 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Advanced Reinforcement Learning Framework for Online Scheduling of Deferrable Workloads in Cloud Computing
Jun 03, 2024
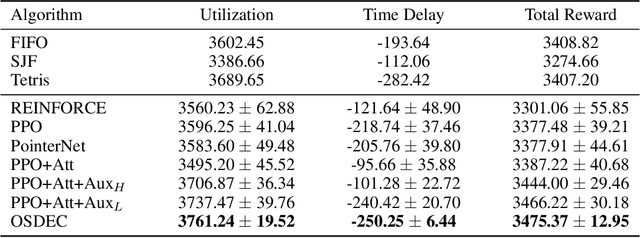
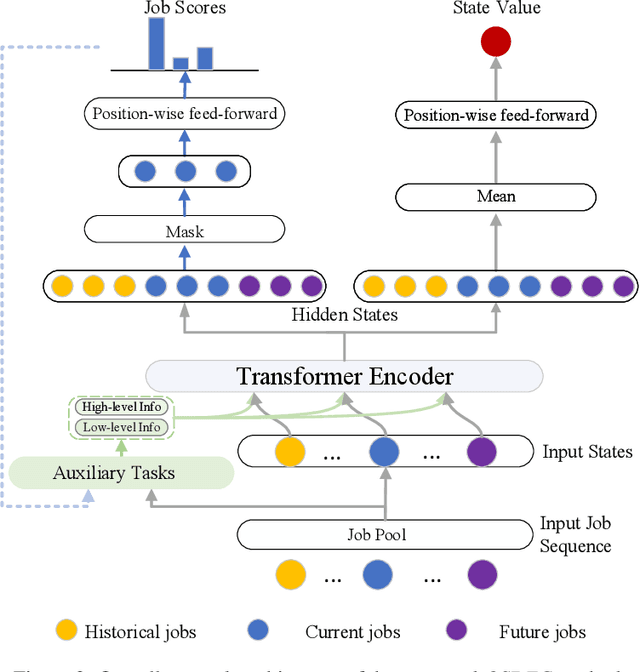
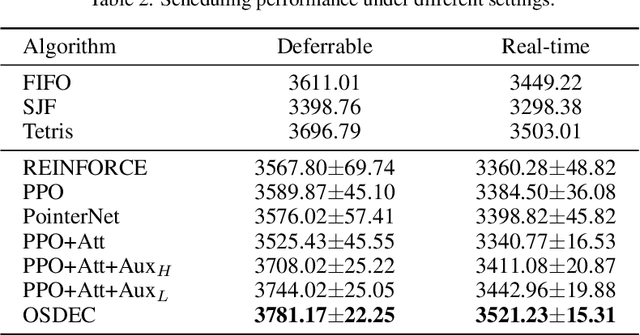
Efficient resource utilization and perfect user experience usually conflict with each other in cloud computing platforms. Great efforts have been invested in increasing resource utilization but trying not to affect users' experience for cloud computing platforms. In order to better utilize the remaining pieces of computing resources spread over the whole platform, deferrable jobs are provided with a discounted price to users. For this type of deferrable jobs, users are allowed to submit jobs that will run for a specific uninterrupted duration in a flexible range of time in the future with a great discount. With these deferrable jobs to be scheduled under the remaining capacity after deploying those on-demand jobs, it remains a challenge to achieve high resource utilization and meanwhile shorten the waiting time for users as much as possible in an online manner. In this paper, we propose an online deferrable job scheduling method called \textit{Online Scheduling for DEferrable jobs in Cloud} (\OSDEC{}), where a deep reinforcement learning model is adopted to learn the scheduling policy, and several auxiliary tasks are utilized to provide better state representations and improve the performance of the model. With the integrated reinforcement learning framework, the proposed method can well plan the deployment schedule and achieve a short waiting time for users while maintaining a high resource utilization for the platform. The proposed method is validated on a public dataset and shows superior performance.
Federated Multi-Task Learning on Non-IID Data Silos: An Experimental Study
Feb 20, 2024



The innovative Federated Multi-Task Learning (FMTL) approach consolidates the benefits of Federated Learning (FL) and Multi-Task Learning (MTL), enabling collaborative model training on multi-task learning datasets. However, a comprehensive evaluation method, integrating the unique features of both FL and MTL, is currently absent in the field. This paper fills this void by introducing a novel framework, FMTL-Bench, for systematic evaluation of the FMTL paradigm. This benchmark covers various aspects at the data, model, and optimization algorithm levels, and comprises seven sets of comparative experiments, encapsulating a wide array of non-independent and identically distributed (Non-IID) data partitioning scenarios. We propose a systematic process for comparing baselines of diverse indicators and conduct a case study on communication expenditure, time, and energy consumption. Through our exhaustive experiments, we aim to provide valuable insights into the strengths and limitations of existing baseline methods, contributing to the ongoing discourse on optimal FMTL application in practical scenarios. The source code will be made available for results replication.
Towards Hetero-Client Federated Multi-Task Learning
Nov 22, 2023
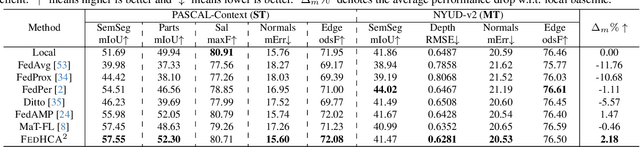


Federated Learning (FL) enables joint training across distributed clients using their local data privately. Federated Multi-Task Learning (FMTL) builds on FL to handle multiple tasks, assuming model congruity that identical model architecture is deployed in each client. To relax this assumption and thus extend real-world applicability, we introduce a novel problem setting, Hetero-Client Federated Multi-Task Learning (HC-FMTL), to accommodate diverse task setups. The main challenge of HC-FMTL is the model incongruity issue that invalidates conventional aggregation methods. It also escalates the difficulties in accurate model aggregation to deal with data and task heterogeneity inherent in FMTL. To address these challenges, we propose the FedHCA$^2$ framework, which allows for federated training of personalized models by modeling relationships among heterogeneous clients. Drawing on our theoretical insights into the difference between multi-task and federated optimization, we propose the Hyper Conflict-Averse Aggregation scheme to mitigate conflicts during encoder updates. Additionally, inspired by task interaction in MTL, the Hyper Cross Attention Aggregation scheme uses layer-wise cross attention to enhance decoder interactions while alleviating model incongruity. Moreover, we employ learnable Hyper Aggregation Weights for each client to customize personalized parameter updates. Extensive experiments demonstrate the superior performance of FedHCA$^2$ in various HC-FMTL scenarios compared to representative methods. Our code will be made publicly available.
UNIDEAL: Curriculum Knowledge Distillation Federated Learning
Sep 16, 2023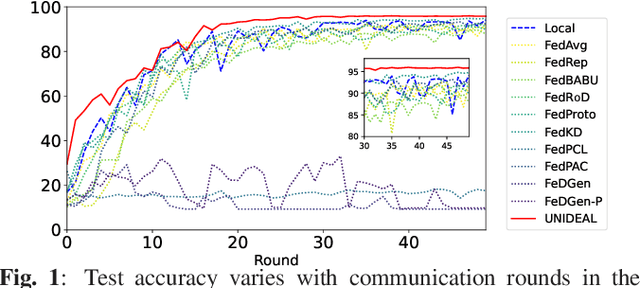
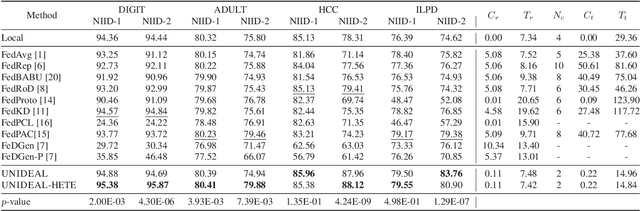

Federated Learning (FL) has emerged as a promising approach to enable collaborative learning among multiple clients while preserving data privacy. However, cross-domain FL tasks, where clients possess data from different domains or distributions, remain a challenging problem due to the inherent heterogeneity. In this paper, we present UNIDEAL, a novel FL algorithm specifically designed to tackle the challenges of cross-domain scenarios and heterogeneous model architectures. The proposed method introduces Adjustable Teacher-Student Mutual Evaluation Curriculum Learning, which significantly enhances the effectiveness of knowledge distillation in FL settings. We conduct extensive experiments on various datasets, comparing UNIDEAL with state-of-the-art baselines. Our results demonstrate that UNIDEAL achieves superior performance in terms of both model accuracy and communication efficiency. Additionally, we provide a convergence analysis of the algorithm, showing a convergence rate of O(1/T) under non-convex conditions.
Environment Semantics Aided Wireless Communications: A Case Study of mmWave Beam Prediction and Blockage Prediction
Jan 14, 2023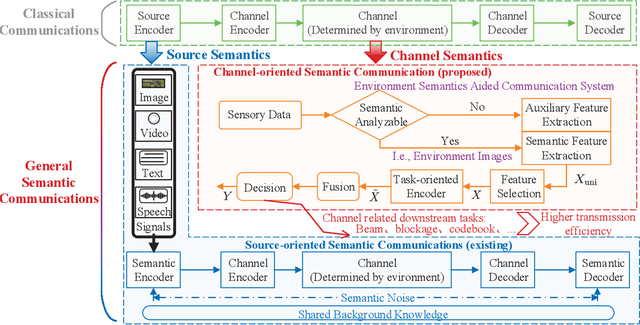
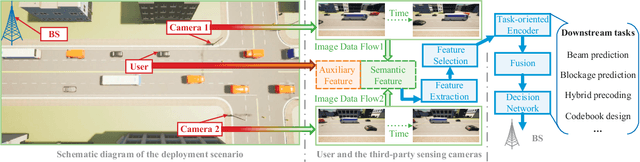
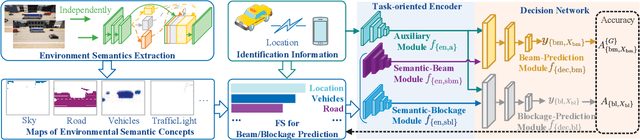

In this paper, we propose an environment semantics aided wireless communication framework to reduce the transmission latency and improve the transmission reliability, where semantic information is extracted from environment image data, selectively encoded based on its task-relevance, and then fused to make decisions for channel related tasks. As a case study, we develop an environment semantics aided network architecture for mmWave communication systems, which is composed of a semantic feature extraction network, a feature selection algorithm, a task-oriented encoder, and a decision network. With images taken from street cameras and user's identification information as the inputs, the environment semantics aided network architecture is trained to predict the optimal beam index and the blockage state for the base station. It is seen that without pilot training or the costly beam scans, the environment semantics aided network architecture can realize extremely efficient beam prediction and timely blockage prediction, thus meeting requirements for ultra-reliable and low-latency communications (URLLCs). Simulation results demonstrate that compared with existing works, the proposed environment semantics aided network architecture can reduce system overheads such as storage space and computational cost while achieving satisfactory prediction accuracy and protecting user privacy.
EDEN: A Plug-in Equivariant Distance Encoding to Beyond the 1-WL Test
Nov 19, 2022



The message-passing scheme is the core of graph representation learning. While most existing message-passing graph neural networks (MPNNs) are permutation-invariant in graph-level representation learning and permutation-equivariant in node- and edge-level representation learning, their expressive power is commonly limited by the 1-Weisfeiler-Lehman (1-WL) graph isomorphism test. Recently proposed expressive graph neural networks (GNNs) with specially designed complex message-passing mechanisms are not practical. To bridge the gap, we propose a plug-in Equivariant Distance ENcoding (EDEN) for MPNNs. EDEN is derived from a series of interpretable transformations on the graph's distance matrix. We theoretically prove that EDEN is permutation-equivariant for all level graph representation learning, and we empirically illustrate that EDEN's expressive power can reach up to the 3-WL test. Extensive experiments on real-world datasets show that combining EDEN with conventional GNNs surpasses recent advanced GNNs.
Position-Aware Subgraph Neural Networks with Data-Efficient Learning
Nov 01, 2022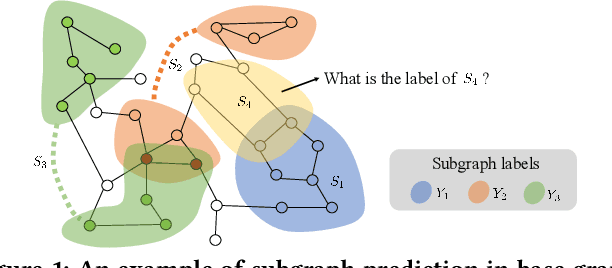
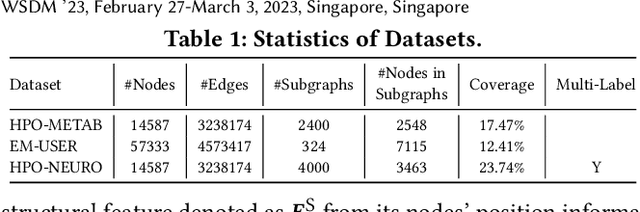
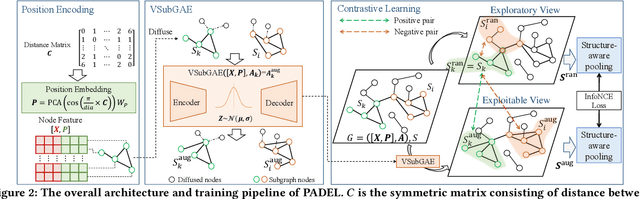
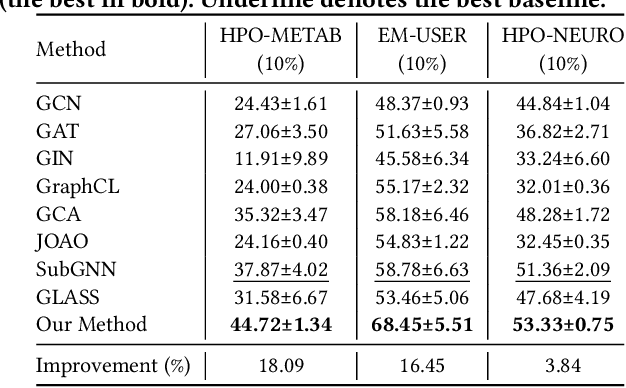
Data-efficient learning on graphs (GEL) is essential in real-world applications. Existing GEL methods focus on learning useful representations for nodes, edges, or entire graphs with ``small'' labeled data. But the problem of data-efficient learning for subgraph prediction has not been explored. The challenges of this problem lie in the following aspects: 1) It is crucial for subgraphs to learn positional features to acquire structural information in the base graph in which they exist. Although the existing subgraph neural network method is capable of learning disentangled position encodings, the overall computational complexity is very high. 2) Prevailing graph augmentation methods for GEL, including rule-based, sample-based, adaptive, and automated methods, are not suitable for augmenting subgraphs because a subgraph contains fewer nodes but richer information such as position, neighbor, and structure. Subgraph augmentation is more susceptible to undesirable perturbations. 3) Only a small number of nodes in the base graph are contained in subgraphs, which leads to a potential ``bias'' problem that the subgraph representation learning is dominated by these ``hot'' nodes. By contrast, the remaining nodes fail to be fully learned, which reduces the generalization ability of subgraph representation learning. In this paper, we aim to address the challenges above and propose a Position-Aware Data-Efficient Learning framework for subgraph neural networks called PADEL. Specifically, we propose a novel node position encoding method that is anchor-free, and design a new generative subgraph augmentation method based on a diffused variational subgraph autoencoder, and we propose exploratory and exploitable views for subgraph contrastive learning. Extensive experiment results on three real-world datasets show the superiority of our proposed method over state-of-the-art baselines.
Completely Heterogeneous Federated Learning
Oct 28, 2022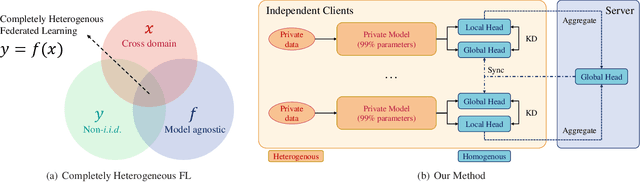
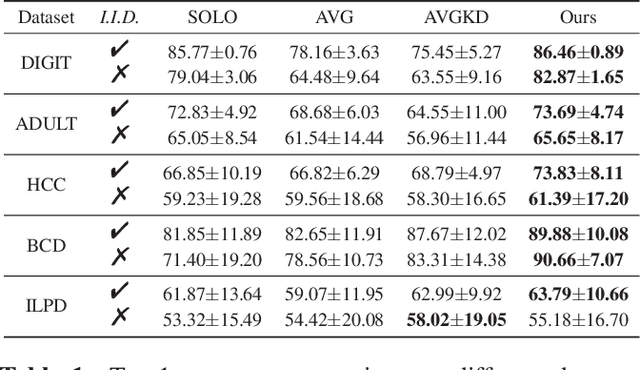

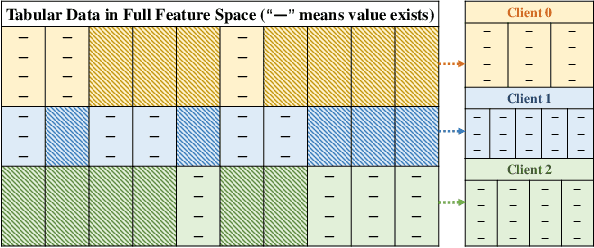
Federated learning (FL) faces three major difficulties: cross-domain, heterogeneous models, and non-i.i.d. labels scenarios. Existing FL methods fail to handle the above three constraints at the same time, and the level of privacy protection needs to be lowered (e.g., the model architecture and data category distribution can be shared). In this work, we propose the challenging "completely heterogeneous" scenario in FL, which refers to that each client will not expose any private information including feature space, model architecture, and label distribution. We then devise an FL framework based on parameter decoupling and data-free knowledge distillation to solve the problem. Experiments show that our proposed method achieves high performance in completely heterogeneous scenarios where other approaches fail.
NoMorelization: Building Normalizer-Free Models from a Sample's Perspective
Oct 13, 2022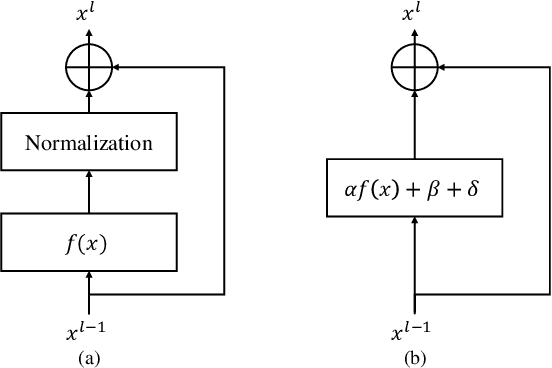
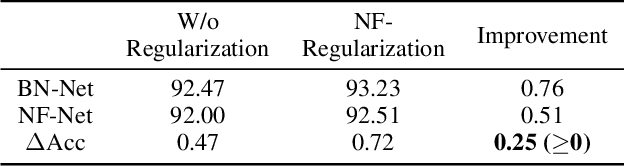
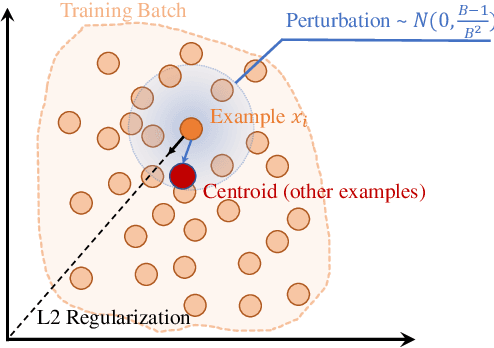
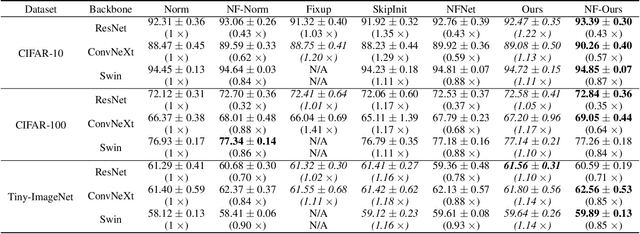
The normalizing layer has become one of the basic configurations of deep learning models, but it still suffers from computational inefficiency, interpretability difficulties, and low generality. After gaining a deeper understanding of the recent normalization and normalizer-free research works from a sample's perspective, we reveal the fact that the problem lies in the sampling noise and the inappropriate prior assumption. In this paper, we propose a simple and effective alternative to normalization, which is called "NoMorelization". NoMorelization is composed of two trainable scalars and a zero-centered noise injector. Experimental results demonstrate that NoMorelization is a general component for deep learning and is suitable for different model paradigms (e.g., convolution-based and attention-based models) to tackle different tasks (e.g., discriminative and generative tasks). Compared with existing mainstream normalizers (e.g., BN, LN, and IN) and state-of-the-art normalizer-free methods, NoMorelization shows the best speed-accuracy trade-off.
Federated Dynamic Neural Network for Deep MIMO Detection
Nov 24, 2021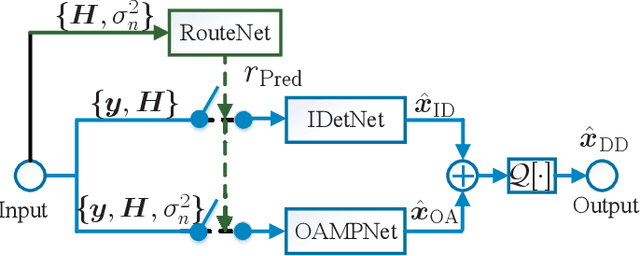


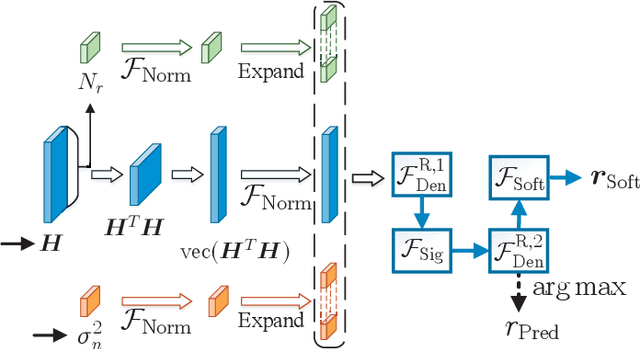
In this paper, we develop a dynamic detection network (DDNet) based detector for multiple-input multiple-output (MIMO) systems. By constructing an improved DetNet (IDetNet) detector and the OAMPNet detector as two independent network branches, the DDNet detector performs sample-wise dynamic routing to adaptively select a better one between the IDetNet and the OAMPNet detectors for every samples under different system conditions. To avoid the prohibitive transmission overhead of dataset collection in centralized learning (CL), we propose the federated averaging (FedAve)-DDNet detector, where all raw data are kept at local clients and only locally trained model parameters are transmitted to the central server for aggregation. To further reduce the transmission overhead, we develop the federated gradient sparsification (FedGS)-DDNet detector by randomly sampling gradients with elaborately calculated probability when uploading gradients to the central server. Based on simulation results, the proposed DDNet detector consistently outperforms other detectors under all system conditions thanks to the sample-wise dynamic routing. Moreover, the federated DDNet detectors, especially the FedGS-DDNet detector, can reduce the transmission overhead by at least 25.7\% while maintaining satisfactory detection accuracy.