 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-Aware Variational Learning of a Class of Generalized Diffusions
Apr 22, 2026Learning the underlying potential energy of stochastic gradient systems from partial and noisy observations is a fundamental problem arising in physics, chemistry, and data-driven modeling. Classical approaches often rely on direct regression of governing equations or velocity fields, which can be sensitive to noise and external perturbations and may fail when observations are incomplete. In this work, we propose a structure-aware, energy-based learning framework for inferring unknown potential functions in generalized diffusion processes, grounded in the energetic variational approach. Starting from the energy-dissipation law associated with the Fokker-Planck equation, we construct loss functions based on the De Giorgi dissipation functional, which consistently couple the free energy and the dissipation mechanism of the system. This formulation avoids explicit enforcement of the governing partial differential equation and preserves the underlying variational structure of the dynamics. Through numerical experiments in one, two, and three dimensions, we demonstrate that the proposed energy-based loss exhibits enhanced robustness with respect to observation time, noise level, and the diversity and amount of available training data. These results highlight the effectiveness of energy-dissipation principles as a reliable foundation for learning stochastic diffusion dynamics from data.
MambaVSR: Content-Aware Scanning State Space Model for Video Super-Resolution
Jun 13, 2025Video super-resolution (VSR) faces critical challenges in effectively modeling non-local dependencies across misaligned frames while preserving computational efficiency. Existing VSR methods typically rely on optical flow strategies or transformer architectures, which struggle with large motion displacements and long video sequences. To address this, we propose MambaVSR, the first state-space model framework for VSR that incorporates an innovative content-aware scanning mechanism. Unlike rigid 1D sequential processing in conventional vision Mamba methods, our MambaVSR enables dynamic spatiotemporal interactions through the Shared Compass Construction (SCC) and the Content-Aware Sequentialization (CAS). Specifically, the SCC module constructs intra-frame semantic connectivity graphs via efficient sparse attention and generates adaptive spatial scanning sequences through spectral clustering. Building upon SCC, the CAS module effectively aligns and aggregates non-local similar content across multiple frames by interleaving temporal features along the learned spatial order. To bridge global dependencies with local details, the Global-Local State Space Block (GLSSB) synergistically integrates window self-attention operations with SSM-based feature propagation, enabling high-frequency detail recovery under global dependency guidance. Extensive experiments validate MambaVSR's superiority, outperforming the Transformer-based method by 0.58 dB PSNR on the REDS dataset with 55% fewer parameters.
NLGR: Utilizing Neighbor Lists for Generative Rerank in Personalized Recommendation Systems
Feb 10, 2025



Reranking plays a crucial role in modern multi-stage recommender systems by rearranging the initial ranking list. Due to the inherent challenges of combinatorial search spaces, some current research adopts an evaluator-generator paradigm, with a generator generating feasible sequences and an evaluator selecting the best sequence based on the estimated list utility. However, these methods still face two issues. Firstly, due to the goal inconsistency problem between the evaluator and generator, the generator tends to fit the local optimal solution of exposure distribution rather than combinatorial space optimization. Secondly, the strategy of generating target items one by one is difficult to achieve optimality because it ignores the information of subsequent items. To address these issues, we propose a utilizing Neighbor Lists model for Generative Reranking (NLGR), which aims to improve the performance of the generator in the combinatorial space. NLGR follows the evaluator-generator paradigm and improves the generator's training and generating methods. Specifically, we use neighbor lists in combination space to enhance the training process, making the generator perceive the relative scores and find the optimization direction. Furthermore, we propose a novel sampling-based non-autoregressive generation method, which allows the generator to jump flexibly from the current list to any neighbor list. Extensive experiments on public and industrial datasets validate NLGR's effectiveness and we have successfully deployed NLGR on the Meituan food delivery platform.
Honest AI: Fine-Tuning "Small" Language Models to Say "I Don't Know", and Reducing Hallucination in RAG
Oct 13, 2024



Hallucination is a key roadblock for applications of Large Language Models (LLMs), particularly for enterprise applications that are sensitive to information accuracy. To address this issue, two general approaches have been explored: Retrieval-Augmented Generation (RAG) to supply LLMs with updated information as context, and fine-tuning the LLMs with new information and desired output styles. In this paper, we propose Honest AI: a novel strategy to fine-tune "small" language models to say "I don't know" to reduce hallucination, along with several alternative RAG approaches. The solution ranked 1st in Task 2 for the false premise question. The alternative approaches include using RAG with search engine and knowledge graph results, fine-tuning base LLMs with new information and combinations of both approaches. Although all approaches improve the performance of the LLMs, RAG alone does not significantly improve the performance and fine-tuning is needed for better results. Finally, the hybrid approach achieved the highest score in the CRAG benchmark. In addition, our approach emphasizes the use of relatively small models with fewer than 10 billion parameters, promoting resource efficiency.
SeeClear: Semantic Distillation Enhances Pixel Condensation for Video Super-Resolution
Oct 08, 2024Diffusion-based Video Super-Resolution (VSR) is renowned for generating perceptually realistic videos, yet it grapples with maintaining detail consistency across frames due to stochastic fluctuations. The traditional approach of pixel-level alignment is ineffective for diffusion-processed frames because of iterative disruptions. To overcome this, we introduce SeeClear--a novel VSR framework leveraging conditional video generation, orchestrated by instance-centric and channel-wise semantic controls. This framework integrates a Semantic Distiller and a Pixel Condenser, which synergize to extract and upscale semantic details from low-resolution frames. The Instance-Centric Alignment Module (InCAM) utilizes video-clip-wise tokens to dynamically relate pixels within and across frames, enhancing coherency. Additionally, the Channel-wise Texture Aggregation Memory (CaTeGory) infuses extrinsic knowledge, capitalizing on long-standing semantic textures. Our method also innovates the blurring diffusion process with the ResShift mechanism, finely balancing between sharpness and diffusion effects. Comprehensive experiments confirm our framework's advantage over state-of-the-art diffusion-based VSR techniques. The code is available: https://github.com/Tang1705/SeeClear-NeurIPS24.
Semantic Lens: Instance-Centric Semantic Alignment for Video Super-Resolution
Dec 23, 2023



As a critical clue of video super-resolution (VSR), inter-frame alignment significantly impacts overall performance. However, accurate pixel-level alignment is a challenging task due to the intricate motion interweaving in the video. In response to this issue, we introduce a novel paradigm for VSR named Semantic Lens, predicated on semantic priors drawn from degraded videos. Specifically, video is modeled as instances, events, and scenes via a Semantic Extractor. Those semantics assist the Pixel Enhancer in understanding the recovered contents and generating more realistic visual results. The distilled global semantics embody the scene information of each frame, while the instance-specific semantics assemble the spatial-temporal contexts related to each instance. Furthermore, we devise a Semantics-Powered Attention Cross-Embedding (SPACE) block to bridge the pixel-level features with semantic knowledge, composed of a Global Perspective Shifter (GPS) and an Instance-Specific Semantic Embedding Encoder (ISEE). Concretely, the GPS module generates pairs of affine transformation parameters for pixel-level feature modulation conditioned on global semantics. After that, the ISEE module harnesses the attention mechanism to align the adjacent frames in the instance-centric semantic space. In addition, we incorporate a simple yet effective pre-alignment module to alleviate the difficulty of model training. Extensive experiments demonstrate the superiority of our model over existing state-of-the-art VSR methods.
Approximation of nearly-periodic symplectic maps via structure-preserving neural networks
Oct 11, 2022
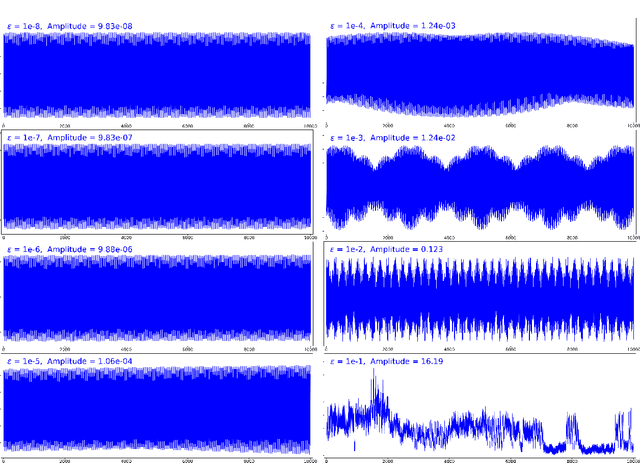

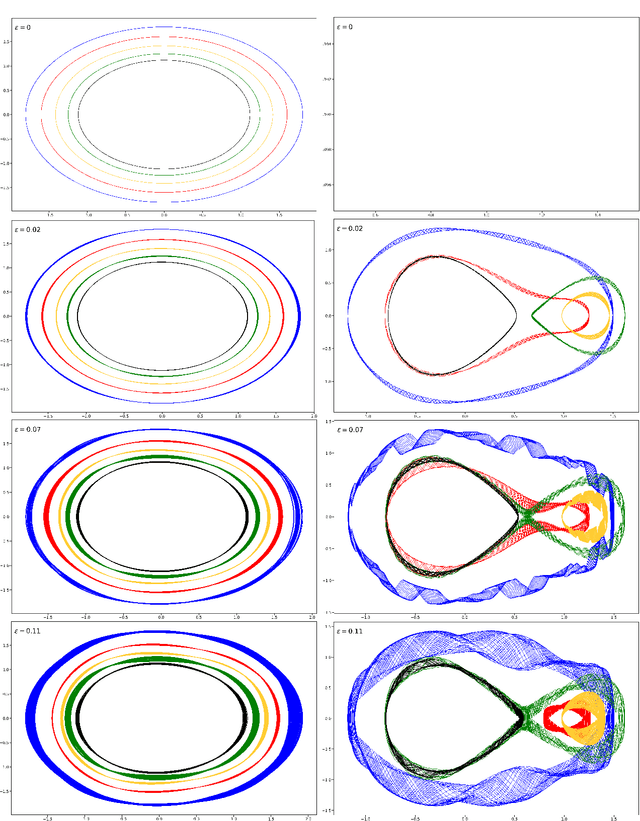
A continuous-time dynamical system with parameter $\varepsilon$ is nearly-periodic if all its trajectories are periodic with nowhere-vanishing angular frequency as $\varepsilon$ approaches 0. Nearly-periodic maps are discrete-time analogues of nearly-periodic systems, defined as parameter-dependent diffeomorphisms that limit to rotations along a circle action, and they admit formal $U(1)$ symmetries to all orders when the limiting rotation is non-resonant. For Hamiltonian nearly-periodic maps on exact presymplectic manifolds, the formal $U(1)$ symmetry gives rise to a discrete-time adiabatic invariant. In this paper, we construct a novel structure-preserving neural network to approximate nearly-periodic symplectic maps. This neural network architecture, which we call symplectic gyroceptron, ensures that the resulting surrogate map is nearly-periodic and symplectic, and that it gives rise to a discrete-time adiabatic invariant and a long-time stability. This new structure-preserving neural network provides a promising architecture for surrogate modeling of non-dissipative dynamical systems that automatically steps over short timescales without introducing spurious instabilities.
Image Translation Based Nuclei Segmentation for Immunohistochemistry Images
Aug 12, 2022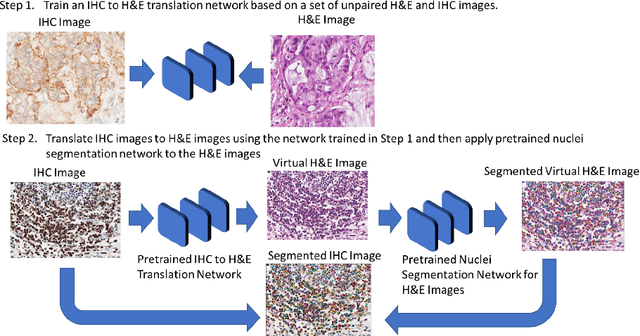
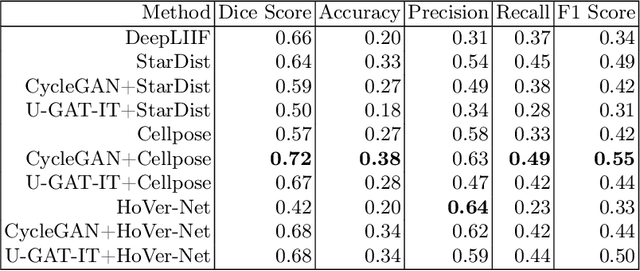
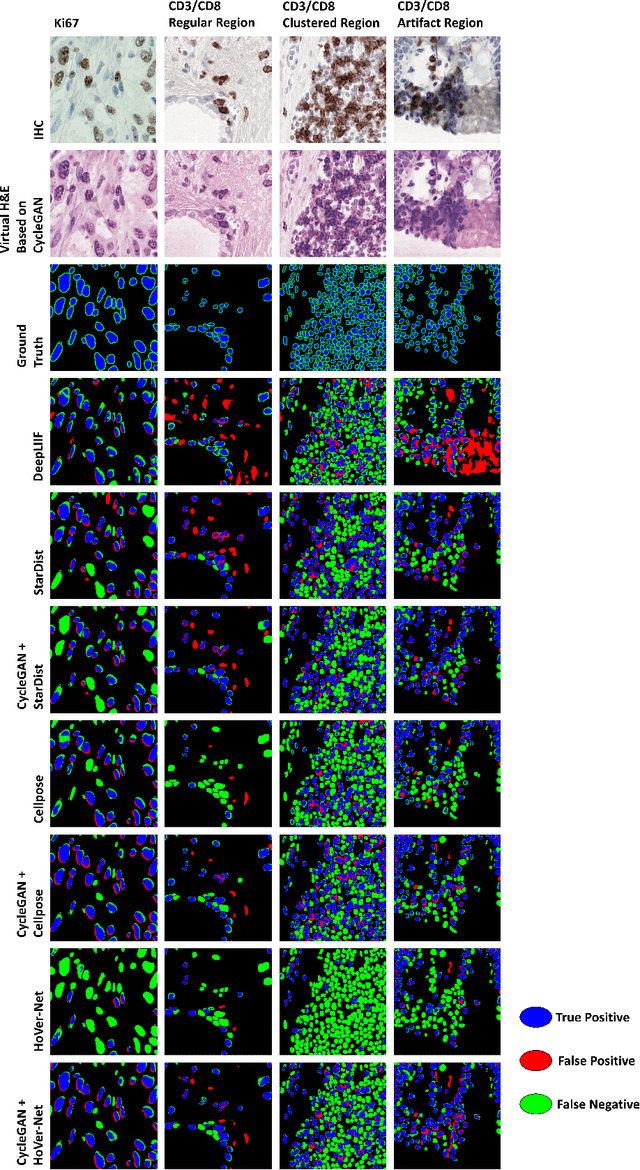
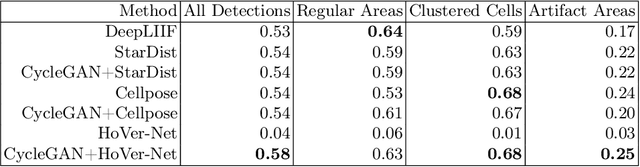
Numerous deep learning based methods have been developed for nuclei segmentation for H&E images and have achieved close to human performance. However, direct application of such methods to another modality of images, such as Immunohistochemistry (IHC) images, may not achieve satisfactory performance. Thus, we developed a Generative Adversarial Network (GAN) based approach to translate an IHC image to an H&E image while preserving nuclei location and morphology and then apply pre-trained nuclei segmentation models to the virtual H&E image. We demonstrated that the proposed methods work better than several baseline methods including direct application of state of the art nuclei segmentation methods such as Cellpose and HoVer-Net, trained on H&E and a generative method, DeepLIIF, using two public IHC image datasets.
Stabilized Neural Ordinary Differential Equations for Long-Time Forecasting of Dynamical Systems
Mar 29, 2022



In data-driven modeling of spatiotemporal phenomena careful consideration often needs to be made in capturing the dynamics of the high wavenumbers. This problem becomes especially challenging when the system of interest exhibits shocks or chaotic dynamics. We present a data-driven modeling method that accurately captures shocks and chaotic dynamics by proposing a novel architecture, stabilized neural ordinary differential equation (ODE). In our proposed architecture, we learn the right-hand-side (RHS) of an ODE by adding the outputs of two NN together where one learns a linear term and the other a nonlinear term. Specifically, we implement this by training a sparse linear convolutional NN to learn the linear term and a dense fully-connected nonlinear NN to learn the nonlinear term. This is in contrast with the standard neural ODE which involves training only a single NN for learning the RHS. We apply this setup to the viscous Burgers equation, which exhibits shocked behavior, and show better short-time tracking and prediction of the energy spectrum at high wavenumbers than a standard neural ODE. We also find that the stabilized neural ODE models are much more robust to noisy initial conditions than the standard neural ODE approach. We also apply this method to chaotic trajectories of the Kuramoto-Sivashinsky equation. In this case, stabilized neural ODEs keep long-time trajectories on the attractor, and are highly robust to noisy initial conditions, while standard neural ODEs fail at achieving either of these results. We conclude by demonstrating how stabilizing neural ODEs provide a natural extension for use in reduced-order modeling by projecting the dynamics onto the eigenvectors of the learned linear term.
Artificial Neural Network and its Application Research Progress in Distillation
Oct 01, 2021Artificial neural networks learn various rules and algorithms to form different ways of processing information, and have been widely used in various chemical processes. Among them, with the development of rectification technology, its production scale continues to expand, and its calculation requirements are also more stringent, because the artificial neural network has the advantages of self-learning, associative storage and high-speed search for optimized solutions, it can make high-precision simulation predictions for rectification operations, so it is widely used in the chemical field of rectification. This article gives a basic overview of artificial neural networks, and introduces the application research of artificial neural networks in distillation at home and abroad.