 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoK: Comparing Different Membership Inference Attacks with a Comprehensive Benchmark
Jul 12, 2023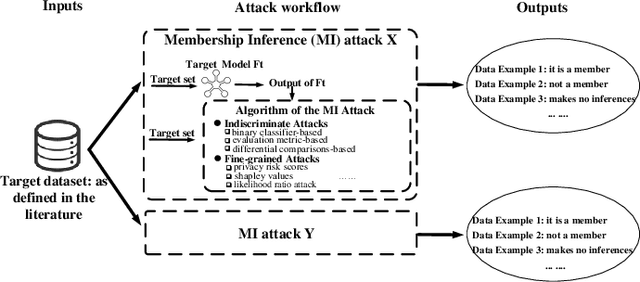
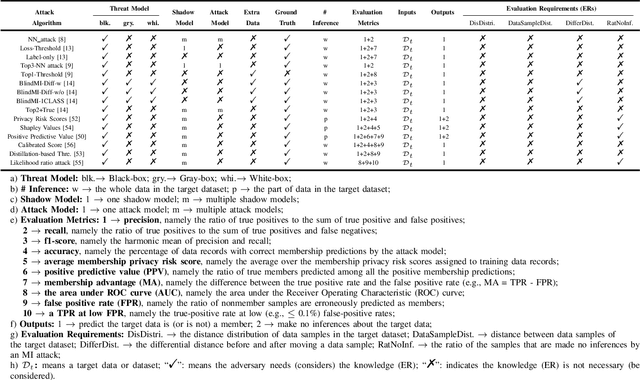

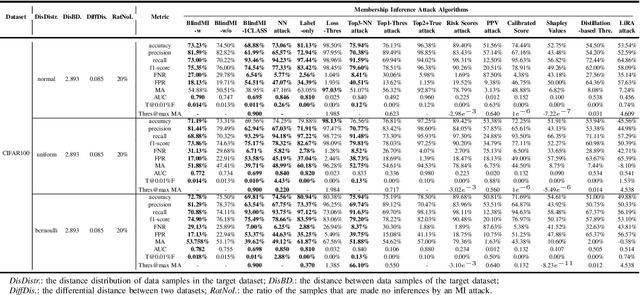
Membership inference (MI) attacks threaten user privacy through determining if a given data example has been used to train a target model. However, it has been increasingly recognized that the "comparing different MI attacks" methodology used in the existing works has serious limitations. Due to these limitations, we found (through the experiments in this work) that some comparison results reported in the literature are quite misleading. In this paper, we seek to develop a comprehensive benchmark for comparing different MI attacks, called MIBench, which consists not only the evaluation metrics, but also the evaluation scenarios. And we design the evaluation scenarios from four perspectives: the distance distribution of data samples in the target dataset, the distance between data samples of the target dataset, the differential distance between two datasets (i.e., the target dataset and a generated dataset with only nonmembers), and the ratio of the samples that are made no inferences by an MI attack. The evaluation metrics consist of ten typical evaluation metrics. We have identified three principles for the proposed "comparing different MI attacks" methodology, and we have designed and implemented the MIBench benchmark with 84 evaluation scenarios for each dataset. In total, we have used our benchmark to fairly and systematically compare 15 state-of-the-art MI attack algorithms across 588 evaluation scenarios, and these evaluation scenarios cover 7 widely used datasets and 7 representative types of models. All codes and evaluations of MIBench are publicly available at https://github.com/MIBench/MIBench.github.io/blob/main/README.md.
BeamAttack: Generating High-quality Textual Adversarial Examples through Beam Search and Mixed Semantic Spaces
Mar 09, 2023



Natural language processing models based on neural networks are vulnerable to adversarial examples. These adversarial examples are imperceptible to human readers but can mislead models to make the wrong predictions. In a black-box setting, attacker can fool the model without knowing model's parameters and architecture. Previous works on word-level attacks widely use single semantic space and greedy search as a search strategy. However, these methods fail to balance the attack success rate, quality of adversarial examples and time consumption. In this paper, we propose BeamAttack, a textual attack algorithm that makes use of mixed semantic spaces and improved beam search to craft high-quality adversarial examples. Extensive experiments demonstrate that BeamAttack can improve attack success rate while saving numerous queries and time, e.g., improving at most 7\% attack success rate than greedy search when attacking the examples from MR dataset. Compared with heuristic search, BeamAttack can save at most 85\% model queries and achieve a competitive attack success rate. The adversarial examples crafted by BeamAttack are highly transferable and can effectively improve model's robustness during adversarial training. Code is available at https://github.com/zhuhai-ustc/beamattack/tree/master
Multimodal and Contrastive Learning for Click Fraud Detection
May 08, 2021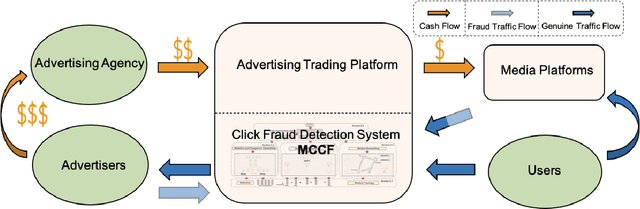
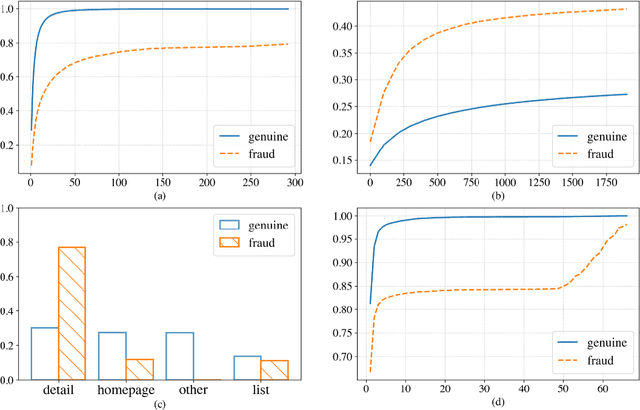

Advertising click fraud detection plays one of the vital roles in current E-commerce websites as advertising is an essential component of its business model. It aims at, given a set of corresponding features, e.g., demographic information of users and statistical features of clicks, predicting whether a click is fraudulent or not in the community. Recent efforts attempted to incorporate attributed behavior sequence and heterogeneous network for extracting complex features of users and achieved significant effects on click fraud detection. In this paper, we propose a Multimodal and Contrastive learning network for Click Fraud detection (MCCF). Specifically, motivated by the observations on differences of demographic information, behavior sequences and media relationship between fraudsters and genuine users on E-commerce platform, MCCF jointly utilizes wide and deep features, behavior sequence and heterogeneous network to distill click representations. Moreover, these three modules are integrated by contrastive learning and collaboratively contribute to the final predictions. With the real-world datasets containing 2.54 million clicks on Alibaba platform, we investigate the effectiveness of MCCF. The experimental results show that the proposed approach is able to improve AUC by 7.2% and F1-score by 15.6%, compared with the state-of-the-art methods.