 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscrimination Is Generation: Unifying Ranking and Retrieval from a Tokenizer Perspective
May 14, 2026Semantic IDs (SIDs) define the generation space of generative recommendation and directly determine its personalization ceiling. However, existing tokenizers are trained independently with retrieval objectives, leaving personalization signals fully decoupled from the SID construction process -- a fundamental gap that causes generative retrieval to persistently lag behind discriminative ranking. In this paper, we rethink the essence of SIDs: \emph{ranking seeks argmax in item space while retrieval seeks argmax in token space; both are the same problem solved at different granularities.} Based on this insight, we propose \DIG (\textbf{D}iscrimination \textbf{I}s \textbf{G}eneration), which embeds the tokenizer inside a discriminative ranking model for end-to-end training -- the ranker naturally becomes a retrieval model, yielding two models from a single training run. \DIG is organized around a \emph{feature assignment taxonomy}: item-intrinsic static features are encoded into SIDs, user-item cross features (u2i) implicitly drive codebook boundaries toward recommendation decision boundaries during training, and an MLP$_\mathrm{u2t}$ distillation module approximates u2i at the token level for inference. Experiments on three public benchmarks and two industrial datasets demonstrate that \DIG simultaneously improves ranking, retrieval, and unified retrieval-ranking quality.
Next-Scale Generative Reranking: A Tree-based Generative Rerank Method at Meituan
Apr 07, 2026In modern multi-stage recommendation systems, reranking plays a critical role by modeling contextual information. Due to inherent challenges such as the combinatorial space complexity, an increasing number of methods adopt the generative paradigm: the generator produces the optimal list during inference, while an evaluator guides the generator's optimization during the training phase. However, these methods still face two problems. Firstly, these generators fail to produce optimal generation results due to the lack of both local and global perspectives, regardless of whether the generation strategy is autoregressive or non-autoregressive. Secondly, the goal inconsistency problem between the generator and the evaluator during training complicates the guidance signal and leading to suboptimal performance. To address these issues, we propose the \textbf{N}ext-\textbf{S}cale \textbf{G}eneration \textbf{R}eranking (NSGR), a tree-based generative framework. Specifically, we introduce a next-scale generator (NSG) that progressively expands a recommendation list from user interests in a coarse-to-fine manner, balancing global and local perspectives. Furthermore, we design a multi-scale neighbor loss, which leverages a tree-based multi-scale evaluator (MSE) to provide scale-specific guidance to the NSG at each scale. Extensive experiments on public and industrial datasets validate the effectiveness of NSGR. And NSGR has been successfully deployed on the Meituan food delivery platform.
MBGR: Multi-Business Prediction for Generative Recommendation at Meituan
Apr 03, 2026Generative recommendation (GR) has recently emerged as a promising paradigm for industrial recommendations. GR leverages Semantic IDs (SIDs) to reduce the encoding-decoding space and employs the Next Token Prediction (NTP) framework to explore scaling laws. However, existing GR methods suffer from two critical issues: (1) a \textbf{seesaw phenomenon} in multi-business scenarios arises due to NTP's inability to capture complex cross-business behavioral patterns; and (2) a unified SID space causes \textbf{representation confusion} by failing to distinguish distinct semantic information across businesses. To address these issues, we propose Multi-Business Generative Recommendation (MBGR), the first GR framework tailored for multi-business scenarios. Our framework comprises three key components. First, we design a Business-aware semantic ID (BID) module that preserves semantic integrity via domain-aware tokenization. Then, we introduce a Multi-Business Prediction (MBP) structure to provide business-specific prediction capabilities. Furthermore, we develop a Label Dynamic Routing (LDR) module that transforms sparse multi-business labels into dense labels to further enhance the multi-business generation capability. Extensive offline and online experiments on Meituan's food delivery platform validate MBGR's effectiveness, and we have successfully deployed it in production.
DOS: Dual-Flow Orthogonal Semantic IDs for Recommendation in Meituan
Feb 04, 2026Semantic IDs serve as a key component in generative recommendation systems. They not only incorporate open-world knowledge from large language models (LLMs) but also compress the semantic space to reduce generation difficulty. However, existing methods suffer from two major limitations: (1) the lack of contextual awareness in generation tasks leads to a gap between the Semantic ID codebook space and the generation space, resulting in suboptimal recommendations; and (2) suboptimal quantization methods exacerbate semantic loss in LLMs. To address these issues, we propose Dual-Flow Orthogonal Semantic IDs (DOS) method. Specifically, DOS employs a user-item dual flow-framework that leverages collaborative signals to align the Semantic ID codebook space with the generation space. Furthermore, we introduce an orthogonal residual quantization scheme that rotates the semantic space to an appropriate orientation, thereby maximizing semantic preservation. Extensive offline experiments and online A/B testing demonstrate the effectiveness of DOS. The proposed method has been successfully deployed in Meituan's mobile application, serving hundreds of millions of users.
You Only Evaluate Once: A Tree-based Rerank Method at Meituan
Aug 20, 2025

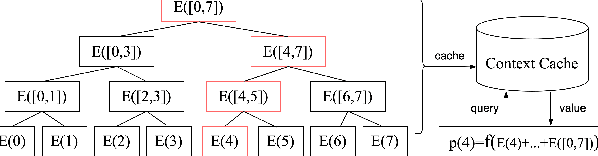

Reranking plays a crucial role in modern recommender systems by capturing the mutual influences within the list. Due to the inherent challenges of combinatorial search spaces, most methods adopt a two-stage search paradigm: a simple General Search Unit (GSU) efficiently reduces the candidate space, and an Exact Search Unit (ESU) effectively selects the optimal sequence. These methods essentially involve making trade-offs between effectiveness and efficiency, while suffering from a severe \textbf{inconsistency problem}, that is, the GSU often misses high-value lists from ESU. To address this problem, we propose YOLOR, a one-stage reranking method that removes the GSU while retaining only the ESU. Specifically, YOLOR includes: (1) a Tree-based Context Extraction Module (TCEM) that hierarchically aggregates multi-scale contextual features to achieve "list-level effectiveness", and (2) a Context Cache Module (CCM) that enables efficient feature reuse across candidate permutations to achieve "permutation-level efficiency". Extensive experiments across public and industry datasets validate YOLOR's performance, and we have successfully deployed YOLOR on the Meituan food delivery platform.
NLGR: Utilizing Neighbor Lists for Generative Rerank in Personalized Recommendation Systems
Feb 10, 2025



Reranking plays a crucial role in modern multi-stage recommender systems by rearranging the initial ranking list. Due to the inherent challenges of combinatorial search spaces, some current research adopts an evaluator-generator paradigm, with a generator generating feasible sequences and an evaluator selecting the best sequence based on the estimated list utility. However, these methods still face two issues. Firstly, due to the goal inconsistency problem between the evaluator and generator, the generator tends to fit the local optimal solution of exposure distribution rather than combinatorial space optimization. Secondly, the strategy of generating target items one by one is difficult to achieve optimality because it ignores the information of subsequent items. To address these issues, we propose a utilizing Neighbor Lists model for Generative Reranking (NLGR), which aims to improve the performance of the generator in the combinatorial space. NLGR follows the evaluator-generator paradigm and improves the generator's training and generating methods. Specifically, we use neighbor lists in combination space to enhance the training process, making the generator perceive the relative scores and find the optimization direction. Furthermore, we propose a novel sampling-based non-autoregressive generation method, which allows the generator to jump flexibly from the current list to any neighbor list. Extensive experiments on public and industrial datasets validate NLGR's effectiveness and we have successfully deployed NLGR on the Meituan food delivery platform.
Entire Chain Uplift Modeling with Context-Enhanced Learning for Intelligent Marketing
Feb 04, 2024



Uplift modeling, vital in online marketing, seeks to accurately measure the impact of various strategies, such as coupons or discounts, on different users by predicting the Individual Treatment Effect (ITE). In an e-commerce setting, user behavior follows a defined sequential chain, including impression, click, and conversion. Marketing strategies exert varied uplift effects at each stage within this chain, impacting metrics like click-through and conversion rate. Despite its utility, existing research has neglected to consider the inter-task across all stages impacts within a specific treatment and has insufficiently utilized the treatment information, potentially introducing substantial bias into subsequent marketing decisions. We identify these two issues as the chain-bias problem and the treatment-unadaptive problem. This paper introduces the Entire Chain UPlift method with context-enhanced learning (ECUP), devised to tackle these issues. ECUP consists of two primary components: 1) the Entire Chain-Enhanced Network, which utilizes user behavior patterns to estimate ITE throughout the entire chain space, models the various impacts of treatments on each task, and integrates task prior information to enhance context awareness across all stages, capturing the impact of treatment on different tasks, and 2) the Treatment-Enhanced Network, which facilitates fine-grained treatment modeling through bit-level feature interactions, thereby enabling adaptive feature adjustment. Extensive experiments on public and industrial datasets validate ECUPs effectiveness. Moreover, ECUP has been deployed on the Meituan food delivery platform, serving millions of daily active users, with the related dataset released for future research.