 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTagLLM: A Fine-Grained Tag Generation Approach for Note Recommendation
Mar 23, 2026Large Language Models (LLMs) have shown promising potential in E-commerce community recommendation. While LLMs and Multimodal LLMs (MLLMs) are widely used to encode notes into implicit embeddings, leveraging their generative capabilities to represent notes with interpretable tags remains unexplored. In the field of tag generation, traditional close-ended methods heavily rely on the design of tag pools, while existing open-ended methods applied directly to note recommendations face two limitations: (1) MLLMs lack guidance during generation, resulting in redundant tags that fail to capture user interests; (2) The generated tags are often coarse and lack fine-grained representation of notes, interfering with downstream recommendations. To address these limitations, we propose TagLLM, a fine-grained tag generation method for note recommendation. TagLLM captures user interests across note categories through a User Interest Handbook and constructs fine-grained tag data using multimodal CoT Extraction. A Tag Knowledge Distillation method is developed to equip small models with competitive generation capabilities, enhancing inference efficiency. In online A/B test, TagLLM increases average view duration per user by 0.31%, average interactions per user by 0.96%, and page view click-through rate in cold-start scenario by 32.37%, demonstrating its effectiveness.
Differentiable Geometric Indexing for End-to-End Generative Retrieval
Mar 11, 2026Generative Retrieval (GR) has emerged as a promising paradigm to unify indexing and search within a single probabilistic framework. However, existing approaches suffer from two intrinsic conflicts: (1) an Optimization Blockage, where the non-differentiable nature of discrete indexing creates a gradient blockage, decoupling index construction from the downstream retrieval objective; and (2) a Geometric Conflict, where standard unnormalized inner-product objectives induce norm-inflation instability, causing popular "hub" items to geometrically overshadow relevant long-tail items. To systematically resolve these misalignments, we propose Differentiable Geometric Indexing (DGI). First, to bridge the optimization gap, DGI enforces Operational Unification. It employs Soft Teacher Forcing via Gumbel-Softmax to establish a fully differentiable pathway, combined with Symmetric Weight Sharing to effectively align the quantizer's indexing space with the retriever's decoding space. Second, to restore geometric fidelity, DGI introduces Isotropic Geometric Optimization. We replace inner-product logits with scaled cosine similarity on the unit hypersphere to effectively decouple popularity bias from semantic relevance. Extensive experiments on large-scale industry search datasets and online e-commerce platform demonstrate that DGI outperforms competitive sparse, dense, and generative baselines. Notably, DGI exhibits superior robustness in long-tail scenarios, validating the necessity of harmonizing structural differentiability with geometric isotropy.
Thinking Broad, Acting Fast: Latent Reasoning Distillation from Multi-Perspective Chain-of-Thought for E-Commerce Relevance
Jan 29, 2026Effective relevance modeling is crucial for e-commerce search, as it aligns search results with user intent and enhances customer experience. Recent work has leveraged large language models (LLMs) to address the limitations of traditional relevance models, especially for long-tail and ambiguous queries. By incorporating Chain-of-Thought (CoT) reasoning, these approaches improve both accuracy and interpretability through multi-step reasoning. However, two key limitations remain: (1) most existing approaches rely on single-perspective CoT reasoning, which fails to capture the multifaceted nature of e-commerce relevance (e.g., user intent vs. attribute-level matching vs. business-specific rules); and (2) although CoT-enhanced LLM's offer rich reasoning capabilities, their high inference latency necessitates knowledge distillation for real-time deployment, yet current distillation methods discard the CoT rationale structure at inference, using it as a transient auxiliary signal and forfeiting its reasoning utility. To address these challenges, we propose a novel framework that better exploits CoT semantics throughout the optimization pipeline. Specifically, the teacher model leverages Multi-Perspective CoT (MPCoT) to generate diverse rationales and combines Supervised Fine-Tuning (SFT) with Direct Preference Optimization (DPO) to construct a more robust reasoner. For distillation, we introduce Latent Reasoning Knowledge Distillation (LRKD), which endows a student model with a lightweight inference-time latent reasoning extractor, allowing efficient and low-latency internalization of the LLM's sophisticated reasoning capabilities. Evaluated in offline experiments and online A/B tests on an e-commerce search advertising platform serving tens of millions of users daily, our method delivers significant offline gains, showing clear benefits in both commercial performance and user experience.
Astra: Toward General-Purpose Mobile Robots via Hierarchical Multimodal Learning
Jun 06, 2025Modern robot navigation systems encounter difficulties in diverse and complex indoor environments. Traditional approaches rely on multiple modules with small models or rule-based systems and thus lack adaptability to new environments. To address this, we developed Astra, a comprehensive dual-model architecture, Astra-Global and Astra-Local, for mobile robot navigation. Astra-Global, a multimodal LLM, processes vision and language inputs to perform self and goal localization using a hybrid topological-semantic graph as the global map, and outperforms traditional visual place recognition methods. Astra-Local, a multitask network, handles local path planning and odometry estimation. Its 4D spatial-temporal encoder, trained through self-supervised learning, generates robust 4D features for downstream tasks. The planning head utilizes flow matching and a novel masked ESDF loss to minimize collision risks for generating local trajectories, and the odometry head integrates multi-sensor inputs via a transformer encoder to predict the relative pose of the robot. Deployed on real in-house mobile robots, Astra achieves high end-to-end mission success rate across diverse indoor environments.
Low-Complex Waveform, Modulation and Coding Designs for 3GPP Ambient IoT
Jan 15, 2025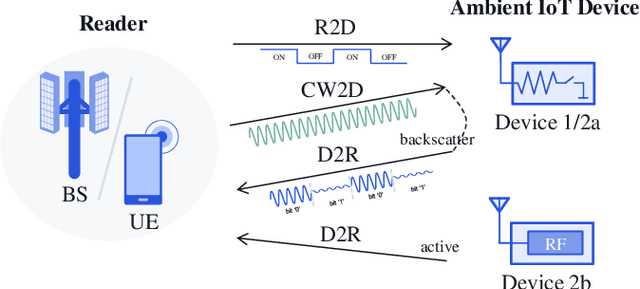
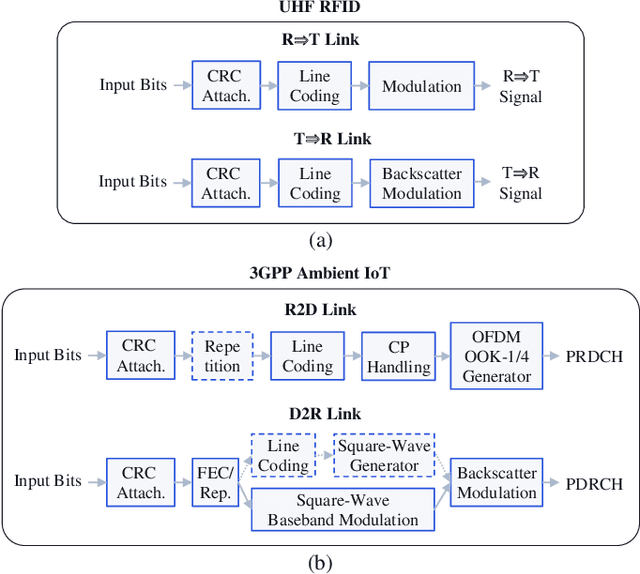
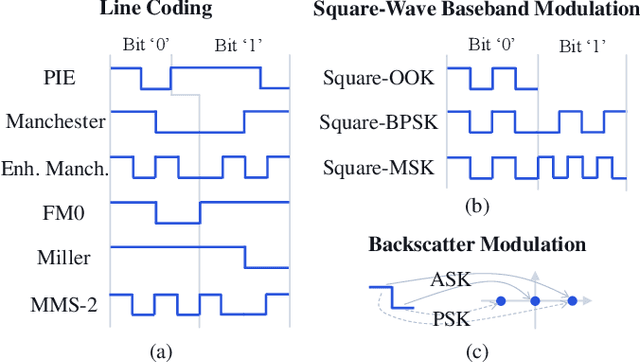
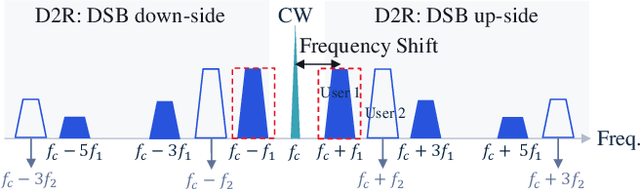
This paper presents a comprehensive study on low-complexity waveform, modulation and coding (WMC) designs for the 3rd Generation Partnership Project (3GPP) Ambient Internet of Things (A-IoT). A-IoT is a low-cost, low-power IoT system inspired by Ultra High Frequency (UHF) Radio Frequency Identification (RFID) and aims to leverage existing cellular network infrastructure for efficient RF tag management. The paper compares the physical layer (PHY) design challenges and requirements of RFID and A-IoT, particularly focusing on backscatter communications. An overview of the standardization for PHY designs in Release 19 A-IoT is provided, along with detailed schemes of the proposed low-complex WMC designs. The performance of device-to-reader link designs is validated through simulations, demonstrating 6 dB improvements of the proposed baseband waveform with coherent receivers compared to RFID line coding-based solutions with non-coherent receivers when channel coding is adopted.
Preference as Reward, Maximum Preference Optimization with Importance Sampling
Jan 08, 2024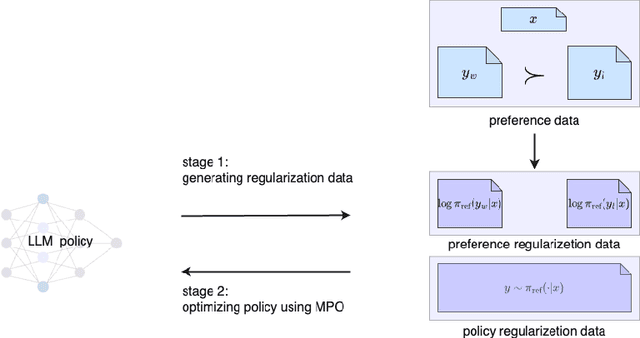
Preference learning is a key technology for aligning language models with human values. Reinforcement Learning from Human Feedback (RLHF) is a model based algorithm to optimize preference learning, which first fitting a reward model for preference score, and then optimizing generating policy with on-policy PPO algorithm to maximize the reward. The processing of RLHF is complex, time-consuming and unstable. Direct Preference Optimization (DPO) algorithm using off-policy algorithm to direct optimize generating policy and eliminating the need for reward model, which is data efficient and stable. DPO use Bradley-Terry model and log-loss which leads to over-fitting to the preference data at the expense of ignoring KL-regularization term when preference is deterministic. IPO uses a root-finding MSE loss to solve the ignoring KL-regularization problem. In this paper, we'll figure out, although IPO fix the problem when preference is deterministic, but both DPO and IPO fails the KL-regularization term because the support of preference distribution not equal to reference distribution. Then, we design a simple and intuitive off-policy preference optimization algorithm from an importance sampling view, which we call Maximum Preference Optimization (MPO), and add off-policy KL-regularization terms which makes KL-regularization truly effective. The objective of MPO bears resemblance to RLHF's objective, and likes IPO, MPO is off-policy. So, MPO attains the best of both worlds. To simplify the learning process and save memory usage, MPO eliminates the needs for both reward model and reference policy.
Framework for Quality Evaluation of Smart Roadside Infrastructure Sensors for Automated Driving Applications
Apr 16, 2023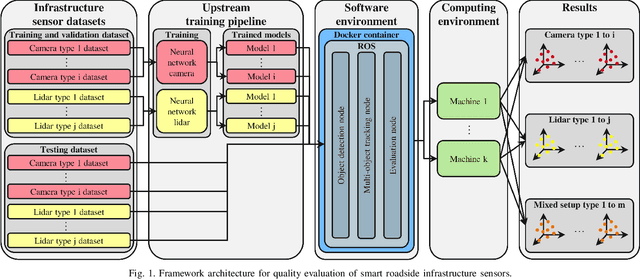
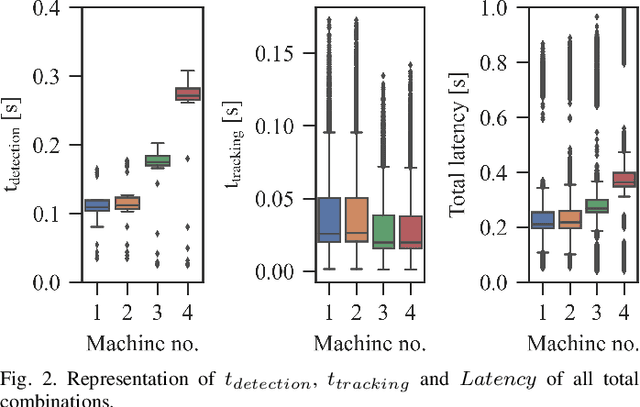
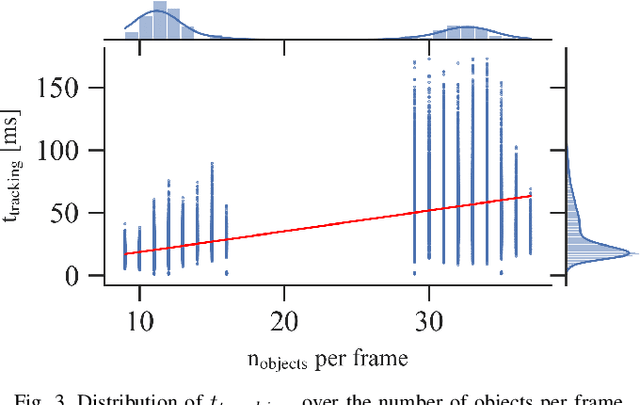
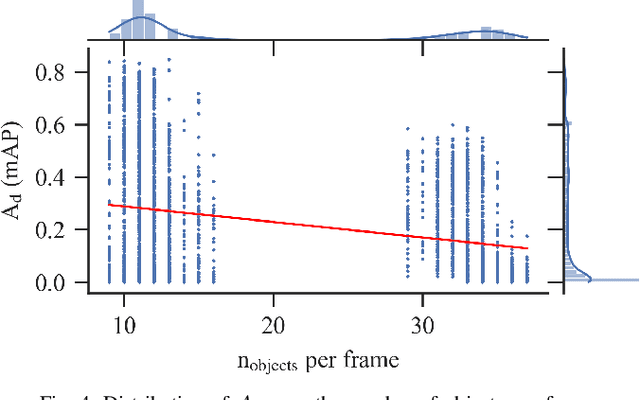
The use of smart roadside infrastructure sensors is highly relevant for future applications of connected and automated vehicles. External sensor technology in the form of intelligent transportation system stations (ITS-Ss) can provide safety-critical real-time information about road users in the form of a digital twin. The choice of sensor setups has a major influence on the downstream function as well as the data quality. To date, there is insufficient research on which sensor setups result in which levels of ITS-S data quality. We present a novel approach to perform detailed quality assessment for smart roadside infrastructure sensors. Our framework is multimodal across different sensor types and is evaluated on the DAIR-V2X dataset. We analyze the composition of different lidar and camera sensors and assess them in terms of accuracy, latency, and reliability. The evaluations show that the framework can be used reliably for several future ITS-S applications.
ACE-BERT: Adversarial Cross-modal Enhanced BERT for E-commerce Retrieval
Dec 14, 2021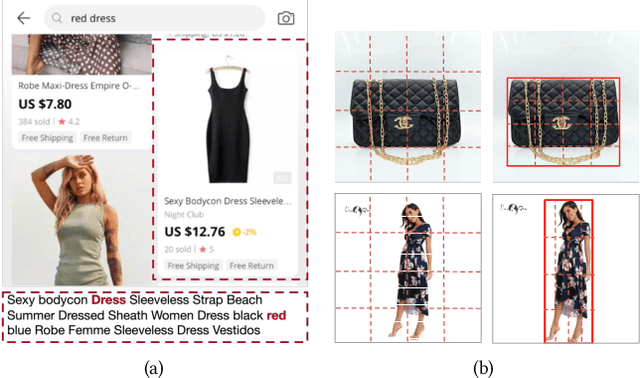

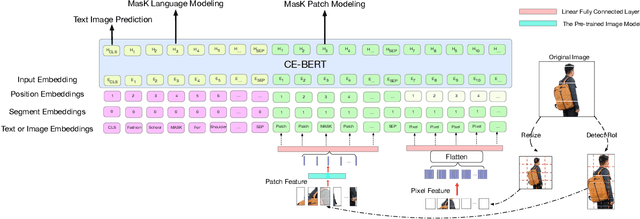

Nowadays on E-commerce platforms, products are presented to the customers with multiple modalities. These multiple modalities are significant for a retrieval system while providing attracted products for customers. Therefore, how to take into account those multiple modalities simultaneously to boost the retrieval performance is crucial. This problem is a huge challenge to us due to the following reasons: (1) the way of extracting patch features with the pre-trained image model (e.g., CNN-based model) has much inductive bias. It is difficult to capture the efficient information from the product image in E-commerce. (2) The heterogeneity of multimodal data makes it challenging to construct the representations of query text and product including title and image in a common subspace. We propose a novel Adversarial Cross-modal Enhanced BERT (ACE-BERT) for efficient E-commerce retrieval. In detail, ACE-BERT leverages the patch features and pixel features as image representation. Thus the Transformer architecture can be applied directly to the raw image sequences. With the pre-trained enhanced BERT as the backbone network, ACE-BERT further adopts adversarial learning by adding a domain classifier to ensure the distribution consistency of different modality representations for the purpose of narrowing down the representation gap between query and product. Experimental results demonstrate that ACE-BERT outperforms the state-of-the-art approaches on the retrieval task. It is remarkable that ACE-BERT has already been deployed in our E-commerce's search engine, leading to 1.46% increase in revenue.
Learning based Predictive Error Estimation and Compensator Design for Autonomous Vehicle Path Tracking
Jul 18, 2020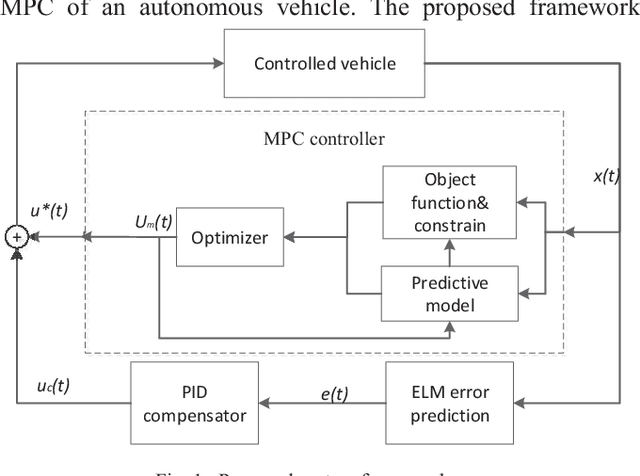
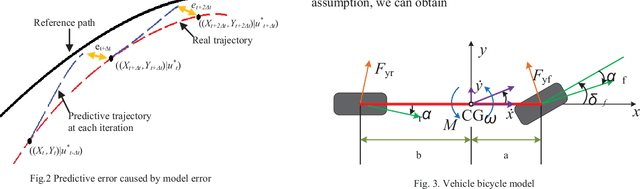
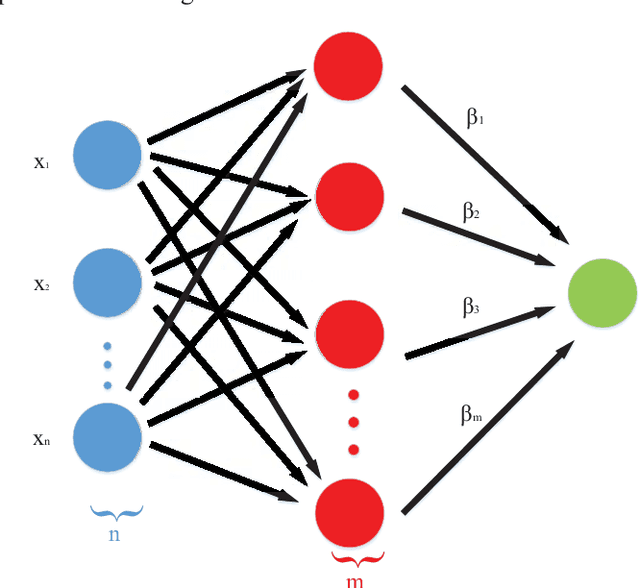
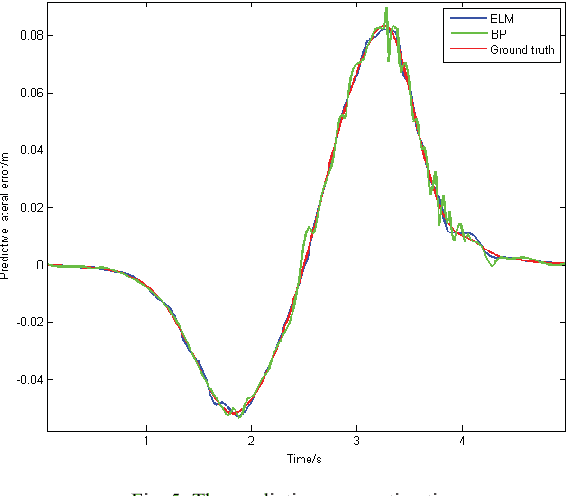
Model predictive control (MPC) is widely used for path tracking of autonomous vehicles due to its ability to handle various types of constraints. However, a considerable predictive error exists because of the error of mathematics model or the model linearization. In this paper, we propose a framework combining the MPC with a learning-based error estimator and a feedforward compensator to improve the path tracking accuracy. An extreme learning machine is implemented to estimate the model based predictive error from vehicle state feedback information. Offline training data is collected from a vehicle controlled by a model-defective regular MPC for path tracking in several working conditions, respectively. The data include vehicle state and the spatial error between the current actual position and the corresponding predictive position. According to the estimated predictive error, we then design a PID-based feedforward compensator. Simulation results via Carsim show the estimation accuracy of the predictive error and the effectiveness of the proposed framework for path tracking of an autonomous vehicle.
Optimal Delivery with Budget Constraint in E-Commerce Advertising
Oct 08, 2019


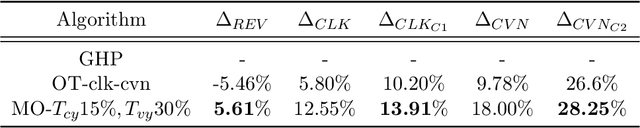
Online advertising in E-commerce platforms provides sellers an opportunity to achieve potential audiences with different target goals. Ad serving systems (like display and search advertising systems) that assign ads to pages should satisfy objectives such as plenty of audience for branding advertisers, clicks or conversions for performance-based advertisers, at the same time try to maximize overall revenue of the platform. In this paper, we propose an approach based on linear programming subjects to constraints in order to optimize the revenue and improve different performance goals simultaneously. We have validated our algorithm by implementing an offline simulation system in Alibaba E-commerce platform and running the auctions from online requests which takes system performance, ranking and pricing schemas into account. We have also compared our algorithm with related work, and the results show that our algorithm can effectively improve campaign performance and revenue of the platform.