 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMUGSQA: Novel Multi-Uncertainty-Based Gaussian Splatting Quality Assessment Method, Dataset, and Benchmarks
Nov 10, 2025

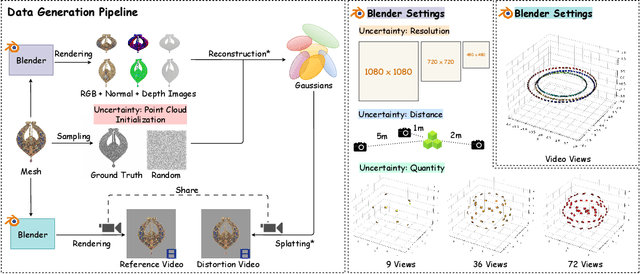
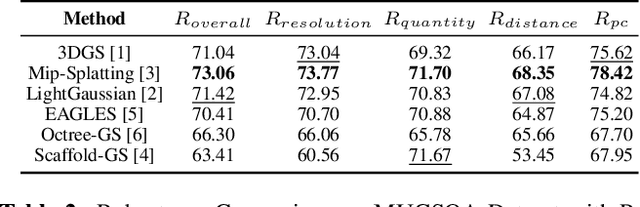
Gaussian Splatting (GS) has recently emerged as a promising technique for 3D object reconstruction, delivering high-quality rendering results with significantly improved reconstruction speed. As variants continue to appear, assessing the perceptual quality of 3D objects reconstructed with different GS-based methods remains an open challenge. To address this issue, we first propose a unified multi-distance subjective quality assessment method that closely mimics human viewing behavior for objects reconstructed with GS-based methods in actual applications, thereby better collecting perceptual experiences. Based on it, we also construct a novel GS quality assessment dataset named MUGSQA, which is constructed considering multiple uncertainties of the input data. These uncertainties include the quantity and resolution of input views, the view distance, and the accuracy of the initial point cloud. Moreover, we construct two benchmarks: one to evaluate the robustness of various GS-based reconstruction methods under multiple uncertainties, and the other to evaluate the performance of existing quality assessment metrics. Our dataset and benchmark code will be released soon.
UGD-IML: A Unified Generative Diffusion-based Framework for Constrained and Unconstrained Image Manipulation Localization
Aug 08, 2025In the digital age, advanced image editing tools pose a serious threat to the integrity of visual content, making image forgery detection and localization a key research focus. Most existing Image Manipulation Localization (IML) methods rely on discriminative learning and require large, high-quality annotated datasets. However, current datasets lack sufficient scale and diversity, limiting model performance in real-world scenarios. To overcome this, recent studies have explored Constrained IML (CIML), which generates pixel-level annotations through algorithmic supervision. However, existing CIML approaches often depend on complex multi-stage pipelines, making the annotation process inefficient. In this work, we propose a novel generative framework based on diffusion models, named UGD-IML, which for the first time unifies both IML and CIML tasks within a single framework. By learning the underlying data distribution, generative diffusion models inherently reduce the reliance on large-scale labeled datasets, allowing our approach to perform effectively even under limited data conditions. In addition, by leveraging a class embedding mechanism and a parameter-sharing design, our model seamlessly switches between IML and CIML modes without extra components or training overhead. Furthermore, the end-to-end design enables our model to avoid cumbersome steps in the data annotation process. Extensive experimental results on multiple datasets demonstrate that UGD-IML outperforms the SOTA methods by an average of 9.66 and 4.36 in terms of F1 metrics for IML and CIML tasks, respectively. Moreover, the proposed method also excels in uncertainty estimation, visualization and robustness.
LatexBlend: Scaling Multi-concept Customized Generation with Latent Textual Blending
Mar 10, 2025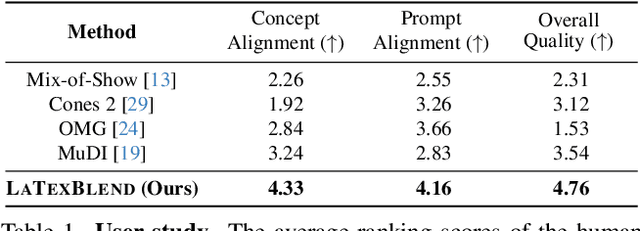
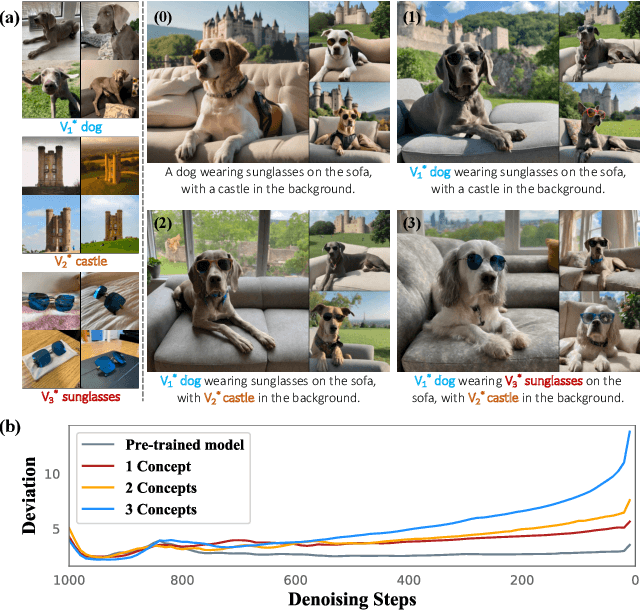
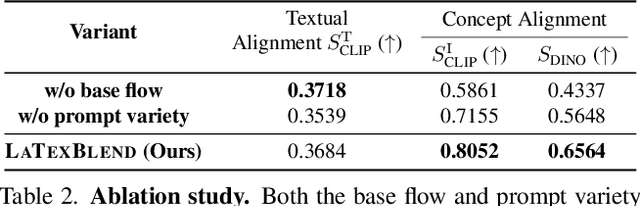
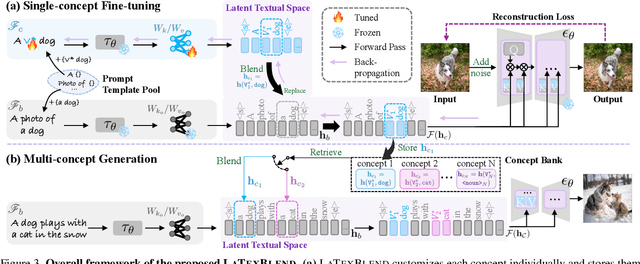
Customized text-to-image generation renders user-specified concepts into novel contexts based on textual prompts. Scaling the number of concepts in customized generation meets a broader demand for user creation, whereas existing methods face challenges with generation quality and computational efficiency. In this paper, we propose LaTexBlend, a novel framework for effectively and efficiently scaling multi-concept customized generation. The core idea of LaTexBlend is to represent single concepts and blend multiple concepts within a Latent Textual space, which is positioned after the text encoder and a linear projection. LaTexBlend customizes each concept individually, storing them in a concept bank with a compact representation of latent textual features that captures sufficient concept information to ensure high fidelity. At inference, concepts from the bank can be freely and seamlessly combined in the latent textual space, offering two key merits for multi-concept generation: 1) excellent scalability, and 2) significant reduction of denoising deviation, preserving coherent layouts. Extensive experiments demonstrate that LaTexBlend can flexibly integrate multiple customized concepts with harmonious structures and high subject fidelity, substantially outperforming baselines in both generation quality and computational efficiency. Our code will be publicly available.
Twofold Debiasing Enhances Fine-Grained Learning with Coarse Labels
Feb 27, 2025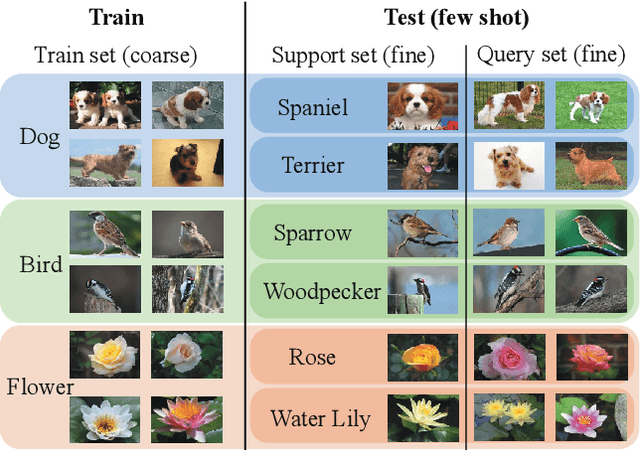
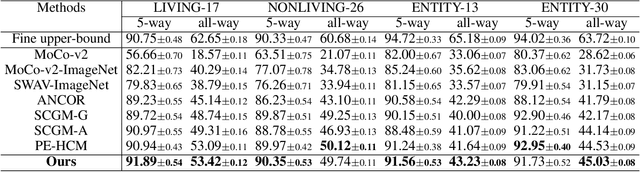
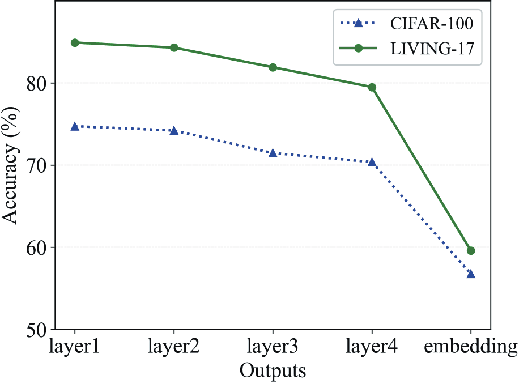
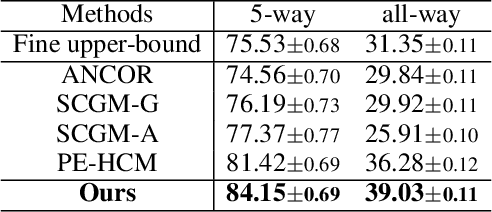
The Coarse-to-Fine Few-Shot (C2FS) task is designed to train models using only coarse labels, then leverages a limited number of subclass samples to achieve fine-grained recognition capabilities. This task presents two main challenges: coarse-grained supervised pre-training suppresses the extraction of critical fine-grained features for subcategory discrimination, and models suffer from overfitting due to biased distributions caused by limited fine-grained samples. In this paper, we propose the Twofold Debiasing (TFB) method, which addresses these challenges through detailed feature enhancement and distribution calibration. Specifically, we introduce a multi-layer feature fusion reconstruction module and an intermediate layer feature alignment module to combat the model's tendency to focus on simple predictive features directly related to coarse-grained supervision, while neglecting complex fine-grained level details. Furthermore, we mitigate the biased distributions learned by the fine-grained classifier using readily available coarse-grained sample embeddings enriched with fine-grained information. Extensive experiments conducted on five benchmark datasets demonstrate the efficacy of our approach, achieving state-of-the-art results that surpass competitive methods.
Noise May Contain Transferable Knowledge: Understanding Semi-supervised Heterogeneous Domain Adaptation from an Empirical Perspective
Feb 19, 2025



Semi-supervised heterogeneous domain adaptation (SHDA) addresses learning across domains with distinct feature representations and distributions, where source samples are labeled while most target samples are unlabeled, with only a small fraction labeled. Moreover, there is no one-to-one correspondence between source and target samples. Although various SHDA methods have been developed to tackle this problem, the nature of the knowledge transferred across heterogeneous domains remains unclear. This paper delves into this question from an empirical perspective. We conduct extensive experiments on about 330 SHDA tasks, employing two supervised learning methods and seven representative SHDA methods. Surprisingly, our observations indicate that both the category and feature information of source samples do not significantly impact the performance of the target domain. Additionally, noise drawn from simple distributions, when used as source samples, may contain transferable knowledge. Based on this insight, we perform a series of experiments to uncover the underlying principles of transferable knowledge in SHDA. Specifically, we design a unified Knowledge Transfer Framework (KTF) for SHDA. Based on the KTF, we find that the transferable knowledge in SHDA primarily stems from the transferability and discriminability of the source domain. Consequently, ensuring those properties in source samples, regardless of their origin (e.g., image, text, noise), can enhance the effectiveness of knowledge transfer in SHDA tasks. The codes and datasets are available at https://github.com/yyyaoyuan/SHDA.
Explanatory Instructions: Towards Unified Vision Tasks Understanding and Zero-shot Generalization
Dec 25, 2024


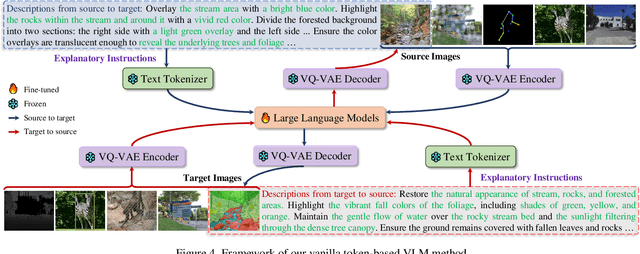
Computer Vision (CV) has yet to fully achieve the zero-shot task generalization observed in Natural Language Processing (NLP), despite following many of the milestones established in NLP, such as large transformer models, extensive pre-training, and the auto-regression paradigm, among others. In this paper, we explore the idea that CV adopts discrete and terminological task definitions (\eg, ``image segmentation''), which may be a key barrier to zero-shot task generalization. Our hypothesis is that without truly understanding previously-seen tasks--due to these terminological definitions--deep models struggle to generalize to novel tasks. To verify this, we introduce Explanatory Instructions, which provide an intuitive way to define CV task objectives through detailed linguistic transformations from input images to outputs. We create a large-scale dataset comprising 12 million ``image input $\to$ explanatory instruction $\to$ output'' triplets, and train an auto-regressive-based vision-language model (AR-based VLM) that takes both images and explanatory instructions as input. By learning to follow these instructions, the AR-based VLM achieves instruction-level zero-shot capabilities for previously-seen tasks and demonstrates strong zero-shot generalization for unseen CV tasks. Code and dataset will be openly available on our GitHub repository.
The Key of Understanding Vision Tasks: Explanatory Instructions
Dec 24, 2024Computer Vision (CV) has yet to fully achieve the zero-shot task generalization observed in Natural Language Processing (NLP), despite following many of the milestones established in NLP, such as large transformer models, extensive pre-training, and the auto-regression paradigm, among others. In this paper, we explore the idea that CV adopts discrete and terminological task definitions (\eg, ``image segmentation''), which may be a key barrier to zero-shot task generalization. Our hypothesis is that without truly understanding previously-seen tasks--due to these terminological definitions--deep models struggle to generalize to novel tasks. To verify this, we introduce Explanatory Instructions, which provide an intuitive way to define CV task objectives through detailed linguistic transformations from input images to outputs. We create a large-scale dataset comprising 12 million ``image input $\to$ explanatory instruction $\to$ output'' triplets, and train an auto-regressive-based vision-language model (AR-based VLM) that takes both images and explanatory instructions as input. By learning to follow these instructions, the AR-based VLM achieves instruction-level zero-shot capabilities for previously-seen tasks and demonstrates strong zero-shot generalization for unseen CV tasks. Code and dataset will be openly available on our GitHub repository.
Customized Generation Reimagined: Fidelity and Editability Harmonized
Dec 06, 2024Customized generation aims to incorporate a novel concept into a pre-trained text-to-image model, enabling new generations of the concept in novel contexts guided by textual prompts. However, customized generation suffers from an inherent trade-off between concept fidelity and editability, i.e., between precisely modeling the concept and faithfully adhering to the prompts. Previous methods reluctantly seek a compromise and struggle to achieve both high concept fidelity and ideal prompt alignment simultaneously. In this paper, we propose a Divide, Conquer, then Integrate (DCI) framework, which performs a surgical adjustment in the early stage of denoising to liberate the fine-tuned model from the fidelity-editability trade-off at inference. The two conflicting components in the trade-off are decoupled and individually conquered by two collaborative branches, which are then selectively integrated to preserve high concept fidelity while achieving faithful prompt adherence. To obtain a better fine-tuned model, we introduce an Image-specific Context Optimization} (ICO) strategy for model customization. ICO replaces manual prompt templates with learnable image-specific contexts, providing an adaptive and precise fine-tuning direction to promote the overall performance. Extensive experiments demonstrate the effectiveness of our method in reconciling the fidelity-editability trade-off.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Rethinking Guidance Information to Utilize Unlabeled Samples:A Label Encoding Perspective
Jun 05, 2024



Empirical Risk Minimization (ERM) is fragile in scenarios with insufficient labeled samples. A vanilla extension of ERM to unlabeled samples is Entropy Minimization (EntMin), which employs the soft-labels of unlabeled samples to guide their learning. However, EntMin emphasizes prediction discriminability while neglecting prediction diversity. To alleviate this issue, in this paper, we rethink the guidance information to utilize unlabeled samples. By analyzing the learning objective of ERM, we find that the guidance information for labeled samples in a specific category is the corresponding label encoding. Inspired by this finding, we propose a Label-Encoding Risk Minimization (LERM). It first estimates the label encodings through prediction means of unlabeled samples and then aligns them with their corresponding ground-truth label encodings. As a result, the LERM ensures both prediction discriminability and diversity, and it can be integrated into existing methods as a plugin. Theoretically, we analyze the relationships between LERM and ERM as well as EntMin. Empirically, we verify the superiority of the LERM under several label insufficient scenarios. The codes are available at https://github.com/zhangyl660/LERM.