 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXCMRC: Evaluating Cross-lingual Machine Reading Comprehension
Paper and Code
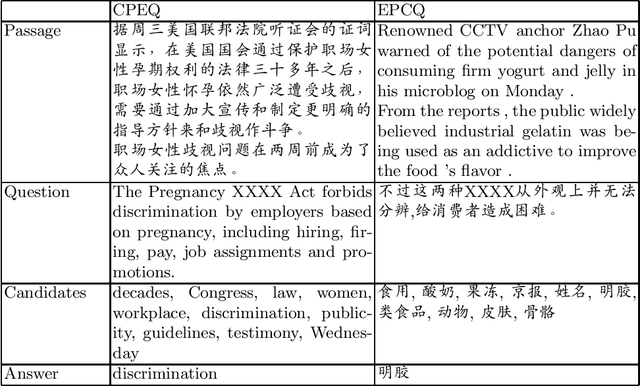
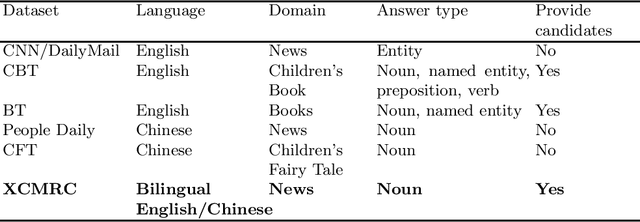
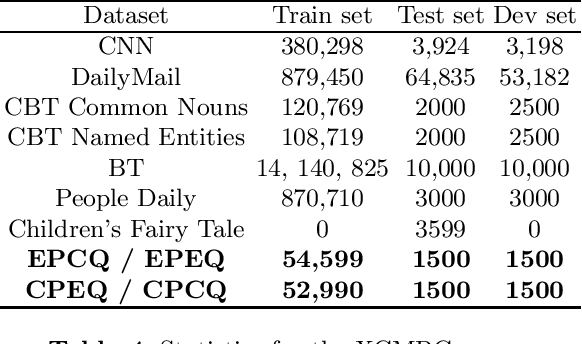
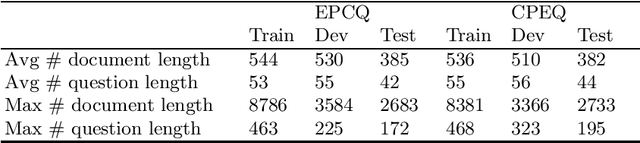
We present XCMRC, the first public cross-lingual language understanding (XLU) benchmark which aims to test machines on their cross-lingual reading comprehension ability. To be specific, XCMRC is a Cross-lingual Cloze-style Machine Reading Comprehension task which requires the reader to fill in a missing word (we additionally provide ten noun candidates) in a sentence written in target language (English / Chinese) by reading a given passage written in source language (Chinese / English). Chinese and English are rich-resource language pairs, in order to study low-resource cross-lingual machine reading comprehension (XMRC), besides defining the common XCMRC task which has no restrictions on use of external language resources, we also define the pseudo low-resource XCMRC task by limiting the language resources to be used. In addition, we provide two baselines for common XCMRC task and two for pseudo XCMRC task respectively. We also provide an upper bound baseline for both tasks. We found that for common XCMRC task, translation-based method and multilingual sentence encoder-based method can obtain reasonable performance but still have much room for improvement. As for pseudo low-resource XCMRC task, due to strict restrictions on the use of language resources, our two approaches are far below the upper bound so there are many challenges ahead.