 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoK: Comparing Different Membership Inference Attacks with a Comprehensive Benchmark
Jul 12, 2023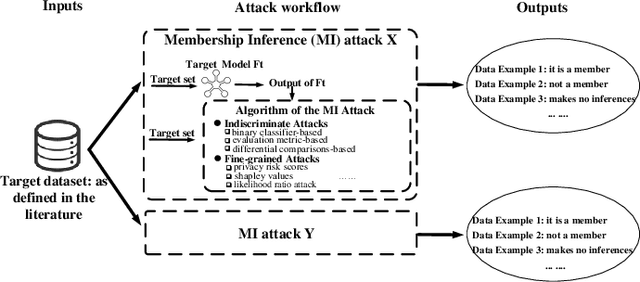
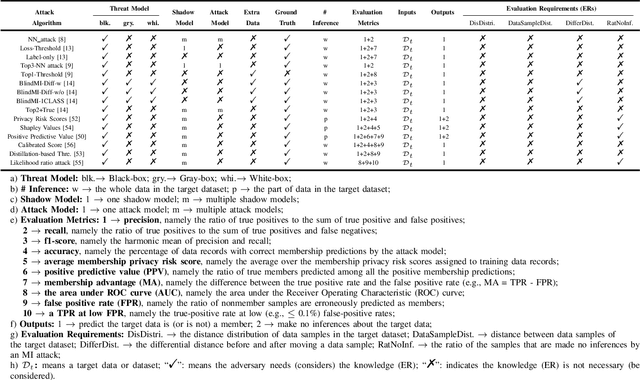

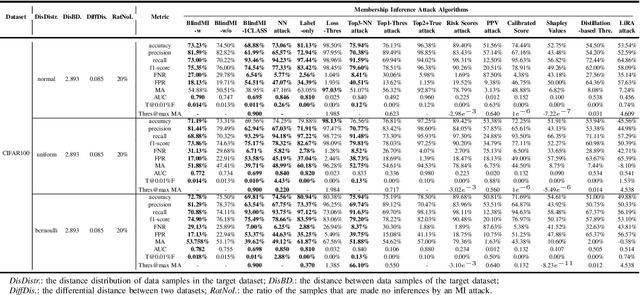
Membership inference (MI) attacks threaten user privacy through determining if a given data example has been used to train a target model. However, it has been increasingly recognized that the "comparing different MI attacks" methodology used in the existing works has serious limitations. Due to these limitations, we found (through the experiments in this work) that some comparison results reported in the literature are quite misleading. In this paper, we seek to develop a comprehensive benchmark for comparing different MI attacks, called MIBench, which consists not only the evaluation metrics, but also the evaluation scenarios. And we design the evaluation scenarios from four perspectives: the distance distribution of data samples in the target dataset, the distance between data samples of the target dataset, the differential distance between two datasets (i.e., the target dataset and a generated dataset with only nonmembers), and the ratio of the samples that are made no inferences by an MI attack. The evaluation metrics consist of ten typical evaluation metrics. We have identified three principles for the proposed "comparing different MI attacks" methodology, and we have designed and implemented the MIBench benchmark with 84 evaluation scenarios for each dataset. In total, we have used our benchmark to fairly and systematically compare 15 state-of-the-art MI attack algorithms across 588 evaluation scenarios, and these evaluation scenarios cover 7 widely used datasets and 7 representative types of models. All codes and evaluations of MIBench are publicly available at https://github.com/MIBench/MIBench.github.io/blob/main/README.md.