 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLive or Lie: Action-Aware Capsule Multiple Instance Learning for Risk Assessment in Live Streaming Platforms
Feb 03, 2026Live streaming has become a cornerstone of today's internet, enabling massive real-time social interactions. However, it faces severe risks arising from sparse, coordinated malicious behaviors among multiple participants, which are often concealed within normal activities and challenging to detect timely and accurately. In this work, we provide a pioneering study on risk assessment in live streaming rooms, characterized by weak supervision where only room-level labels are available. We formulate the task as a Multiple Instance Learning (MIL) problem, treating each room as a bag and defining structured user-timeslot capsules as instances. These capsules represent subsequences of user actions within specific time windows, encapsulating localized behavioral patterns. Based on this formulation, we propose AC-MIL, an Action-aware Capsule MIL framework that models both individual behaviors and group-level coordination patterns. AC-MIL captures multi-granular semantics and behavioral cues through a serial and parallel architecture that jointly encodes temporal dynamics and cross-user dependencies. These signals are integrated for robust room-level risk prediction, while also offering interpretable evidence at the behavior segment level. Extensive experiments on large-scale industrial datasets from Douyin demonstrate that AC-MIL significantly outperforms MIL and sequential baselines, establishing new state-of-the-art performance in room-level risk assessment for live streaming. Moreover, AC-MIL provides capsule-level interpretability, enabling identification of risky behavior segments as actionable evidence for intervention. The project page is available at: https://qiaoyran.github.io/AC-MIL/.
Deja Vu in Plots: Leveraging Cross-Session Evidence with Retrieval-Augmented LLMs for Live Streaming Risk Assessment
Jan 22, 2026The rise of live streaming has transformed online interaction, enabling massive real-time engagement but also exposing platforms to complex risks such as scams and coordinated malicious behaviors. Detecting these risks is challenging because harmful actions often accumulate gradually and recur across seemingly unrelated streams. To address this, we propose CS-VAR (Cross-Session Evidence-Aware Retrieval-Augmented Detector) for live streaming risk assessment. In CS-VAR, a lightweight, domain-specific model performs fast session-level risk inference, guided during training by a Large Language Model (LLM) that reasons over retrieved cross-session behavioral evidence and transfers its local-to-global insights to the small model. This design enables the small model to recognize recurring patterns across streams, perform structured risk assessment, and maintain efficiency for real-time deployment. Extensive offline experiments on large-scale industrial datasets, combined with online validation, demonstrate the state-of-the-art performance of CS-VAR. Furthermore, CS-VAR provides interpretable, localized signals that effectively empower real-world moderation for live streaming.
Leveraging Domain Agnostic and Specific Knowledge for Acronym Disambiguation
Jul 01, 2021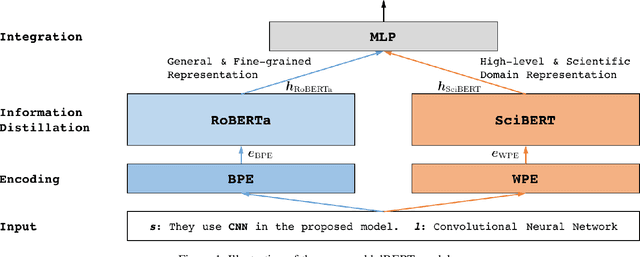

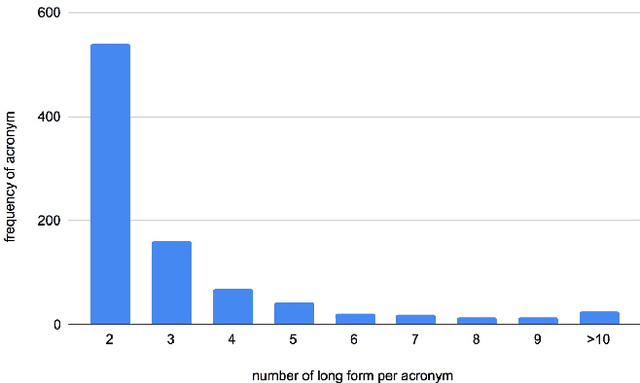
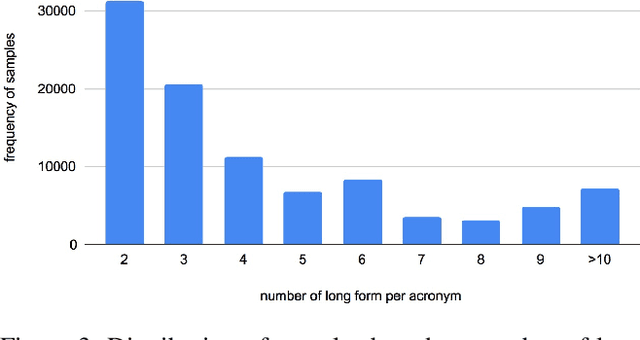
An obstacle to scientific document understanding is the extensive use of acronyms which are shortened forms of long technical phrases. Acronym disambiguation aims to find the correct meaning of an ambiguous acronym in a given text. Recent efforts attempted to incorporate word embeddings and deep learning architectures, and achieved significant effects in this task. In general domains, kinds of fine-grained pretrained language models have sprung up, thanks to the largescale corpora which can usually be obtained through crowdsourcing. However, these models based on domain agnostic knowledge might achieve insufficient performance when directly applied to the scientific domain. Moreover, obtaining large-scale high-quality annotated data and representing high-level semantics in the scientific domain is challenging and expensive. In this paper, we consider both the domain agnostic and specific knowledge, and propose a Hierarchical Dual-path BERT method coined hdBERT to capture the general fine-grained and high-level specific representations for acronym disambiguation. First, the context-based pretrained models, RoBERTa and SciBERT, are elaborately involved in encoding these two kinds of knowledge respectively. Second, multiple layer perceptron is devised to integrate the dualpath representations simultaneously and outputs the prediction. With a widely adopted SciAD dataset contained 62,441 sentences, we investigate the effectiveness of hdBERT. The experimental results exhibit that the proposed approach outperforms state-of-the-art methods among various evaluation metrics. Specifically, its macro F1 achieves 93.73%.
Multimodal and Contrastive Learning for Click Fraud Detection
May 08, 2021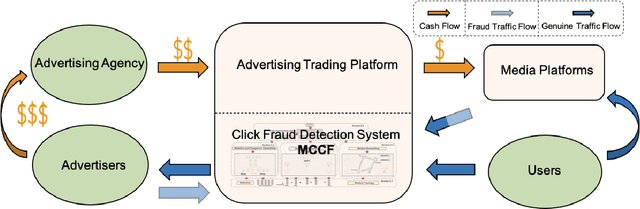
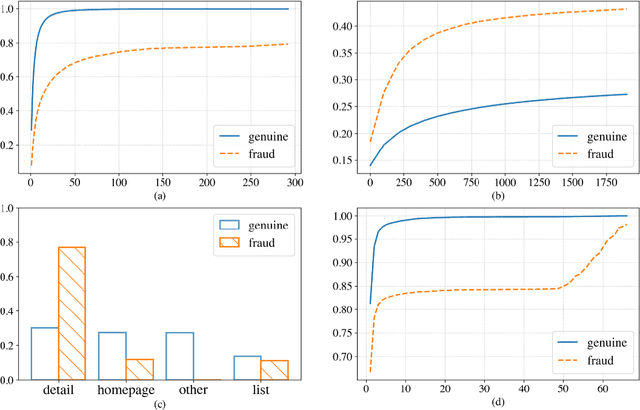

Advertising click fraud detection plays one of the vital roles in current E-commerce websites as advertising is an essential component of its business model. It aims at, given a set of corresponding features, e.g., demographic information of users and statistical features of clicks, predicting whether a click is fraudulent or not in the community. Recent efforts attempted to incorporate attributed behavior sequence and heterogeneous network for extracting complex features of users and achieved significant effects on click fraud detection. In this paper, we propose a Multimodal and Contrastive learning network for Click Fraud detection (MCCF). Specifically, motivated by the observations on differences of demographic information, behavior sequences and media relationship between fraudsters and genuine users on E-commerce platform, MCCF jointly utilizes wide and deep features, behavior sequence and heterogeneous network to distill click representations. Moreover, these three modules are integrated by contrastive learning and collaboratively contribute to the final predictions. With the real-world datasets containing 2.54 million clicks on Alibaba platform, we investigate the effectiveness of MCCF. The experimental results show that the proposed approach is able to improve AUC by 7.2% and F1-score by 15.6%, compared with the state-of-the-art methods.
AT-BERT: Adversarial Training BERT for Acronym Identification Winning Solution for SDU@AAAI-21
Jan 12, 2021
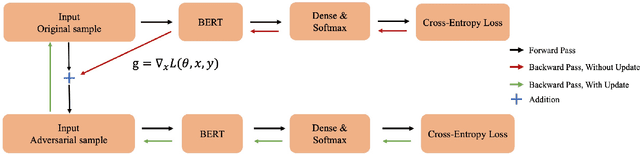

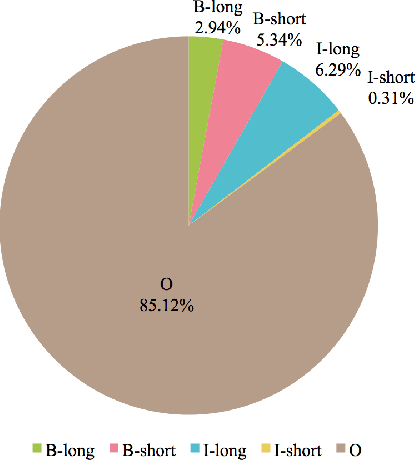
Acronym identification focuses on finding the acronyms and the phrases that have been abbreviated, which is crucial for scientific document understanding tasks. However, the limited size of manually annotated datasets hinders further improvement for the problem. Recent breakthroughs of language models pre-trained on large corpora clearly show that unsupervised pre-training can vastly improve the performance of downstream tasks. In this paper, we present an Adversarial Training BERT method named AT-BERT, our winning solution to acronym identification task for Scientific Document Understanding (SDU) Challenge of AAAI 2021. Specifically, the pre-trained BERT is adopted to capture better semantic representation. Then we incorporate the FGM adversarial training strategy into the fine-tuning of BERT, which makes the model more robust and generalized. Furthermore, an ensemble mechanism is devised to involve the representations learned from multiple BERT variants. Assembling all these components together, the experimental results on the SciAI dataset show that our proposed approach outperforms all other competitive state-of-the-art methods.