 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplanatory Instructions: Towards Unified Vision Tasks Understanding and Zero-shot Generalization
Dec 25, 2024


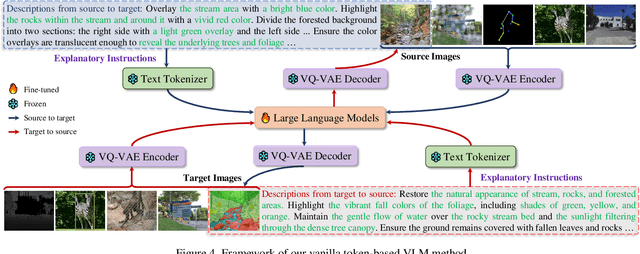
Computer Vision (CV) has yet to fully achieve the zero-shot task generalization observed in Natural Language Processing (NLP), despite following many of the milestones established in NLP, such as large transformer models, extensive pre-training, and the auto-regression paradigm, among others. In this paper, we explore the idea that CV adopts discrete and terminological task definitions (\eg, ``image segmentation''), which may be a key barrier to zero-shot task generalization. Our hypothesis is that without truly understanding previously-seen tasks--due to these terminological definitions--deep models struggle to generalize to novel tasks. To verify this, we introduce Explanatory Instructions, which provide an intuitive way to define CV task objectives through detailed linguistic transformations from input images to outputs. We create a large-scale dataset comprising 12 million ``image input $\to$ explanatory instruction $\to$ output'' triplets, and train an auto-regressive-based vision-language model (AR-based VLM) that takes both images and explanatory instructions as input. By learning to follow these instructions, the AR-based VLM achieves instruction-level zero-shot capabilities for previously-seen tasks and demonstrates strong zero-shot generalization for unseen CV tasks. Code and dataset will be openly available on our GitHub repository.
The Key of Understanding Vision Tasks: Explanatory Instructions
Dec 24, 2024Computer Vision (CV) has yet to fully achieve the zero-shot task generalization observed in Natural Language Processing (NLP), despite following many of the milestones established in NLP, such as large transformer models, extensive pre-training, and the auto-regression paradigm, among others. In this paper, we explore the idea that CV adopts discrete and terminological task definitions (\eg, ``image segmentation''), which may be a key barrier to zero-shot task generalization. Our hypothesis is that without truly understanding previously-seen tasks--due to these terminological definitions--deep models struggle to generalize to novel tasks. To verify this, we introduce Explanatory Instructions, which provide an intuitive way to define CV task objectives through detailed linguistic transformations from input images to outputs. We create a large-scale dataset comprising 12 million ``image input $\to$ explanatory instruction $\to$ output'' triplets, and train an auto-regressive-based vision-language model (AR-based VLM) that takes both images and explanatory instructions as input. By learning to follow these instructions, the AR-based VLM achieves instruction-level zero-shot capabilities for previously-seen tasks and demonstrates strong zero-shot generalization for unseen CV tasks. Code and dataset will be openly available on our GitHub repository.
How Do Your Code LLMs Perform? Empowering Code Instruction Tuning with High-Quality Data
Sep 05, 2024



Recently, there has been a growing interest in studying how to construct better code instruction tuning data. However, we observe Code models trained with these datasets exhibit high performance on HumanEval but perform worse on other benchmarks such as LiveCodeBench. Upon further investigation, we find that many datasets suffer from severe data leakage. After cleaning up most of the leaked data, some well-known high-quality datasets perform poorly. This discovery reveals a new challenge: identifying which dataset genuinely qualify as high-quality code instruction data. To address this, we propose an efficient code data pruning strategy for selecting good samples. Our approach is based on three dimensions: instruction complexity, response quality, and instruction diversity. Based on our selected data, we present XCoder, a family of models finetuned from LLaMA3. Our experiments show XCoder achieves new state-of-the-art performance using fewer training data, which verify the effectiveness of our data strategy. Moreover, we perform a comprehensive analysis on the data composition and find existing code datasets have different characteristics according to their construction methods, which provide new insights for future code LLMs. Our models and dataset are released in https://github.com/banksy23/XCoder