 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Geometry of On-Policy Distillation
Jun 05, 2026On-policy distillation (OPD) is increasingly used to improve large language model reasoning, but its training dynamics remain poorly understood. We characterize the trajectory of OPD updates in parameter space and compare it with supervised fine-tuning (SFT) and reinforcement learning with verifiable rewards (RLVR). A suite of parameter-space diagnostics consistently places OPD in a relaxed off-principal regime: compared with SFT, its updates affect fewer weights and avoid principal directions more strongly, while compared with RLVR, they remain less tightly constrained. Beyond this static localization, OPD exhibits subspace locking: its cumulative updates rapidly enter a narrow low-dimensional channel. Constraining training to the update subspace formed early in training preserves OPD performance but substantially degrades SFT, indicating that the locked subspace is functionally sufficient for OPD. Control experiments further show that sparsifying the update tokens and shifting rollout generation off-policy preserve the rank dynamics, whereas mixing the OPD objective with RLVR changes them. Overall, these results suggest that OPD is not merely an intermediate point between SFT and RLVR, but induces its own update geometry in parameter space.
Select-then-Solve: Paradigm Routing as Inference-Time Optimization for LLM Agents
Apr 08, 2026When an LLM-based agent improves on a task, is the gain from the model itself or from the reasoning paradigm wrapped around it? We study this question by comparing six inference-time paradigms, namely Direct, CoT, ReAct, Plan-Execute, Reflection, and ReCode, across four frontier LLMs and ten benchmarks, yielding roughly 18,000 runs. We find that reasoning structure helps dramatically on some tasks but hurts on others: ReAct improves over Direct by 44pp on GAIA, while CoT degrades performance by 15pp on HumanEval. No single paradigm dominates, and oracle per-task selection beats the best fixed paradigm by 17.1pp on average. Motivated by this complementarity, we propose a select-then-solve approach: before answering each task, a lightweight embedding-based router selects the most suitable paradigm. Across four models, the router improves average accuracy from 47.6% to 53.1%, outperforming the best fixed paradigm at 50.3% by 2.8pp and recovering up to 37% of the oracle gap. In contrast, zero-shot self-routing only works for GPT-5 at 67.1% and fails for weaker models, all trailing the learned router. Our results argue that reasoning paradigm selection should be a per-task decision made by a learned router, not a fixed architectural choice.
JoyAI-LLM Flash: Advancing Mid-Scale LLMs with Token Efficiency
Apr 03, 2026We introduce JoyAI-LLM Flash, an efficient Mixture-of-Experts (MoE) language model designed to redefine the trade-off between strong performance and token efficiency in the sub-50B parameter regime. JoyAI-LLM Flash is pretrained on a massive corpus of 20 trillion tokens and further optimized through a rigorous post-training pipeline, including supervised fine-tuning (SFT), Direct Preference Optimization (DPO), and large-scale reinforcement learning (RL) across diverse environments. To improve token efficiency, JoyAI-LLM Flash strategically balances \emph{thinking} and \emph{non-thinking} cognitive modes and introduces FiberPO, a novel RL algorithm inspired by fibration theory that decomposes trust-region maintenance into global and local components, providing unified multi-scale stability control for LLM policy optimization. To enhance architectural sparsity, the model comprises 48B total parameters while activating only 2.7B parameters per forward pass, achieving a substantially higher sparsity ratio than contemporary industry leading models of comparable scale. To further improve inference throughput, we adopt a joint training-inference co-design that incorporates dense Multi-Token Prediction (MTP) and Quantization-Aware Training (QAT). We release the checkpoints for both JoyAI-LLM-48B-A3B Base and its post-trained variants on Hugging Face to support the open-source community.
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
StockBench: Can LLM Agents Trade Stocks Profitably In Real-world Markets?
Oct 02, 2025Large language models (LLMs) have recently demonstrated strong capabilities as autonomous agents, showing promise in reasoning, tool use, and sequential decision-making. While prior benchmarks have evaluated LLM agents in domains such as software engineering and scientific discovery, the finance domain remains underexplored, despite its direct relevance to economic value and high-stakes decision-making. Existing financial benchmarks primarily test static knowledge through question answering, but they fall short of capturing the dynamic and iterative nature of trading. To address this gap, we introduce StockBench, a contamination-free benchmark designed to evaluate LLM agents in realistic, multi-month stock trading environments. Agents receive daily market signals -- including prices, fundamentals, and news -- and must make sequential buy, sell, or hold decisions. Performance is assessed using financial metrics such as cumulative return, maximum drawdown, and the Sortino ratio. Our evaluation of state-of-the-art proprietary (e.g., GPT-5, Claude-4) and open-weight (e.g., Qwen3, Kimi-K2, GLM-4.5) models shows that while most LLM agents struggle to outperform the simple buy-and-hold baseline, several models demonstrate the potential to deliver higher returns and manage risk more effectively. These findings highlight both the challenges and opportunities in developing LLM-powered financial agents, showing that excelling at static financial knowledge tasks does not necessarily translate into successful trading strategies. We release StockBench as an open-source resource to support reproducibility and advance future research in this domain.
Tracing Facts or just Copies? A critical investigation of the Competitions of Mechanisms in Large Language Models
Jul 16, 2025
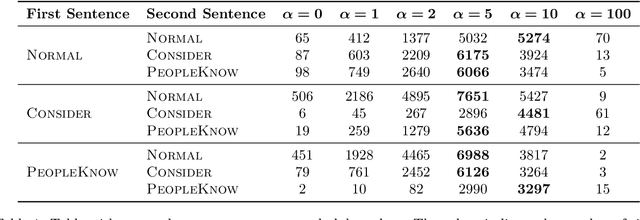
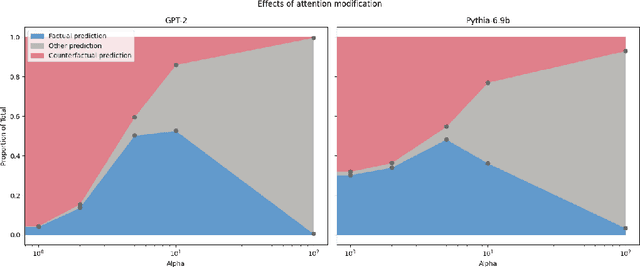
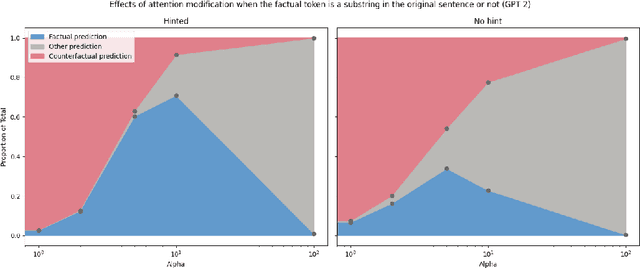
This paper presents a reproducibility study examining how Large Language Models (LLMs) manage competing factual and counterfactual information, focusing on the role of attention heads in this process. We attempt to reproduce and reconcile findings from three recent studies by Ortu et al., Yu, Merullo, and Pavlick and McDougall et al. that investigate the competition between model-learned facts and contradictory context information through Mechanistic Interpretability tools. Our study specifically examines the relationship between attention head strength and factual output ratios, evaluates competing hypotheses about attention heads' suppression mechanisms, and investigates the domain specificity of these attention patterns. Our findings suggest that attention heads promoting factual output do so via general copy suppression rather than selective counterfactual suppression, as strengthening them can also inhibit correct facts. Additionally, we show that attention head behavior is domain-dependent, with larger models exhibiting more specialized and category-sensitive patterns.
* 18 Pages, 13 figures
Are Reasoning Models More Prone to Hallucination?
May 29, 2025Recently evolved large reasoning models (LRMs) show powerful performance in solving complex tasks with long chain-of-thought (CoT) reasoning capability. As these LRMs are mostly developed by post-training on formal reasoning tasks, whether they generalize the reasoning capability to help reduce hallucination in fact-seeking tasks remains unclear and debated. For instance, DeepSeek-R1 reports increased performance on SimpleQA, a fact-seeking benchmark, while OpenAI-o3 observes even severer hallucination. This discrepancy naturally raises the following research question: Are reasoning models more prone to hallucination? This paper addresses the question from three perspectives. (1) We first conduct a holistic evaluation for the hallucination in LRMs. Our analysis reveals that LRMs undergo a full post-training pipeline with cold start supervised fine-tuning (SFT) and verifiable reward RL generally alleviate their hallucination. In contrast, both distillation alone and RL training without cold start fine-tuning introduce more nuanced hallucinations. (2) To explore why different post-training pipelines alters the impact on hallucination in LRMs, we conduct behavior analysis. We characterize two critical cognitive behaviors that directly affect the factuality of a LRM: Flaw Repetition, where the surface-level reasoning attempts repeatedly follow the same underlying flawed logic, and Think-Answer Mismatch, where the final answer fails to faithfully match the previous CoT process. (3) Further, we investigate the mechanism behind the hallucination of LRMs from the perspective of model uncertainty. We find that increased hallucination of LRMs is usually associated with the misalignment between model uncertainty and factual accuracy. Our work provides an initial understanding of the hallucination in LRMs.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
How Do Your Code LLMs Perform? Empowering Code Instruction Tuning with High-Quality Data
Sep 05, 2024



Recently, there has been a growing interest in studying how to construct better code instruction tuning data. However, we observe Code models trained with these datasets exhibit high performance on HumanEval but perform worse on other benchmarks such as LiveCodeBench. Upon further investigation, we find that many datasets suffer from severe data leakage. After cleaning up most of the leaked data, some well-known high-quality datasets perform poorly. This discovery reveals a new challenge: identifying which dataset genuinely qualify as high-quality code instruction data. To address this, we propose an efficient code data pruning strategy for selecting good samples. Our approach is based on three dimensions: instruction complexity, response quality, and instruction diversity. Based on our selected data, we present XCoder, a family of models finetuned from LLaMA3. Our experiments show XCoder achieves new state-of-the-art performance using fewer training data, which verify the effectiveness of our data strategy. Moreover, we perform a comprehensive analysis on the data composition and find existing code datasets have different characteristics according to their construction methods, which provide new insights for future code LLMs. Our models and dataset are released in https://github.com/banksy23/XCoder
Applications and Advances of Artificial Intelligence in Music Generation:A Review
Sep 03, 2024



In recent years, artificial intelligence (AI) has made significant progress in the field of music generation, driving innovation in music creation and applications. This paper provides a systematic review of the latest research advancements in AI music generation, covering key technologies, models, datasets, evaluation methods, and their practical applications across various fields. The main contributions of this review include: (1) presenting a comprehensive summary framework that systematically categorizes and compares different technological approaches, including symbolic generation, audio generation, and hybrid models, helping readers better understand the full spectrum of technologies in the field; (2) offering an extensive survey of current literature, covering emerging topics such as multimodal datasets and emotion expression evaluation, providing a broad reference for related research; (3) conducting a detailed analysis of the practical impact of AI music generation in various application domains, particularly in real-time interaction and interdisciplinary applications, offering new perspectives and insights; (4) summarizing the existing challenges and limitations of music quality evaluation methods and proposing potential future research directions, aiming to promote the standardization and broader adoption of evaluation techniques. Through these innovative summaries and analyses, this paper serves as a comprehensive reference tool for researchers and practitioners in AI music generation, while also outlining future directions for the field.