 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBringing Reasoning to Generative Recommendation Through the Lens of Cascaded Ranking
Feb 03, 2026Generative Recommendation (GR) has become a promising end-to-end approach with high FLOPS utilization for resource-efficient recommendation. Despite the effectiveness, we show that current GR models suffer from a critical \textbf{bias amplification} issue, where token-level bias escalates as token generation progresses, ultimately limiting the recommendation diversity and hurting the user experience. By comparing against the key factor behind the success of traditional multi-stage pipelines, we reveal two limitations in GR that can amplify the bias: homogeneous reliance on the encoded history, and fixed computational budgets that prevent deeper user preference understanding. To combat the bias amplification issue, it is crucial for GR to 1) incorporate more heterogeneous information, and 2) allocate greater computational resources at each token generation step. To this end, we propose CARE, a simple yet effective cascaded reasoning framework for debiased GR. To incorporate heterogeneous information, we introduce a progressive history encoding mechanism, which progressively incorporates increasingly fine-grained history information as the generation process advances. To allocate more computations, we propose a query-anchored reasoning mechanism, which seeks to perform a deeper understanding of historical information through parallel reasoning steps. We instantiate CARE on three GR backbones. Empirical results on four datasets show the superiority of CARE in recommendation accuracy, diversity, efficiency, and promising scalability. The codes and datasets are available at https://github.com/Linxyhaha/CARE.
From Pixels to Predicates Structuring urban perception with scene graphs
Dec 22, 2025Perception research is increasingly modelled using streetscapes, yet many approaches still rely on pixel features or object co-occurrence statistics, overlooking the explicit relations that shape human perception. This study proposes a three stage pipeline that transforms street view imagery (SVI) into structured representations for predicting six perceptual indicators. In the first stage, each image is parsed using an open-set Panoptic Scene Graph model (OpenPSG) to extract object predicate object triplets. In the second stage, compact scene-level embeddings are learned through a heterogeneous graph autoencoder (GraphMAE). In the third stage, a neural network predicts perception scores from these embeddings. We evaluate the proposed approach against image-only baselines in terms of accuracy, precision, and cross-city generalization. Results indicate that (i) our approach improves perception prediction accuracy by an average of 26% over baseline models, and (ii) maintains strong generalization performance in cross-city prediction tasks. Additionally, the structured representation clarifies which relational patterns contribute to lower perception scores in urban scenes, such as graffiti on wall and car parked on sidewalk. Overall, this study demonstrates that graph-based structure provides expressive, generalizable, and interpretable signals for modelling urban perception, advancing human-centric and context-aware urban analytics.
Image-based Visibility Analysis Replacing Line-of-Sight Simulation: An Urban Landmark Perspective
May 17, 2025Visibility analysis is one of the fundamental analytics methods in urban planning and landscape research, traditionally conducted through computational simulations based on the Line-of-Sight (LoS) principle. However, when assessing the visibility of named urban objects such as landmarks, geometric intersection alone fails to capture the contextual and perceptual dimensions of visibility as experienced in the real world. The study challenges the traditional LoS-based approaches by introducing a new, image-based visibility analysis method. Specifically, a Vision Language Model (VLM) is applied to detect the target object within a direction-zoomed Street View Image (SVI). Successful detection represents the object's visibility at the corresponding SVI location. Further, a heterogeneous visibility graph is constructed to address the complex interaction between observers and target objects. In the first case study, the method proves its reliability in detecting the visibility of six tall landmark constructions in global cities, with an overall accuracy of 87%. Furthermore, it reveals broader contextual differences when the landmarks are perceived and experienced. In the second case, the proposed visibility graph uncovers the form and strength of connections for multiple landmarks along the River Thames in London, as well as the places where these connections occur. Notably, bridges on the River Thames account for approximately 30% of total connections. Our method complements and enhances traditional LoS-based visibility analysis, and showcases the possibility of revealing the prevalent connection of any visual objects in the urban environment. It opens up new research perspectives for urban planning, heritage conservation, and computational social science.
Evaluating Moral Beliefs across LLMs through a Pluralistic Framework
Nov 06, 2024Proper moral beliefs are fundamental for language models, yet assessing these beliefs poses a significant challenge. This study introduces a novel three-module framework to evaluate the moral beliefs of four prominent large language models. Initially, we constructed a dataset containing 472 moral choice scenarios in Chinese, derived from moral words. The decision-making process of the models in these scenarios reveals their moral principle preferences. By ranking these moral choices, we discern the varying moral beliefs held by different language models. Additionally, through moral debates, we investigate the firmness of these models to their moral choices. Our findings indicate that English language models, namely ChatGPT and Gemini, closely mirror moral decisions of the sample of Chinese university students, demonstrating strong adherence to their choices and a preference for individualistic moral beliefs. In contrast, Chinese models such as Ernie and ChatGLM lean towards collectivist moral beliefs, exhibiting ambiguity in their moral choices and debates. This study also uncovers gender bias embedded within the moral beliefs of all examined language models. Our methodology offers an innovative means to assess moral beliefs in both artificial and human intelligence, facilitating a comparison of moral values across different cultures.
MatPlotAgent: Method and Evaluation for LLM-Based Agentic Scientific Data Visualization
Feb 18, 2024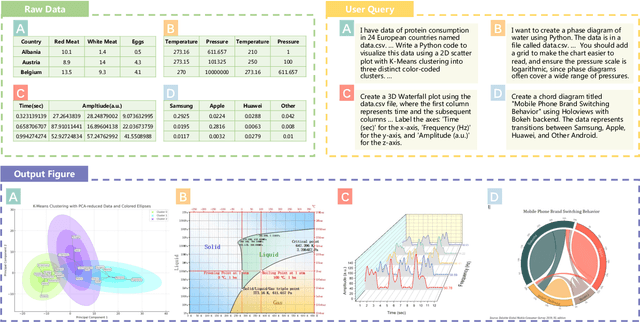
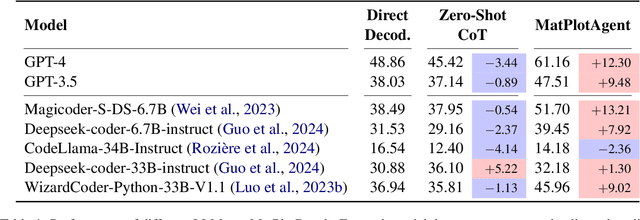
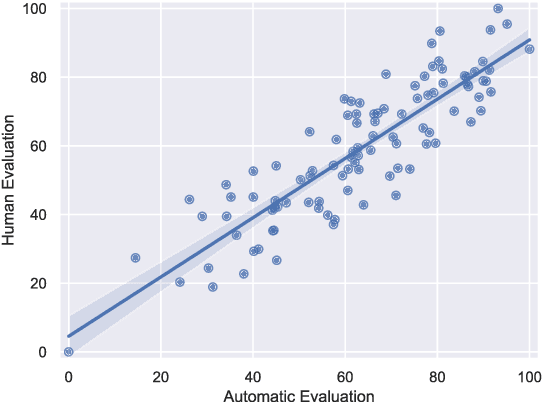
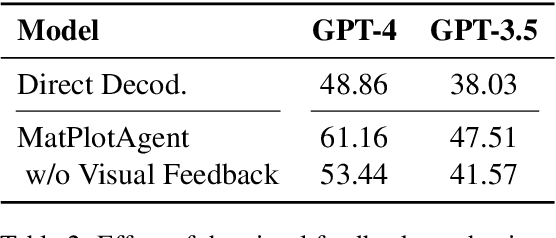
Scientific data visualization plays a crucial role in research by enabling the direct display of complex information and assisting researchers in identifying implicit patterns. Despite its importance, the use of Large Language Models (LLMs) for scientific data visualization remains rather unexplored. In this study, we introduce MatPlotAgent, an efficient model-agnostic LLM agent framework designed to automate scientific data visualization tasks. Leveraging the capabilities of both code LLMs and multi-modal LLMs, MatPlotAgent consists of three core modules: query understanding, code generation with iterative debugging, and a visual feedback mechanism for error correction. To address the lack of benchmarks in this field, we present MatPlotBench, a high-quality benchmark consisting of 100 human-verified test cases. Additionally, we introduce a scoring approach that utilizes GPT-4V for automatic evaluation. Experimental results demonstrate that MatPlotAgent can improve the performance of various LLMs, including both commercial and open-source models. Furthermore, the proposed evaluation method shows a strong correlation with human-annotated scores.
How does spatial structure affect psychological restoration? A method based on Graph Neural Networks and Street View Imagery
Nov 30, 2023
The Attention Restoration Theory (ART) presents a theoretical framework with four essential indicators (being away, extent, fascinating, and compatibility) for comprehending urban and natural restoration quality. However, previous studies relied on non-sequential data and non-spatial dependent methods, which overlooks the impact of spatial structure defined here as the positional relationships between scene entities on restoration quality. The past methods also make it challenging to measure restoration quality on an urban scale. In this work, a spatial-dependent graph neural networks (GNNs) approach is proposed to reveal the relation between spatial structure and restoration quality on an urban scale. Specifically, we constructed two different types of graphs at the street and city levels. The street-level graphs, using sequential street view images (SVIs) of road segments to capture position relationships between entities, were used to represent spatial structure. The city-level graph, modeling the topological relationships of roads as non-Euclidean data structures and embedding urban features (including Perception-features, Spatial-features, and Socioeconomic-features), was used to measure restoration quality. The results demonstrate that: 1) spatial-dependent GNNs model outperforms traditional methods (Acc = 0.735, F1 = 0.732); 2) spatial structure portrayed through sequential SVIs data significantly influences restoration quality; 3) spaces with the same restoration quality exhibited distinct spatial structures patterns. This study clarifies the association between spatial structure and restoration quality, providing a new perspective to improve urban well-being in the future.
Proposition from the Perspective of Chinese Language: A Chinese Proposition Classification Evaluation Benchmark
Sep 18, 2023Existing propositions often rely on logical constants for classification. Compared with Western languages that lean towards hypotaxis such as English, Chinese often relies on semantic or logical understanding rather than logical connectives in daily expressions, exhibiting the characteristics of parataxis. However, existing research has rarely paid attention to this issue. And accurately classifying these propositions is crucial for natural language understanding and reasoning. In this paper, we put forward the concepts of explicit and implicit propositions and propose a comprehensive multi-level proposition classification system based on linguistics and logic. Correspondingly, we create a large-scale Chinese proposition dataset PEACE from multiple domains, covering all categories related to propositions. To evaluate the Chinese proposition classification ability of existing models and explore their limitations, We conduct evaluations on PEACE using several different methods including the Rule-based method, SVM, BERT, RoBERTA, and ChatGPT. Results show the importance of properly modeling the semantic features of propositions. BERT has relatively good proposition classification capability, but lacks cross-domain transferability. ChatGPT performs poorly, but its classification ability can be improved by providing more proposition information. Many issues are still far from being resolved and require further study.
ECSP: A New Task for Emotion-Cause Span-Pair Extraction and Classification
Mar 07, 2020

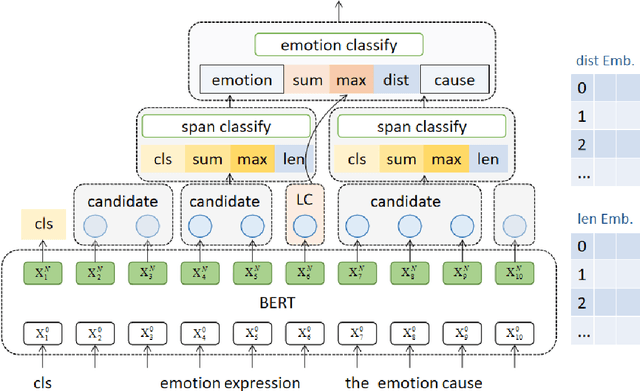

Emotion cause analysis such as emotion cause extraction (ECE) and emotion-cause pair extraction (ECPE) have gradually attracted the attention of many researchers. However, there are still two shortcomings in the existing research: 1) In most cases, emotion expression and cause are not the whole clause, but the span in the clause, so extracting the clause-pair rather than the span-pair greatly limits its applications in real-world scenarios; 2) It is not enough to extract the emotion expression clause without identifying the emotion categories, the presence of emotion clause does not necessarily convey emotional information explicitly due to different possible causes. In this paper, we propose a new task: Emotion-Cause Span-Pair extraction and classification (ECSP), which aims to extract the potential span-pair of emotion and corresponding causes in a document, and make emotion classification for each pair. In the new ECSP task, ECE and ECPE can be regarded as two special cases at the clause-level. We propose a span-based extract-then-classify (ETC) model, where emotion and cause are directly extracted and paired from the document under the supervision of target span boundaries, and corresponding categories are then classified using their pair representations and localized context. Experiments show that our proposed ETC model outperforms the SOTA model of ECE and ECPE task respectively and gets a fair-enough results on ECSP task.
XCMRC: Evaluating Cross-lingual Machine Reading Comprehension
Aug 15, 2019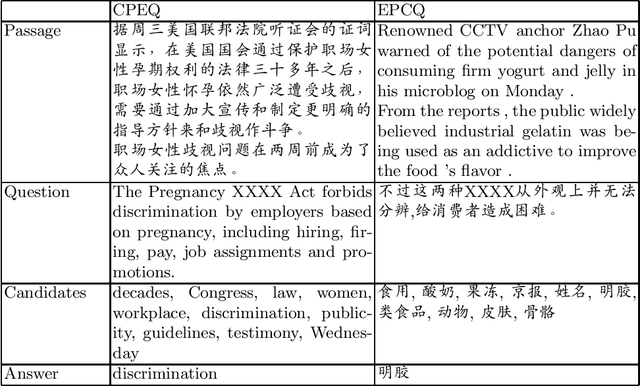
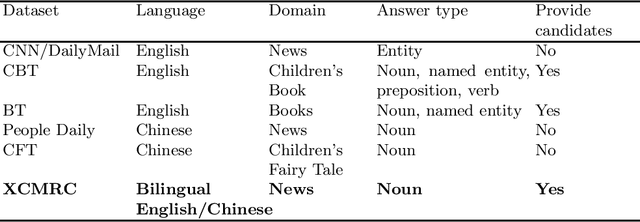
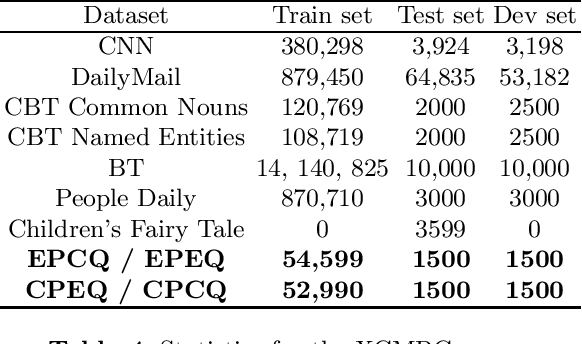
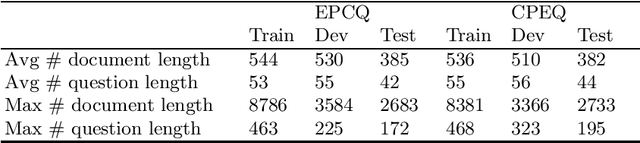
We present XCMRC, the first public cross-lingual language understanding (XLU) benchmark which aims to test machines on their cross-lingual reading comprehension ability. To be specific, XCMRC is a Cross-lingual Cloze-style Machine Reading Comprehension task which requires the reader to fill in a missing word (we additionally provide ten noun candidates) in a sentence written in target language (English / Chinese) by reading a given passage written in source language (Chinese / English). Chinese and English are rich-resource language pairs, in order to study low-resource cross-lingual machine reading comprehension (XMRC), besides defining the common XCMRC task which has no restrictions on use of external language resources, we also define the pseudo low-resource XCMRC task by limiting the language resources to be used. In addition, we provide two baselines for common XCMRC task and two for pseudo XCMRC task respectively. We also provide an upper bound baseline for both tasks. We found that for common XCMRC task, translation-based method and multilingual sentence encoder-based method can obtain reasonable performance but still have much room for improvement. As for pseudo low-resource XCMRC task, due to strict restrictions on the use of language resources, our two approaches are far below the upper bound so there are many challenges ahead.
Emotion Action Detection and Emotion Inference: the Task and Dataset
Mar 16, 2019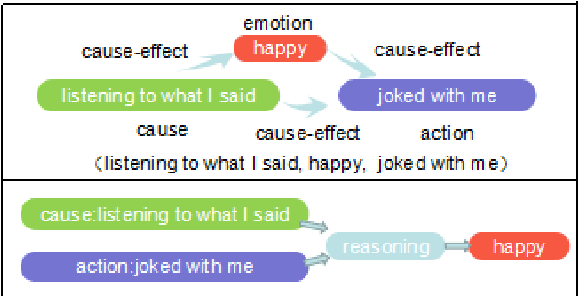



Many Natural Language Processing works on emotion analysis only focus on simple emotion classification without exploring the potentials of putting emotion into "event context", and ignore the analysis of emotion-related events. One main reason is the lack of this kind of corpus. Here we present Cause-Emotion-Action Corpus, which manually annotates not only emotion, but also cause events and action events. We propose two new tasks based on the data-set: emotion causality and emotion inference. The first task is to extract a triple (cause, emotion, action). The second task is to infer the probable emotion. We are currently releasing the data-set with 10,603 samples and 15,892 events, basic statistic analysis and baseline on both emotion causality and emotion inference tasks. Baseline performance demonstrates that there is much room for both tasks to be improved.