 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProposition from the Perspective of Chinese Language: A Chinese Proposition Classification Evaluation Benchmark
Sep 18, 2023Existing propositions often rely on logical constants for classification. Compared with Western languages that lean towards hypotaxis such as English, Chinese often relies on semantic or logical understanding rather than logical connectives in daily expressions, exhibiting the characteristics of parataxis. However, existing research has rarely paid attention to this issue. And accurately classifying these propositions is crucial for natural language understanding and reasoning. In this paper, we put forward the concepts of explicit and implicit propositions and propose a comprehensive multi-level proposition classification system based on linguistics and logic. Correspondingly, we create a large-scale Chinese proposition dataset PEACE from multiple domains, covering all categories related to propositions. To evaluate the Chinese proposition classification ability of existing models and explore their limitations, We conduct evaluations on PEACE using several different methods including the Rule-based method, SVM, BERT, RoBERTA, and ChatGPT. Results show the importance of properly modeling the semantic features of propositions. BERT has relatively good proposition classification capability, but lacks cross-domain transferability. ChatGPT performs poorly, but its classification ability can be improved by providing more proposition information. Many issues are still far from being resolved and require further study.
HiNet: Novel Multi-Scenario & Multi-Task Learning with Hierarchical Information Extraction
Mar 14, 2023



Multi-scenario & multi-task learning has been widely applied to many recommendation systems in industrial applications, wherein an effective and practical approach is to carry out multi-scenario transfer learning on the basis of the Mixture-of-Expert (MoE) architecture. However, the MoE-based method, which aims to project all information in the same feature space, cannot effectively deal with the complex relationships inherent among various scenarios and tasks, resulting in unsatisfactory performance. To tackle the problem, we propose a Hierarchical information extraction Network (HiNet) for multi-scenario and multi-task recommendation, which achieves hierarchical extraction based on coarse-to-fine knowledge transfer scheme. The multiple extraction layers of the hierarchical network enable the model to enhance the capability of transferring valuable information across scenarios while preserving specific features of scenarios and tasks. Furthermore, a novel scenario-aware attentive network module is proposed to model correlations between scenarios explicitly. Comprehensive experiments conducted on real-world industrial datasets from Meituan Meishi platform demonstrate that HiNet achieves a new state-of-the-art performance and significantly outperforms existing solutions. HiNet is currently fully deployed in two scenarios and has achieved 2.87% and 1.75% order quantity gain respectively.
Modeling Relevance Ranking under the Pre-training and Fine-tuning Paradigm
Aug 12, 2021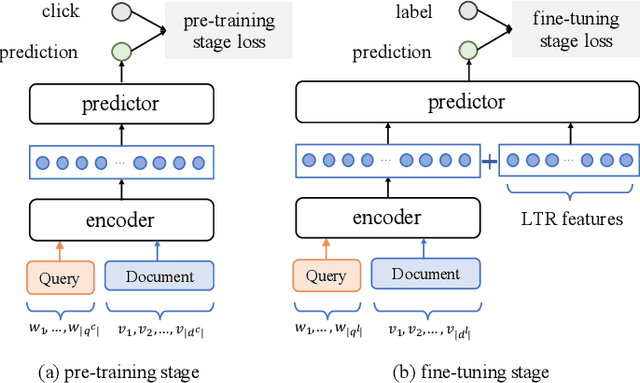
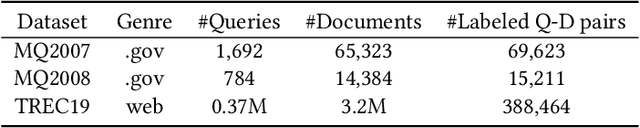
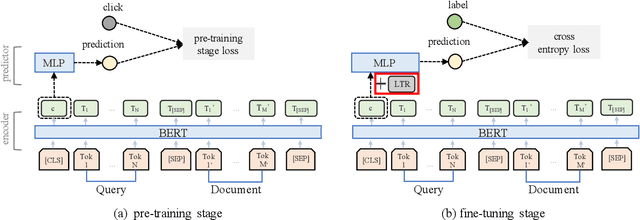
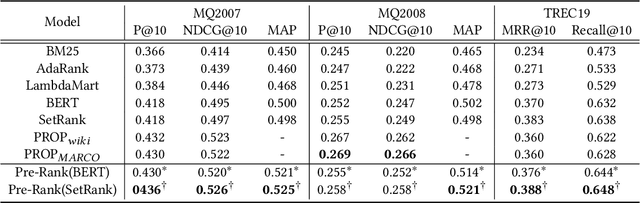
Recently, pre-trained language models such as BERT have been applied to document ranking for information retrieval, which first pre-train a general language model on an unlabeled large corpus and then conduct ranking-specific fine-tuning on expert-labeled relevance datasets. Ideally, an IR system would model relevance from a user-system dualism: the user's view and the system's view. User's view judges the relevance based on the activities of "real users" while the system's view focuses on the relevance signals from the system side, e.g., from the experts or algorithms, etc. Inspired by the user-system relevance views and the success of pre-trained language models, in this paper we propose a novel ranking framework called Pre-Rank that takes both user's view and system's view into consideration, under the pre-training and fine-tuning paradigm. Specifically, to model the user's view of relevance, Pre-Rank pre-trains the initial query-document representations based on large-scale user activities data such as the click log. To model the system's view of relevance, Pre-Rank further fine-tunes the model on expert-labeled relevance data. More importantly, the pre-trained representations, are fine-tuned together with handcrafted learning-to-rank features under a wide and deep network architecture. In this way, Pre-Rank can model the relevance by incorporating the relevant knowledge and signals from both real search users and the IR experts. To verify the effectiveness of Pre-Rank, we showed two implementations by using BERT and SetRank as the underlying ranking model, respectively. Experimental results base on three publicly available benchmarks showed that in both of the implementations, Pre-Rank can respectively outperform the underlying ranking models and achieved state-of-the-art performances.