 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Domain Agnostic and Specific Knowledge for Acronym Disambiguation
Jul 01, 2021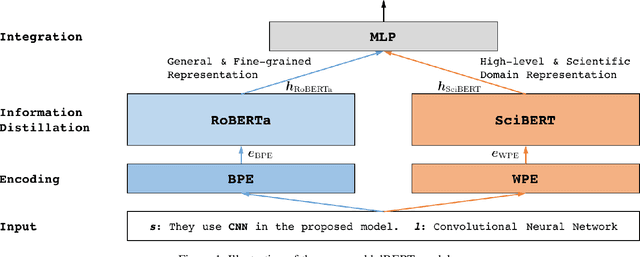

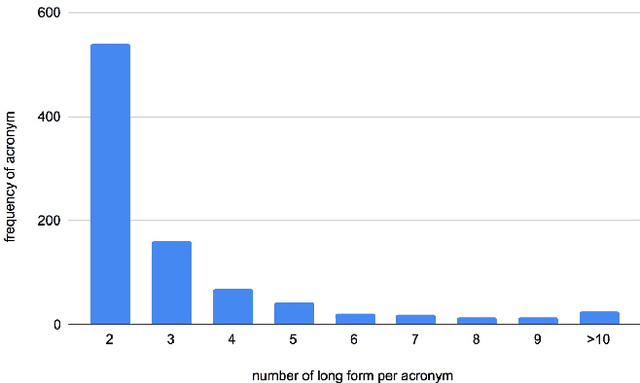
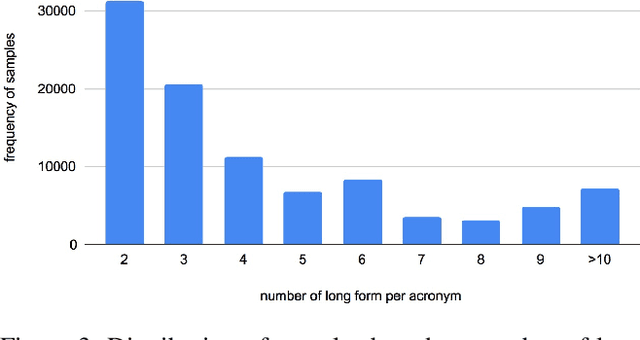
An obstacle to scientific document understanding is the extensive use of acronyms which are shortened forms of long technical phrases. Acronym disambiguation aims to find the correct meaning of an ambiguous acronym in a given text. Recent efforts attempted to incorporate word embeddings and deep learning architectures, and achieved significant effects in this task. In general domains, kinds of fine-grained pretrained language models have sprung up, thanks to the largescale corpora which can usually be obtained through crowdsourcing. However, these models based on domain agnostic knowledge might achieve insufficient performance when directly applied to the scientific domain. Moreover, obtaining large-scale high-quality annotated data and representing high-level semantics in the scientific domain is challenging and expensive. In this paper, we consider both the domain agnostic and specific knowledge, and propose a Hierarchical Dual-path BERT method coined hdBERT to capture the general fine-grained and high-level specific representations for acronym disambiguation. First, the context-based pretrained models, RoBERTa and SciBERT, are elaborately involved in encoding these two kinds of knowledge respectively. Second, multiple layer perceptron is devised to integrate the dualpath representations simultaneously and outputs the prediction. With a widely adopted SciAD dataset contained 62,441 sentences, we investigate the effectiveness of hdBERT. The experimental results exhibit that the proposed approach outperforms state-of-the-art methods among various evaluation metrics. Specifically, its macro F1 achieves 93.73%.
AT-BERT: Adversarial Training BERT for Acronym Identification Winning Solution for SDU@AAAI-21
Jan 12, 2021
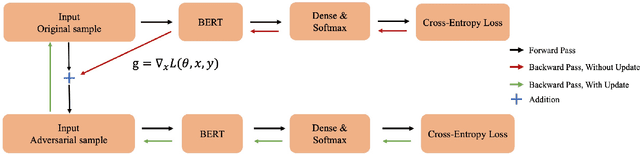

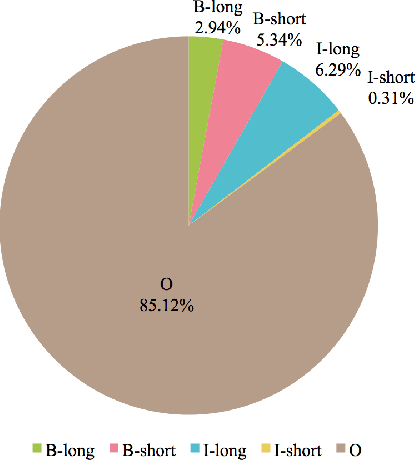
Acronym identification focuses on finding the acronyms and the phrases that have been abbreviated, which is crucial for scientific document understanding tasks. However, the limited size of manually annotated datasets hinders further improvement for the problem. Recent breakthroughs of language models pre-trained on large corpora clearly show that unsupervised pre-training can vastly improve the performance of downstream tasks. In this paper, we present an Adversarial Training BERT method named AT-BERT, our winning solution to acronym identification task for Scientific Document Understanding (SDU) Challenge of AAAI 2021. Specifically, the pre-trained BERT is adopted to capture better semantic representation. Then we incorporate the FGM adversarial training strategy into the fine-tuning of BERT, which makes the model more robust and generalized. Furthermore, an ensemble mechanism is devised to involve the representations learned from multiple BERT variants. Assembling all these components together, the experimental results on the SciAI dataset show that our proposed approach outperforms all other competitive state-of-the-art methods.
Continuous Learning of Context-dependent Processing in Neural Networks
Oct 05, 2018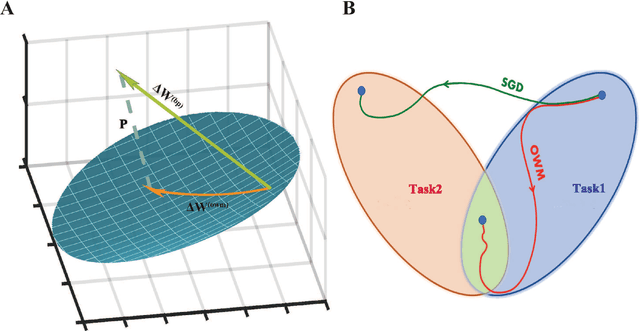

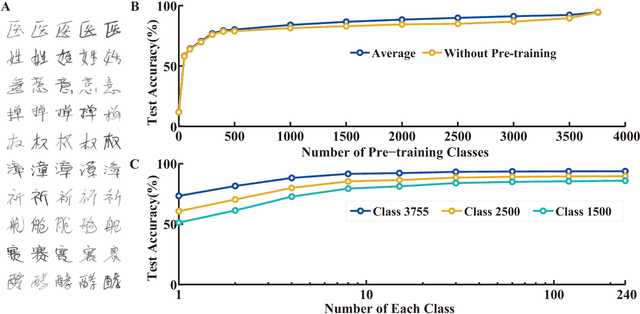
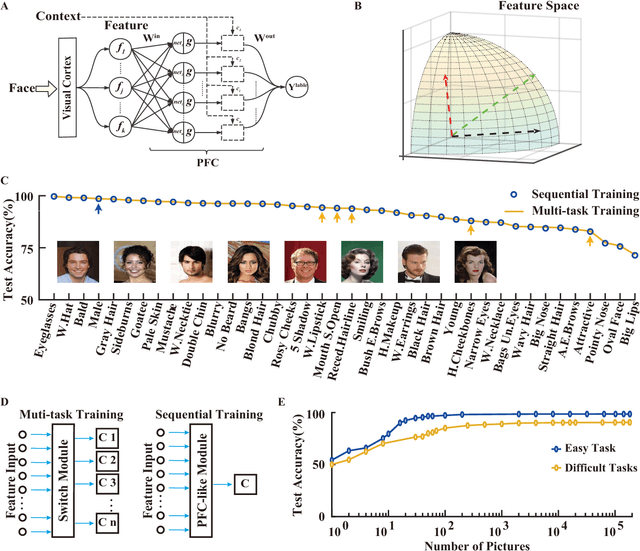
Deep artificial neural networks (DNNs) are powerful tools for recognition and classification as they learn sophisticated mapping rules between the inputs and the outputs. However, the rules that learned by the majority of current DNNs used for pattern recognition are largely fixed and do not vary with different conditions. This limits the network's ability to work in more complex and dynamical situations in which the mapping rules themselves are not fixed but constantly change according to contexts, such as different environments and goals. Inspired by the role of the prefrontal cortex (PFC) in mediating context-dependent processing in the primate brain, here we propose a novel approach, involving a learning algorithm named orthogonal weights modification (OWM) with the addition of a PFC-like module, that enables networks to continually learn different mapping rules in a context-dependent way. We demonstrate that with OWM to protect previously acquired knowledge, the networks could sequentially learn up to thousands of different mapping rules without interference, and needing as few as $\sim$10 samples to learn each, reaching a human level ability in online, continual learning. In addition, by using a PFC-like module to enable contextual information to modulate the representation of sensory features, a network could sequentially learn different, context-specific mappings for identical stimuli. Taken together, these approaches allow us to teach a single network numerous context-dependent mapping rules in an online, continual manner. This would enable highly compact systems to gradually learn myriad of regularities of the real world and eventually behave appropriately within it.