 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene-wise Adaptive Network for Dynamic Cold-start Scenes Optimization in CTR Prediction
Aug 15, 2024
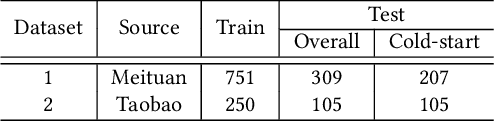
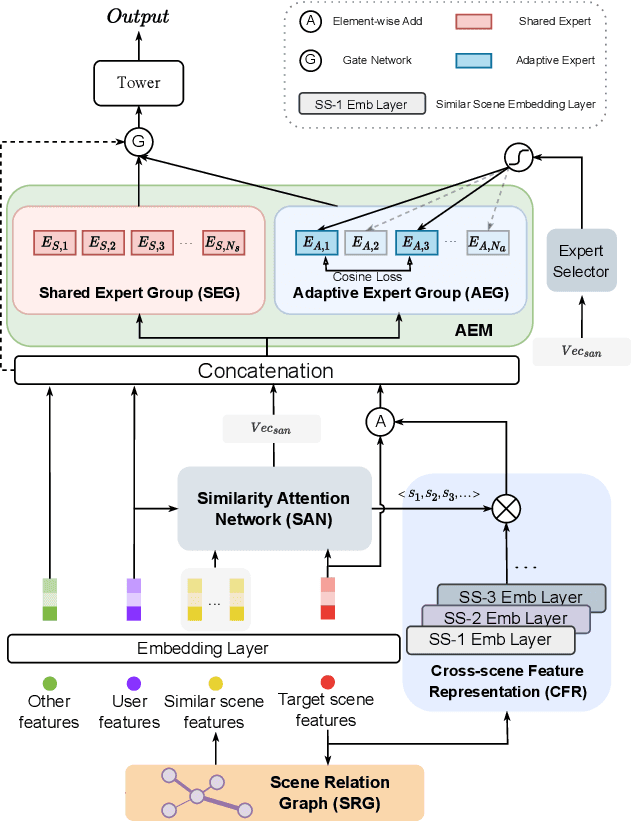
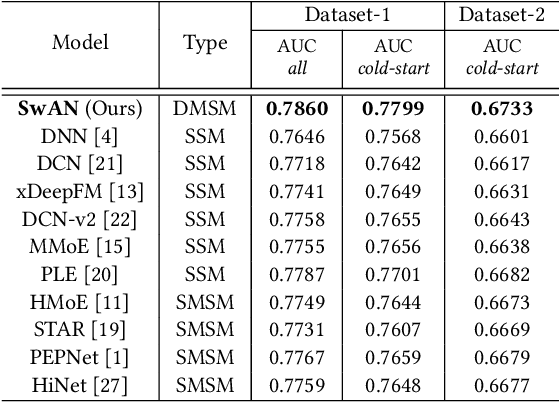
In the realm of modern mobile E-commerce, providing users with nearby commercial service recommendations through location-based online services has become increasingly vital. While machine learning approaches have shown promise in multi-scene recommendation, existing methodologies often struggle to address cold-start problems in unprecedented scenes: the increasing diversity of commercial choices, along with the short online lifespan of scenes, give rise to the complexity of effective recommendations in online and dynamic scenes. In this work, we propose Scene-wise Adaptive Network (SwAN), a novel approach that emphasizes high-performance cold-start online recommendations for new scenes. Our approach introduces several crucial capabilities, including scene similarity learning, user-specific scene transition cognition, scene-specific information construction for the new scene, and enhancing the diverged logical information between scenes. We demonstrate SwAN's potential to optimize dynamic multi-scene recommendation problems by effectively online handling cold-start recommendations for any newly arrived scenes. More encouragingly, SwAN has been successfully deployed in Meituan's online catering recommendation service, which serves millions of customers per day, and SwAN has achieved a 5.64% CTR index improvement relative to the baselines and a 5.19% increase in daily order volume proportion.
An Advanced Reinforcement Learning Framework for Online Scheduling of Deferrable Workloads in Cloud Computing
Jun 03, 2024
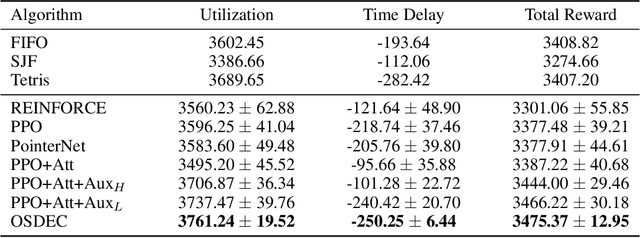
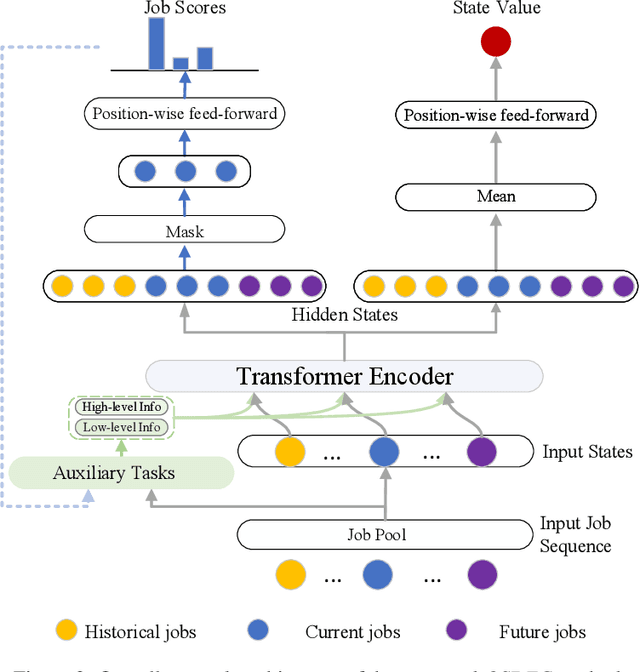
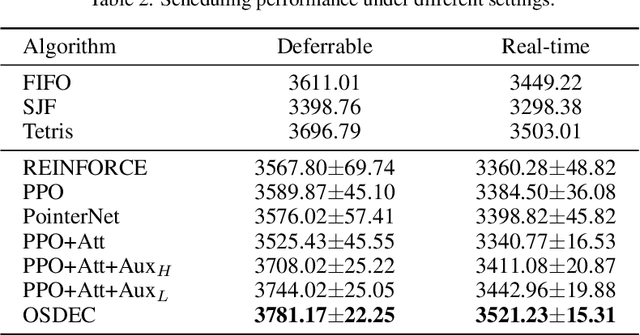
Efficient resource utilization and perfect user experience usually conflict with each other in cloud computing platforms. Great efforts have been invested in increasing resource utilization but trying not to affect users' experience for cloud computing platforms. In order to better utilize the remaining pieces of computing resources spread over the whole platform, deferrable jobs are provided with a discounted price to users. For this type of deferrable jobs, users are allowed to submit jobs that will run for a specific uninterrupted duration in a flexible range of time in the future with a great discount. With these deferrable jobs to be scheduled under the remaining capacity after deploying those on-demand jobs, it remains a challenge to achieve high resource utilization and meanwhile shorten the waiting time for users as much as possible in an online manner. In this paper, we propose an online deferrable job scheduling method called \textit{Online Scheduling for DEferrable jobs in Cloud} (\OSDEC{}), where a deep reinforcement learning model is adopted to learn the scheduling policy, and several auxiliary tasks are utilized to provide better state representations and improve the performance of the model. With the integrated reinforcement learning framework, the proposed method can well plan the deployment schedule and achieve a short waiting time for users while maintaining a high resource utilization for the platform. The proposed method is validated on a public dataset and shows superior performance.
Better Understandings and Configurations in MaxSAT Local Search Solvers via Anytime Performance Analysis
Mar 11, 2024Though numerous solvers have been proposed for the MaxSAT problem, and the benchmark environment such as MaxSAT Evaluations provides a platform for the comparison of the state-of-the-art solvers, existing assessments were usually evaluated based on the quality, e.g., fitness, of the best-found solutions obtained within a given running time budget. However, concerning solely the final obtained solutions regarding specific time budgets may restrict us from comprehending the behavior of the solvers along the convergence process. This paper demonstrates that Empirical Cumulative Distribution Functions can be used to compare MaxSAT local search solvers' anytime performance across multiple problem instances and various time budgets. The assessment reveals distinctions in solvers' performance and displays that the (dis)advantages of solvers adjust along different running times. This work also exhibits that the quantitative and high variance assessment of anytime performance can guide machines, i.e., automatic configurators, to search for better parameter settings. Our experimental results show that the hyperparameter optimization tool, i.e., SMAC, generally achieves better parameter settings of local search when using the anytime performance as the cost function, compared to using the fitness of the best-found solutions.
Entire Chain Uplift Modeling with Context-Enhanced Learning for Intelligent Marketing
Feb 04, 2024



Uplift modeling, vital in online marketing, seeks to accurately measure the impact of various strategies, such as coupons or discounts, on different users by predicting the Individual Treatment Effect (ITE). In an e-commerce setting, user behavior follows a defined sequential chain, including impression, click, and conversion. Marketing strategies exert varied uplift effects at each stage within this chain, impacting metrics like click-through and conversion rate. Despite its utility, existing research has neglected to consider the inter-task across all stages impacts within a specific treatment and has insufficiently utilized the treatment information, potentially introducing substantial bias into subsequent marketing decisions. We identify these two issues as the chain-bias problem and the treatment-unadaptive problem. This paper introduces the Entire Chain UPlift method with context-enhanced learning (ECUP), devised to tackle these issues. ECUP consists of two primary components: 1) the Entire Chain-Enhanced Network, which utilizes user behavior patterns to estimate ITE throughout the entire chain space, models the various impacts of treatments on each task, and integrates task prior information to enhance context awareness across all stages, capturing the impact of treatment on different tasks, and 2) the Treatment-Enhanced Network, which facilitates fine-grained treatment modeling through bit-level feature interactions, thereby enabling adaptive feature adjustment. Extensive experiments on public and industrial datasets validate ECUPs effectiveness. Moreover, ECUP has been deployed on the Meituan food delivery platform, serving millions of daily active users, with the related dataset released for future research.
Contrastive Learning with Negative Sampling Correction
Jan 13, 2024As one of the most effective self-supervised representation learning methods, contrastive learning (CL) relies on multiple negative pairs to contrast against each positive pair. In the standard practice of contrastive learning, data augmentation methods are utilized to generate both positive and negative pairs. While existing works have been focusing on improving the positive sampling, the negative sampling process is often overlooked. In fact, the generated negative samples are often polluted by positive samples, which leads to a biased loss and performance degradation. To correct the negative sampling bias, we propose a novel contrastive learning method named Positive-Unlabeled Contrastive Learning (PUCL). PUCL treats the generated negative samples as unlabeled samples and uses information from positive samples to correct bias in contrastive loss. We prove that the corrected loss used in PUCL only incurs a negligible bias compared to the unbiased contrastive loss. PUCL can be applied to general contrastive learning problems and outperforms state-of-the-art methods on various image and graph classification tasks. The code of PUCL is in the supplementary file.
HiNet: Novel Multi-Scenario & Multi-Task Learning with Hierarchical Information Extraction
Mar 14, 2023



Multi-scenario & multi-task learning has been widely applied to many recommendation systems in industrial applications, wherein an effective and practical approach is to carry out multi-scenario transfer learning on the basis of the Mixture-of-Expert (MoE) architecture. However, the MoE-based method, which aims to project all information in the same feature space, cannot effectively deal with the complex relationships inherent among various scenarios and tasks, resulting in unsatisfactory performance. To tackle the problem, we propose a Hierarchical information extraction Network (HiNet) for multi-scenario and multi-task recommendation, which achieves hierarchical extraction based on coarse-to-fine knowledge transfer scheme. The multiple extraction layers of the hierarchical network enable the model to enhance the capability of transferring valuable information across scenarios while preserving specific features of scenarios and tasks. Furthermore, a novel scenario-aware attentive network module is proposed to model correlations between scenarios explicitly. Comprehensive experiments conducted on real-world industrial datasets from Meituan Meishi platform demonstrate that HiNet achieves a new state-of-the-art performance and significantly outperforms existing solutions. HiNet is currently fully deployed in two scenarios and has achieved 2.87% and 1.75% order quantity gain respectively.
Feature Decomposition for Reducing Negative Transfer: A Novel Multi-task Learning Method for Recommender System
Feb 10, 2023In recent years, thanks to the rapid development of deep learning (DL), DL-based multi-task learning (MTL) has made significant progress, and it has been successfully applied to recommendation systems (RS). However, in a recommender system, the correlations among the involved tasks are complex. Therefore, the existing MTL models designed for RS suffer from negative transfer to different degrees, which will injure optimization in MTL. We find that the root cause of negative transfer is feature redundancy that features learned for different tasks interfere with each other. To alleviate the issue of negative transfer, we propose a novel multi-task learning method termed Feature Decomposition Network (FDN). The key idea of the proposed FDN is reducing the phenomenon of feature redundancy by explicitly decomposing features into task-specific features and task-shared features with carefully designed constraints. We demonstrate the effectiveness of the proposed method on two datasets, a synthetic dataset and a public datasets (i.e., Ali-CCP). Experimental results show that our proposed FDN can outperform the state-of-the-art (SOTA) methods by a noticeable margin.
Distributed Evolution Strategies for Black-box Stochastic Optimization
Apr 09, 2022
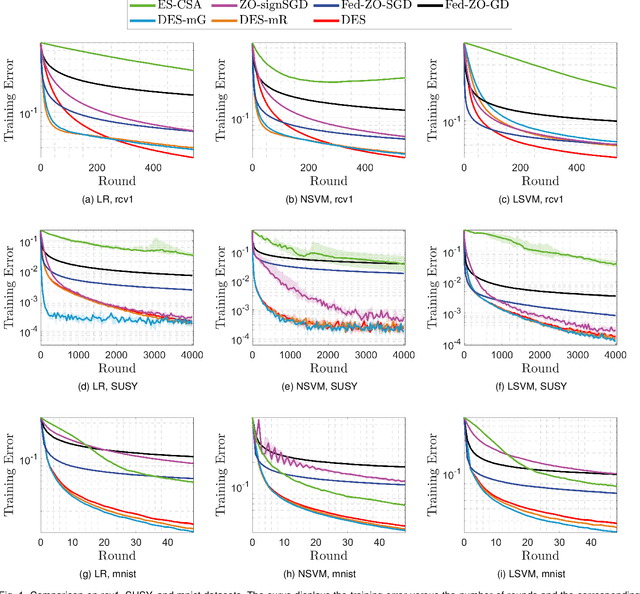
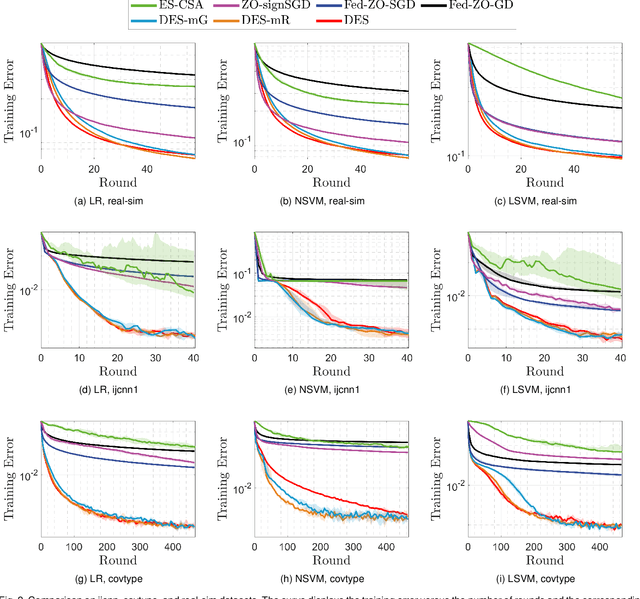
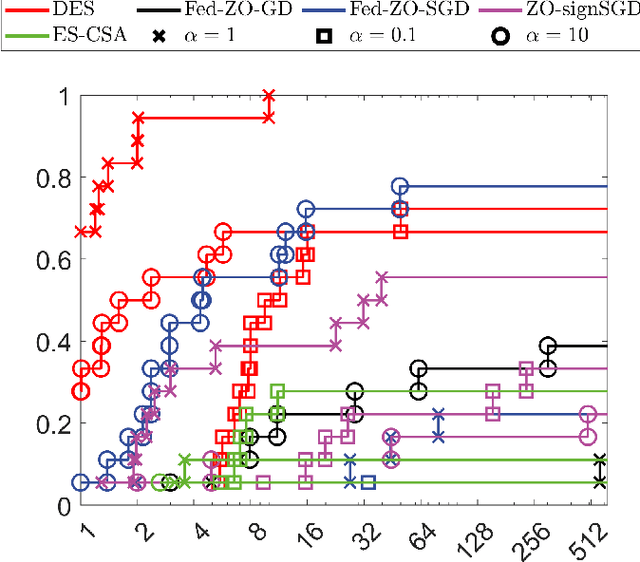
This work concerns the evolutionary approaches to distributed stochastic black-box optimization, in which each worker can individually solve an approximation of the problem with nature-inspired algorithms. We propose a distributed evolution strategy (DES) algorithm grounded on a proper modification to evolution strategies, a family of classic evolutionary algorithms, as well as a careful combination with existing distributed frameworks. On smooth and nonconvex landscapes, DES has a convergence rate competitive to existing zeroth-order methods, and can exploit the sparsity, if applicable, to match the rate of first-order methods. The DES method uses a Gaussian probability model to guide the search and avoids the numerical issue resulted from finite-difference techniques in existing zeroth-order methods. The DES method is also fully adaptive to the problem landscape, as its convergence is guaranteed with any parameter setting. We further propose two alternative sampling schemes which significantly improve the sampling efficiency while leading to similar performance. Simulation studies on several machine learning problems suggest that the proposed methods show much promise in reducing the convergence time and improving the robustness to parameter settings.
A Surrogate Objective Framework for Prediction+Optimization with Soft Constraints
Nov 22, 2021

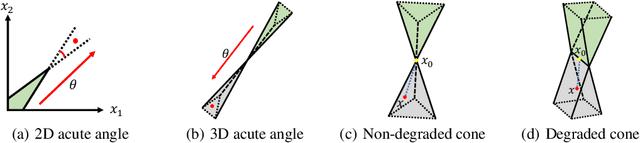
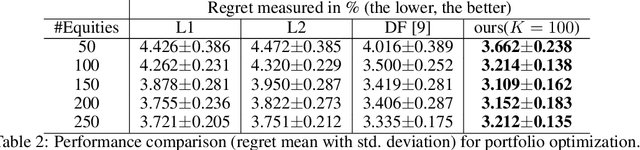
Prediction+optimization is a common real-world paradigm where we have to predict problem parameters before solving the optimization problem. However, the criteria by which the prediction model is trained are often inconsistent with the goal of the downstream optimization problem. Recently, decision-focused prediction approaches, such as SPO+ and direct optimization, have been proposed to fill this gap. However, they cannot directly handle the soft constraints with the $max$ operator required in many real-world objectives. This paper proposes a novel analytically differentiable surrogate objective framework for real-world linear and semi-definite negative quadratic programming problems with soft linear and non-negative hard constraints. This framework gives the theoretical bounds on constraints' multipliers, and derives the closed-form solution with respect to predictive parameters and thus gradients for any variable in the problem. We evaluate our method in three applications extended with soft constraints: synthetic linear programming, portfolio optimization, and resource provisioning, demonstrating that our method outperforms traditional two-staged methods and other decision-focused approaches.
Hashing-Accelerated Graph Neural Networks for Link Prediction
May 29, 2021



Networks are ubiquitous in the real world. Link prediction, as one of the key problems for network-structured data, aims to predict whether there exists a link between two nodes. The traditional approaches are based on the explicit similarity computation between the compact node representation by embedding each node into a low-dimensional space. In order to efficiently handle the intensive similarity computation in link prediction, the hashing technique has been successfully used to produce the node representation in the Hamming space. However, the hashing-based link prediction algorithms face accuracy loss from the randomized hashing techniques or inefficiency from the learning to hash techniques in the embedding process. Currently, the Graph Neural Network (GNN) framework has been widely applied to the graph-related tasks in an end-to-end manner, but it commonly requires substantial computational resources and memory costs due to massive parameter learning, which makes the GNN-based algorithms impractical without the help of a powerful workhorse. In this paper, we propose a simple and effective model called #GNN, which balances the trade-off between accuracy and efficiency. #GNN is able to efficiently acquire node representation in the Hamming space for link prediction by exploiting the randomized hashing technique to implement message passing and capture high-order proximity in the GNN framework. Furthermore, we characterize the discriminative power of #GNN in probability. The extensive experimental results demonstrate that the proposed #GNN algorithm achieves accuracy comparable to the learning-based algorithms and outperforms the randomized algorithm, while running significantly faster than the learning-based algorithms. Also, the proposed algorithm shows excellent scalability on a large-scale network with the limited resources.