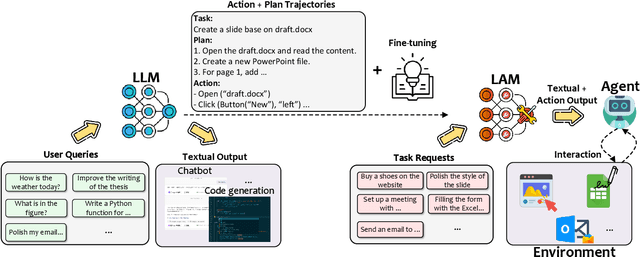

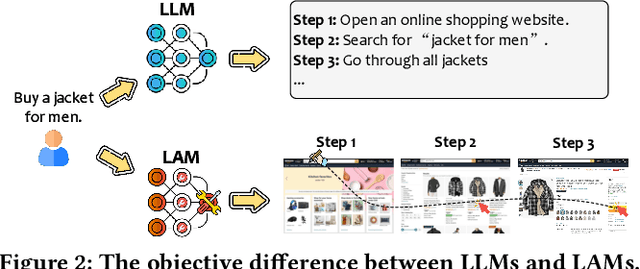

As AI continues to advance, there is a growing demand for systems that go beyond language-based assistance and move toward intelligent agents capable of performing real-world actions. This evolution requires the transition from traditional Large Language Models (LLMs), which excel at generating textual responses, to Large Action Models (LAMs), designed for action generation and execution within dynamic environments. Enabled by agent systems, LAMs hold the potential to transform AI from passive language understanding to active task completion, marking a significant milestone in the progression toward artificial general intelligence. In this paper, we present a comprehensive framework for developing LAMs, offering a systematic approach to their creation, from inception to deployment. We begin with an overview of LAMs, highlighting their unique characteristics and delineating their differences from LLMs. Using a Windows OS-based agent as a case study, we provide a detailed, step-by-step guide on the key stages of LAM development, including data collection, model training, environment integration, grounding, and evaluation. This generalizable workflow can serve as a blueprint for creating functional LAMs in various application domains. We conclude by identifying the current limitations of LAMs and discussing directions for future research and industrial deployment, emphasizing the challenges and opportunities that lie ahead in realizing the full potential of LAMs in real-world applications. The code for the data collection process utilized in this paper is publicly available at: https://github.com/microsoft/UFO/tree/main/dataflow, and comprehensive documentation can be found at https://microsoft.github.io/UFO/dataflow/overview/.
An Advanced Reinforcement Learning Framework for Online Scheduling of Deferrable Workloads in Cloud Computing
Jun 03, 2024
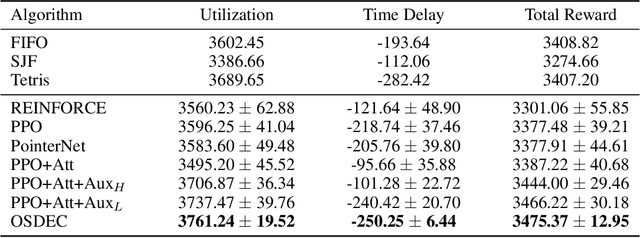
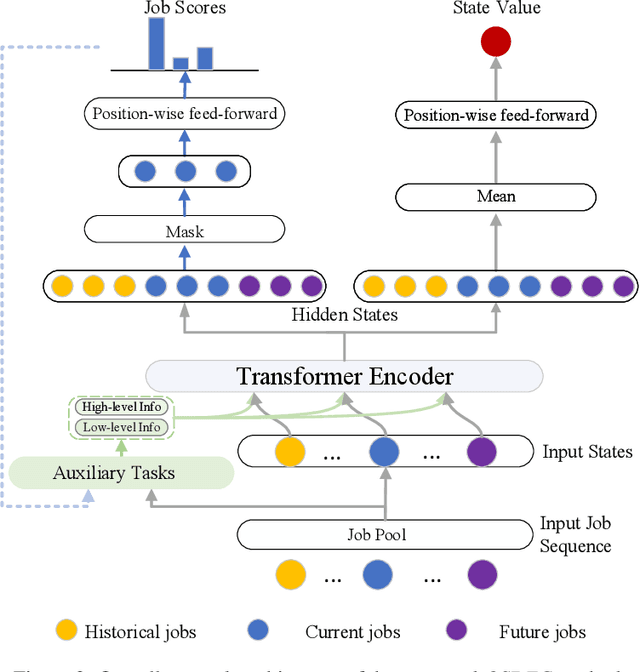
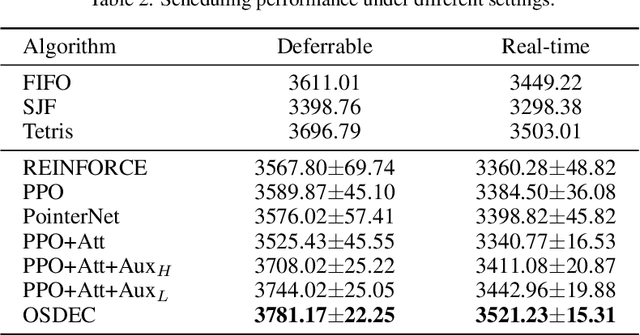
Efficient resource utilization and perfect user experience usually conflict with each other in cloud computing platforms. Great efforts have been invested in increasing resource utilization but trying not to affect users' experience for cloud computing platforms. In order to better utilize the remaining pieces of computing resources spread over the whole platform, deferrable jobs are provided with a discounted price to users. For this type of deferrable jobs, users are allowed to submit jobs that will run for a specific uninterrupted duration in a flexible range of time in the future with a great discount. With these deferrable jobs to be scheduled under the remaining capacity after deploying those on-demand jobs, it remains a challenge to achieve high resource utilization and meanwhile shorten the waiting time for users as much as possible in an online manner. In this paper, we propose an online deferrable job scheduling method called \textit{Online Scheduling for DEferrable jobs in Cloud} (\OSDEC{}), where a deep reinforcement learning model is adopted to learn the scheduling policy, and several auxiliary tasks are utilized to provide better state representations and improve the performance of the model. With the integrated reinforcement learning framework, the proposed method can well plan the deployment schedule and achieve a short waiting time for users while maintaining a high resource utilization for the platform. The proposed method is validated on a public dataset and shows superior performance.
Verco: Learning Coordinated Verbal Communication for Multi-agent Reinforcement Learning
Apr 27, 2024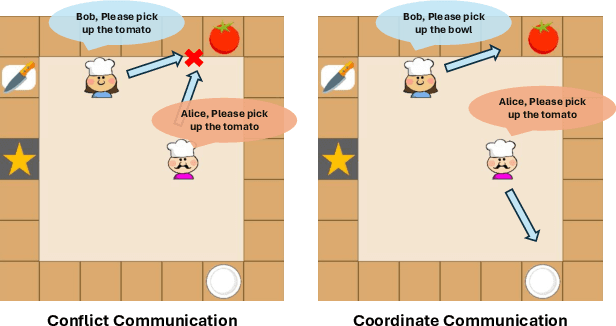
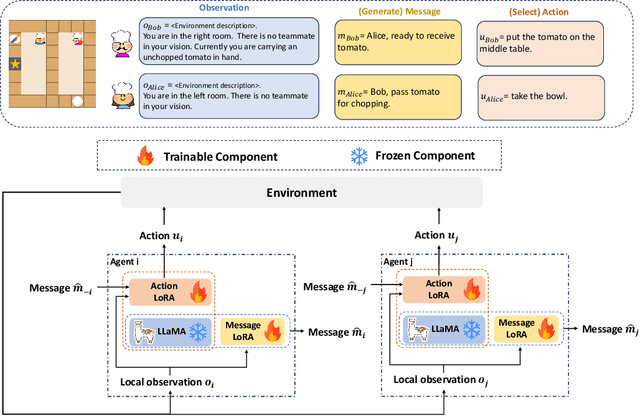
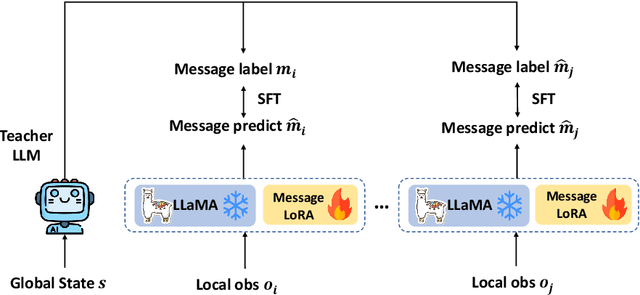
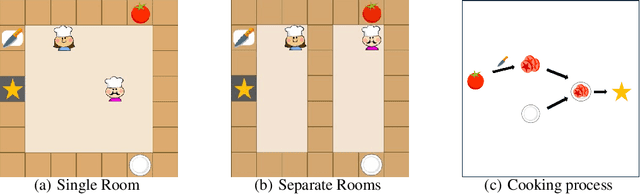
In recent years, multi-agent reinforcement learning algorithms have made significant advancements in diverse gaming environments, leading to increased interest in the broader application of such techniques. To address the prevalent challenge of partial observability, communication-based algorithms have improved cooperative performance through the sharing of numerical embedding between agents. However, the understanding of the formation of collaborative mechanisms is still very limited, making designing a human-understandable communication mechanism a valuable problem to address. In this paper, we propose a novel multi-agent reinforcement learning algorithm that embeds large language models into agents, endowing them with the ability to generate human-understandable verbal communication. The entire framework has a message module and an action module. The message module is responsible for generating and sending verbal messages to other agents, effectively enhancing information sharing among agents. To further enhance the message module, we employ a teacher model to generate message labels from the global view and update the student model through Supervised Fine-Tuning (SFT). The action module receives messages from other agents and selects actions based on current local observations and received messages. Experiments conducted on the Overcooked game demonstrate our method significantly enhances the learning efficiency and performance of existing methods, while also providing an interpretable tool for humans to understand the process of multi-agent cooperation.
UFO: A UI-Focused Agent for Windows OS Interaction
Feb 23, 2024



We introduce UFO, an innovative UI-Focused agent to fulfill user requests tailored to applications on Windows OS, harnessing the capabilities of GPT-Vision. UFO employs a dual-agent framework to meticulously observe and analyze the graphical user interface (GUI) and control information of Windows applications. This enables the agent to seamlessly navigate and operate within individual applications and across them to fulfill user requests, even when spanning multiple applications. The framework incorporates a control interaction module, facilitating action grounding without human intervention and enabling fully automated execution. Consequently, UFO transforms arduous and time-consuming processes into simple tasks achievable solely through natural language commands. We conducted testing of UFO across 9 popular Windows applications, encompassing a variety of scenarios reflective of users' daily usage. The results, derived from both quantitative metrics and real-case studies, underscore the superior effectiveness of UFO in fulfilling user requests. To the best of our knowledge, UFO stands as the first UI agent specifically tailored for task completion within the Windows OS environment. The open-source code for UFO is available on https://github.com/microsoft/UFO.
COIN: Chance-Constrained Imitation Learning for Uncertainty-aware Adaptive Resource Oversubscription Policy
Jan 13, 2024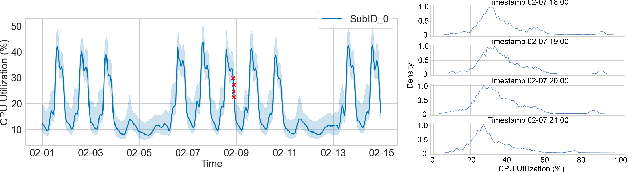
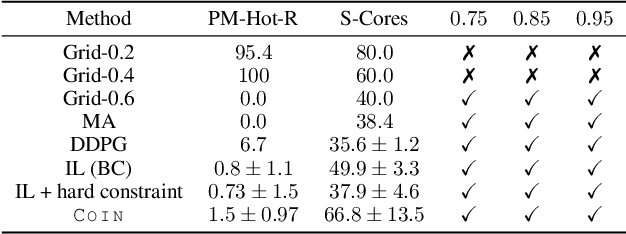
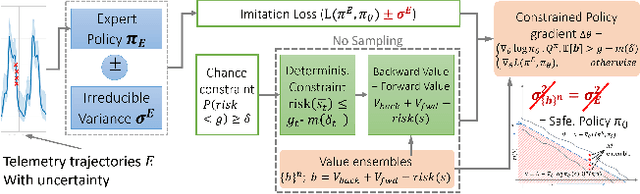
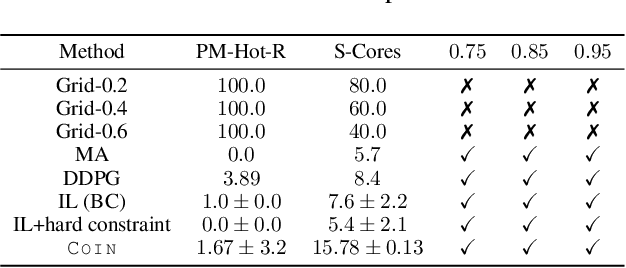
We address the challenge of learning safe and robust decision policies in presence of uncertainty in context of the real scientific problem of adaptive resource oversubscription to enhance resource efficiency while ensuring safety against resource congestion risk. Traditional supervised prediction or forecasting models are ineffective in learning adaptive policies whereas standard online optimization or reinforcement learning is difficult to deploy on real systems. Offline methods such as imitation learning (IL) are ideal since we can directly leverage historical resource usage telemetry. But, the underlying aleatoric uncertainty in such telemetry is a critical bottleneck. We solve this with our proposed novel chance-constrained imitation learning framework, which ensures implicit safety against uncertainty in a principled manner via a combination of stochastic (chance) constraints on resource congestion risk and ensemble value functions. This leads to substantial ($\approx 3-4\times$) improvement in resource efficiency and safety in many oversubscription scenarios, including resource management in cloud services.
Contrastive Learning with Negative Sampling Correction
Jan 13, 2024As one of the most effective self-supervised representation learning methods, contrastive learning (CL) relies on multiple negative pairs to contrast against each positive pair. In the standard practice of contrastive learning, data augmentation methods are utilized to generate both positive and negative pairs. While existing works have been focusing on improving the positive sampling, the negative sampling process is often overlooked. In fact, the generated negative samples are often polluted by positive samples, which leads to a biased loss and performance degradation. To correct the negative sampling bias, we propose a novel contrastive learning method named Positive-Unlabeled Contrastive Learning (PUCL). PUCL treats the generated negative samples as unlabeled samples and uses information from positive samples to correct bias in contrastive loss. We prove that the corrected loss used in PUCL only incurs a negligible bias compared to the unbiased contrastive loss. PUCL can be applied to general contrastive learning problems and outperforms state-of-the-art methods on various image and graph classification tasks. The code of PUCL is in the supplementary file.
TaskWeaver: A Code-First Agent Framework
Dec 01, 2023
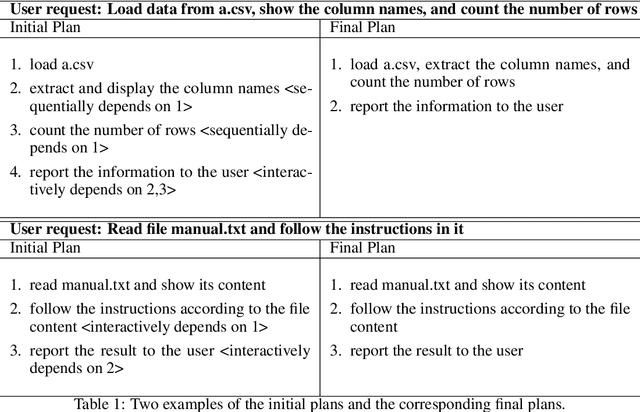
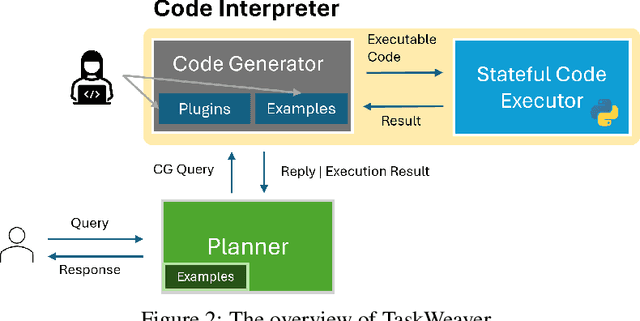
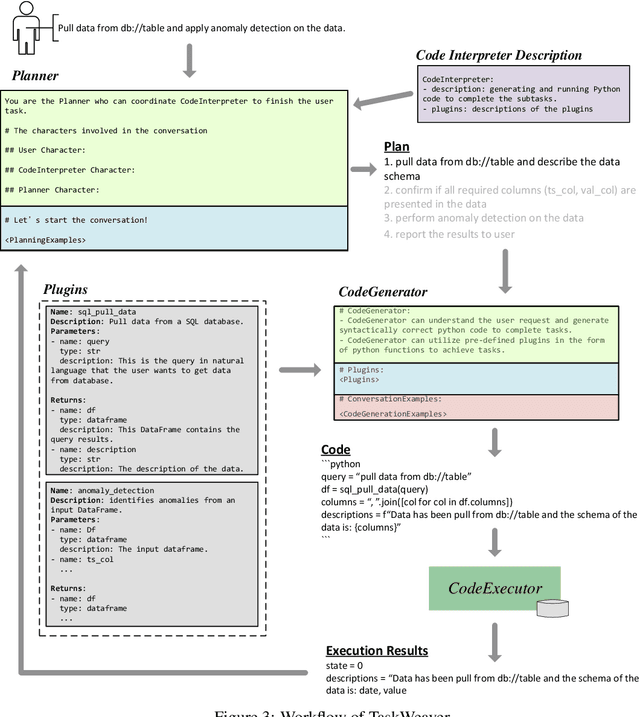
Large Language Models (LLMs) have shown impressive abilities in natural language understanding and generation, leading to their use in applications such as chatbots and virtual assistants. However, existing LLM frameworks face limitations in handling domain-specific data analytics tasks with rich data structures. Moreover, they struggle with flexibility to meet diverse user requirements. To address these issues, TaskWeaver is proposed as a code-first framework for building LLM-powered autonomous agents. It converts user requests into executable code and treats user-defined plugins as callable functions. TaskWeaver provides support for rich data structures, flexible plugin usage, and dynamic plugin selection, and leverages LLM coding capabilities for complex logic. It also incorporates domain-specific knowledge through examples and ensures the secure execution of generated code. TaskWeaver offers a powerful and flexible framework for creating intelligent conversational agents that can handle complex tasks and adapt to domain-specific scenarios. The code is open-sourced at https://github.com/microsoft/TaskWeaver/.