 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal and Contrastive Learning for Click Fraud Detection
May 08, 2021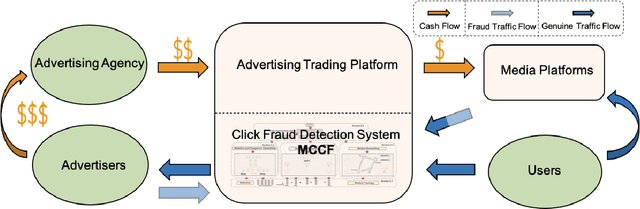
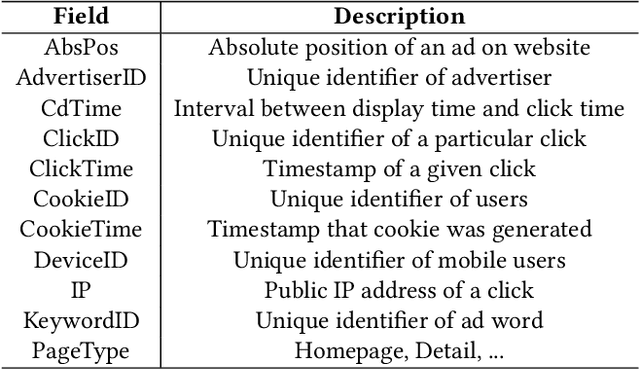
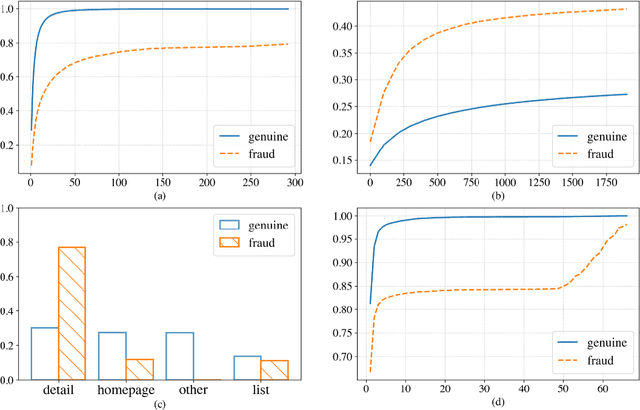

Advertising click fraud detection plays one of the vital roles in current E-commerce websites as advertising is an essential component of its business model. It aims at, given a set of corresponding features, e.g., demographic information of users and statistical features of clicks, predicting whether a click is fraudulent or not in the community. Recent efforts attempted to incorporate attributed behavior sequence and heterogeneous network for extracting complex features of users and achieved significant effects on click fraud detection. In this paper, we propose a Multimodal and Contrastive learning network for Click Fraud detection (MCCF). Specifically, motivated by the observations on differences of demographic information, behavior sequences and media relationship between fraudsters and genuine users on E-commerce platform, MCCF jointly utilizes wide and deep features, behavior sequence and heterogeneous network to distill click representations. Moreover, these three modules are integrated by contrastive learning and collaboratively contribute to the final predictions. With the real-world datasets containing 2.54 million clicks on Alibaba platform, we investigate the effectiveness of MCCF. The experimental results show that the proposed approach is able to improve AUC by 7.2% and F1-score by 15.6%, compared with the state-of-the-art methods.
Transformer-based Language Model Fine-tuning Methods for COVID-19 Fake News Detection
Jan 18, 2021
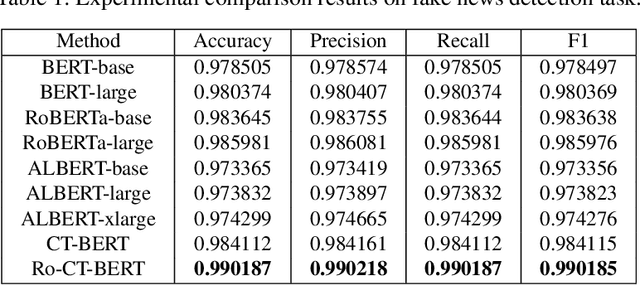
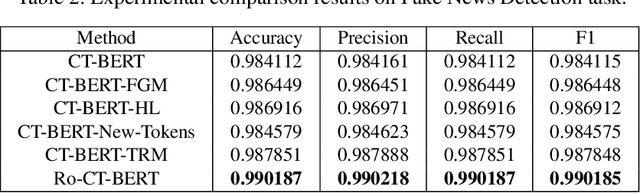
With the pandemic of COVID-19, relevant fake news is spreading all over the sky throughout the social media. Believing in them without discrimination can cause great trouble to people's life. However, universal language models may perform weakly in these fake news detection for lack of large-scale annotated data and sufficient semantic understanding of domain-specific knowledge. While the model trained on corresponding corpora is also mediocre for insufficient learning. In this paper, we propose a novel transformer-based language model fine-tuning approach for these fake news detection. First, the token vocabulary of individual model is expanded for the actual semantics of professional phrases. Second, we adapt the heated-up softmax loss to distinguish the hard-mining samples, which are common for fake news because of the disambiguation of short text. Then, we involve adversarial training to improve the model's robustness. Last, the predicted features extracted by universal language model RoBERTa and domain-specific model CT-BERT are fused by one multiple layer perception to integrate fine-grained and high-level specific representations. Quantitative experimental results evaluated on existing COVID-19 fake news dataset show its superior performances compared to the state-of-the-art methods among various evaluation metrics. Furthermore, the best weighted average F1 score achieves 99.02%.
Time-aware Graph Embedding: A temporal smoothness and task-oriented approach
Jul 22, 2020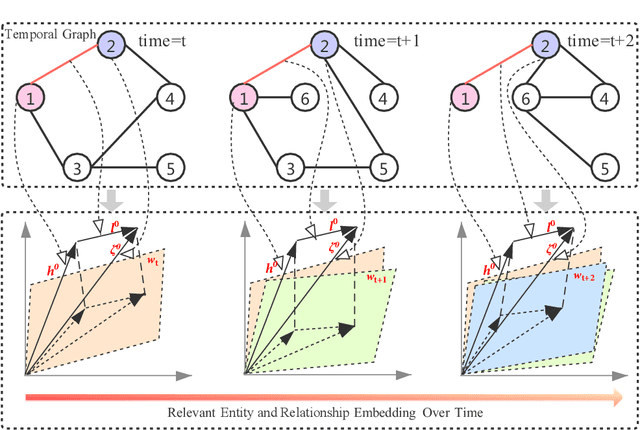

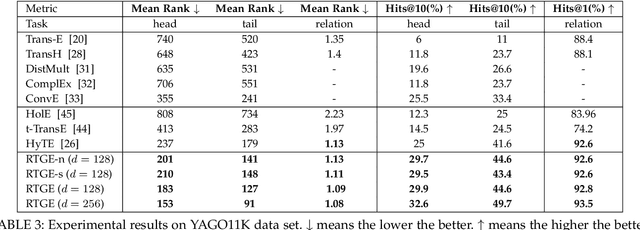
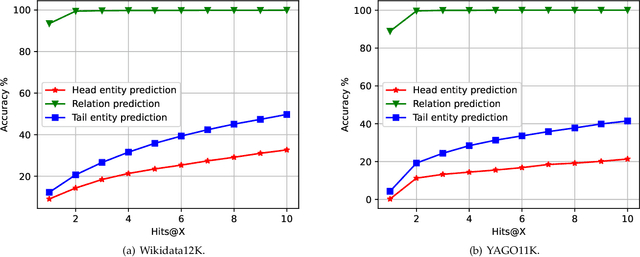
Knowledge graph embedding, which aims to learn the low-dimensional representations of entities and relationships, has attracted considerable research efforts recently. However, most knowledge graph embedding methods focus on the structural relationships in fixed triples while ignoring the temporal information. Currently, existing time-aware graph embedding methods only focus on the factual plausibility, while ignoring the temporal smoothness which models the interactions between a fact and its contexts, and thus can capture fine-granularity temporal relationships. This leads to the limited performance of embedding related applications. To solve this problem, this paper presents a Robustly Time-aware Graph Embedding (RTGE) method by incorporating temporal smoothness. Two major innovations of our paper are presented here. At first, RTGE integrates a measure of temporal smoothness in the learning process of the time-aware graph embedding. Via the proposed additional smoothing factor, RTGE can preserve both structural information and evolutionary patterns of a given graph. Secondly, RTGE provides a general task-oriented negative sampling strategy associated with temporally-aware information, which further improves the adaptive ability of the proposed algorithm and plays an essential role in obtaining superior performance in various tasks. Extensive experiments conducted on multiple benchmark tasks show that RTGE can increase performance in entity/relationship/temporal scoping prediction tasks.
Optimal Delivery with Budget Constraint in E-Commerce Advertising
Oct 08, 2019


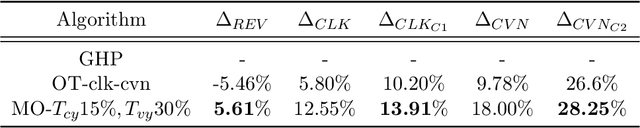
Online advertising in E-commerce platforms provides sellers an opportunity to achieve potential audiences with different target goals. Ad serving systems (like display and search advertising systems) that assign ads to pages should satisfy objectives such as plenty of audience for branding advertisers, clicks or conversions for performance-based advertisers, at the same time try to maximize overall revenue of the platform. In this paper, we propose an approach based on linear programming subjects to constraints in order to optimize the revenue and improve different performance goals simultaneously. We have validated our algorithm by implementing an offline simulation system in Alibaba E-commerce platform and running the auctions from online requests which takes system performance, ranking and pricing schemas into account. We have also compared our algorithm with related work, and the results show that our algorithm can effectively improve campaign performance and revenue of the platform.
Important Attribute Identification in Knowledge Graph
Oct 12, 2018
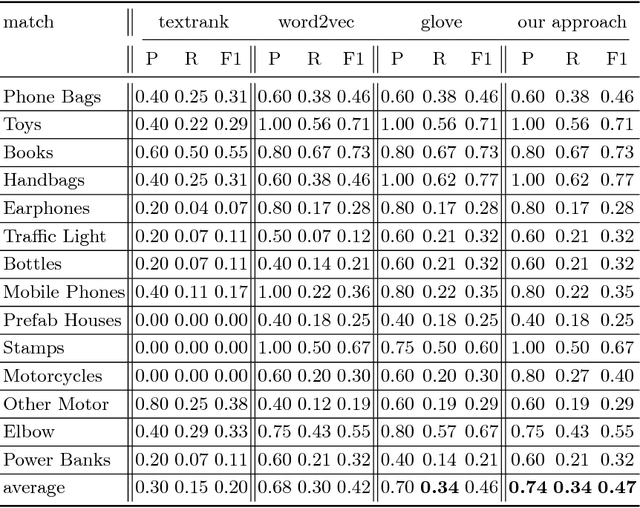
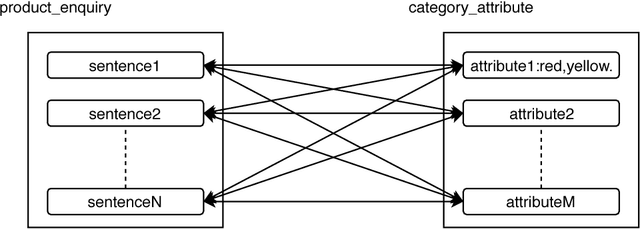
The knowledge graph(KG) composed of entities with their descriptions and attributes, and relationship between entities, is finding more and more application scenarios in various natural language processing tasks. In a typical knowledge graph like Wikidata, entities usually have a large number of attributes, but it is difficult to know which ones are important. The importance of attributes can be a valuable piece of information in various applications spanning from information retrieval to natural language generation. In this paper, we propose a general method of using external user generated text data to evaluate the relative importance of an entity's attributes. To be more specific, we use the word/sub-word embedding techniques to match the external textual data back to entities' attribute name and values and rank the attributes by their matching cohesiveness. To our best knowledge, this is the first work of applying vector based semantic matching to important attribute identification, and our method outperforms the previous traditional methods. We also apply the outcome of the detected important attributes to a language generation task; compared with previous generated text, the new method generates much more customized and informative messages.
Learning Theory and Algorithms for Revenue Management in Sponsored Search
Jul 05, 2018
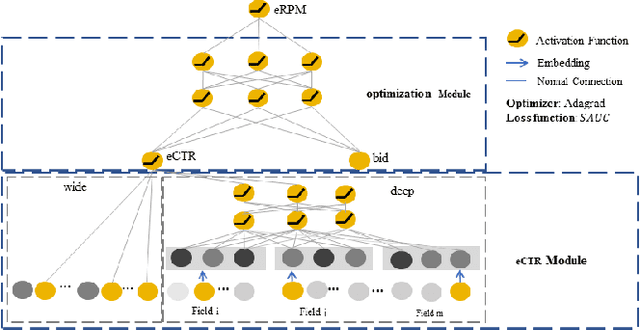
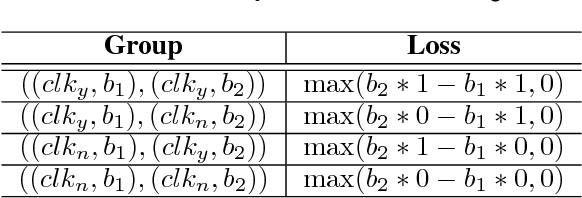

Online advertisement is the main source of revenue for Internet business. Advertisers are typically ranked according to a score that takes into account their bids and potential click-through rates(eCTR). Generally, the likelihood that a user clicks on an ad is often modeled by optimizing for the click through rates rather than the performance of the auction in which the click through rates will be used. This paper attempts to eliminate this dis-connection by proposing loss functions for click modeling that are based on final auction performance.In this paper, we address two feasible metrics (AUC^R and SAUC) to evaluate the on-line RPM (revenue per mille) directly rather than the CTR. And then, we design an explicit ranking function by incorporating the calibration fac-tor and price-squashed factor to maximize the revenue. Given the power of deep networks, we also explore an implicit optimal ranking function with deep model. Lastly, various experiments with two real world datasets are presented. In particular, our proposed methods perform better than the state-of-the-art methods with regard to the revenue of the platform.
Dual Based DSP Bidding Strategy and its Application
Dec 27, 2017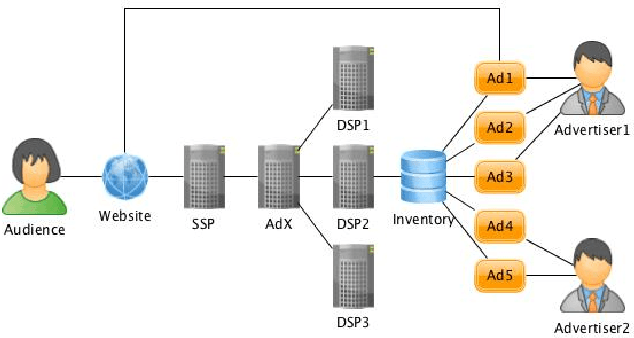


In recent years, RTB(Real Time Bidding) becomes a popular online advertisement trading method. During the auction, each DSP(Demand Side Platform) is supposed to evaluate current opportunity and respond with an ad and corresponding bid price. It's essential for DSP to find an optimal ad selection and bid price determination strategy which maximizes revenue or performance under budget and ROI(Return On Investment) constraints in P4P(Pay For Performance) or P4U(Pay For Usage) mode. We solve this problem by 1) formalizing the DSP problem as a constrained optimization problem, 2) proposing the augmented MMKP(Multi-choice Multi-dimensional Knapsack Problem) with general solution, 3) and demonstrating the DSP problem is a special case of the augmented MMKP and deriving specialized strategy. Our strategy is verified through simulation and outperforms state-of-the-art strategies in real application. To the best of our knowledge, our solution is the first dual based DSP bidding framework that is derived from strict second price auction assumption and generally applicable to the multiple ads scenario with various objectives and constraints.