 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussian Graph with Prototypical Contrastive Learning in E-Commerce Bundle Recommendation
Jul 25, 2023Bundle recommendation aims to provide a bundle of items to satisfy the user preference on e-commerce platform. Existing successful solutions are based on the contrastive graph learning paradigm where graph neural networks (GNNs) are employed to learn representations from user-level and bundle-level graph views with a contrastive learning module to enhance the cooperative association between different views. Nevertheless, they ignore the uncertainty issue which has a significant impact in real bundle recommendation scenarios due to the lack of discriminative information caused by highly sparsity or diversity. We further suggest that their instancewise contrastive learning fails to distinguish the semantically similar negatives (i.e., sampling bias issue), resulting in performance degradation. In this paper, we propose a novel Gaussian Graph with Prototypical Contrastive Learning (GPCL) framework to overcome these challenges. In particular, GPCL embeds each user/bundle/item as a Gaussian distribution rather than a fixed vector. We further design a prototypical contrastive learning module to capture the contextual information and mitigate the sampling bias issue. Extensive experiments demonstrate that benefiting from the proposed components, we achieve new state-of-the-art performance compared to previous methods on several public datasets. Moreover, GPCL has been deployed on real-world e-commerce platform and achieved substantial improvements.
What Makes Entities Similar? A Similarity Flooding Perspective for Multi-sourced Knowledge Graph Embeddings
Jun 05, 2023Joint representation learning over multi-sourced knowledge graphs (KGs) yields transferable and expressive embeddings that improve downstream tasks. Entity alignment (EA) is a critical step in this process. Despite recent considerable research progress in embedding-based EA, how it works remains to be explored. In this paper, we provide a similarity flooding perspective to explain existing translation-based and aggregation-based EA models. We prove that the embedding learning process of these models actually seeks a fixpoint of pairwise similarities between entities. We also provide experimental evidence to support our theoretical analysis. We propose two simple but effective methods inspired by the fixpoint computation in similarity flooding, and demonstrate their effectiveness on benchmark datasets. Our work bridges the gap between recent embedding-based models and the conventional similarity flooding algorithm. It would improve our understanding of and increase our faith in embedding-based EA.
Joint Pre-training and Local Re-training: Transferable Representation Learning on Multi-source Knowledge Graphs
Jun 05, 2023



In this paper, we present the ``joint pre-training and local re-training'' framework for learning and applying multi-source knowledge graph (KG) embeddings. We are motivated by the fact that different KGs contain complementary information to improve KG embeddings and downstream tasks. We pre-train a large teacher KG embedding model over linked multi-source KGs and distill knowledge to train a student model for a task-specific KG. To enable knowledge transfer across different KGs, we use entity alignment to build a linked subgraph for connecting the pre-trained KGs and the target KG. The linked subgraph is re-trained for three-level knowledge distillation from the teacher to the student, i.e., feature knowledge distillation, network knowledge distillation, and prediction knowledge distillation, to generate more expressive embeddings. The teacher model can be reused for different target KGs and tasks without having to train from scratch. We conduct extensive experiments to demonstrate the effectiveness and efficiency of our framework.
Deep Active Alignment of Knowledge Graph Entities and Schemata
Apr 19, 2023



Knowledge graphs (KGs) store rich facts about the real world. In this paper, we study KG alignment, which aims to find alignment between not only entities but also relations and classes in different KGs. Alignment at the entity level can cross-fertilize alignment at the schema level. We propose a new KG alignment approach, called DAAKG, based on deep learning and active learning. With deep learning, it learns the embeddings of entities, relations and classes, and jointly aligns them in a semi-supervised manner. With active learning, it estimates how likely an entity, relation or class pair can be inferred, and selects the best batch for human labeling. We design two approximation algorithms for efficient solution to batch selection. Our experiments on benchmark datasets show the superior accuracy and generalization of DAAKG and validate the effectiveness of all its modules.
Trustworthy Knowledge Graph Completion Based on Multi-sourced Noisy Data
Jan 21, 2022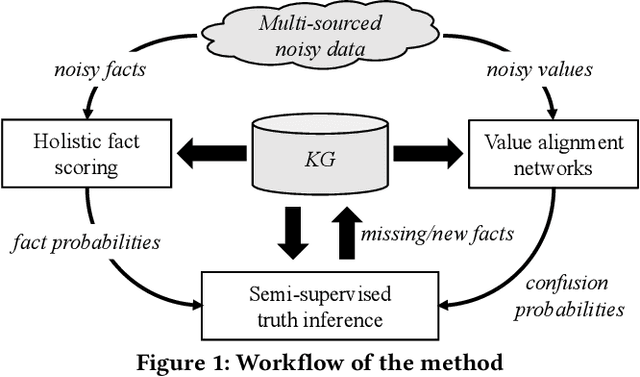
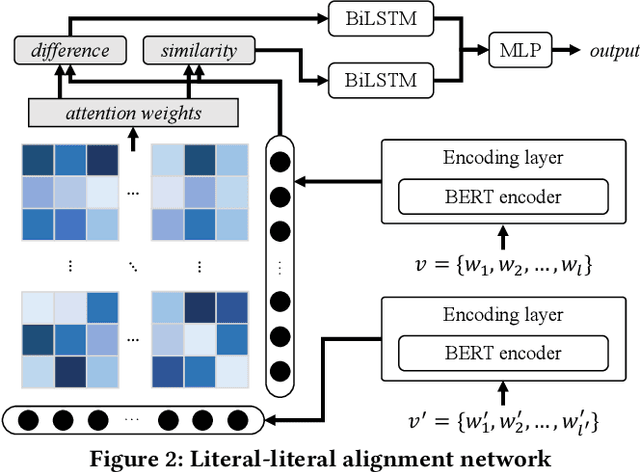
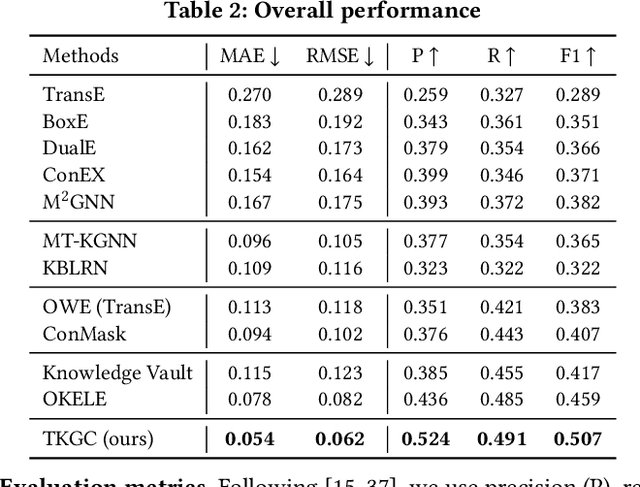
Knowledge graphs (KGs) have become a valuable asset for many AI applications. Although some KGs contain plenty of facts, they are widely acknowledged as incomplete. To address this issue, many KG completion methods are proposed. Among them, open KG completion methods leverage the Web to find missing facts. However, noisy data collected from diverse sources may damage the completion accuracy. In this paper, we propose a new trustworthy method that exploits facts for a KG based on multi-sourced noisy data and existing facts in the KG. Specifically, we introduce a graph neural network with a holistic scoring function to judge the plausibility of facts with various value types. We design value alignment networks to resolve the heterogeneity between values and map them to entities even outside the KG. Furthermore, we present a truth inference model that incorporates data source qualities into the fact scoring function, and design a semi-supervised learning way to infer the truths from heterogeneous values. We conduct extensive experiments to compare our method with the state-of-the-arts. The results show that our method achieves superior accuracy not only in completing missing facts but also in discovering new facts.
Transformer-based Language Model Fine-tuning Methods for COVID-19 Fake News Detection
Jan 18, 2021
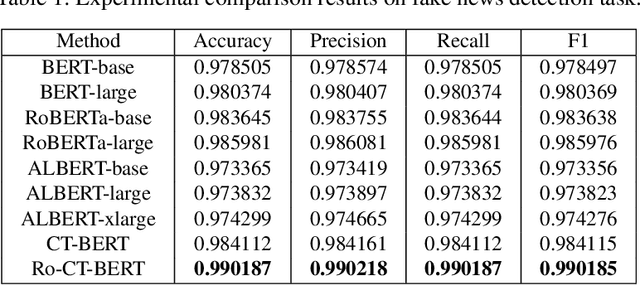
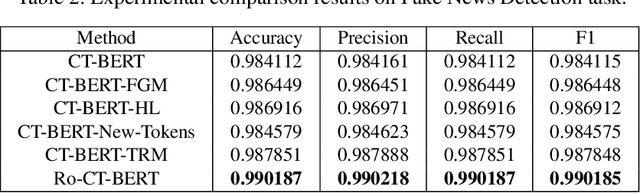
With the pandemic of COVID-19, relevant fake news is spreading all over the sky throughout the social media. Believing in them without discrimination can cause great trouble to people's life. However, universal language models may perform weakly in these fake news detection for lack of large-scale annotated data and sufficient semantic understanding of domain-specific knowledge. While the model trained on corresponding corpora is also mediocre for insufficient learning. In this paper, we propose a novel transformer-based language model fine-tuning approach for these fake news detection. First, the token vocabulary of individual model is expanded for the actual semantics of professional phrases. Second, we adapt the heated-up softmax loss to distinguish the hard-mining samples, which are common for fake news because of the disambiguation of short text. Then, we involve adversarial training to improve the model's robustness. Last, the predicted features extracted by universal language model RoBERTa and domain-specific model CT-BERT are fused by one multiple layer perception to integrate fine-grained and high-level specific representations. Quantitative experimental results evaluated on existing COVID-19 fake news dataset show its superior performances compared to the state-of-the-art methods among various evaluation metrics. Furthermore, the best weighted average F1 score achieves 99.02%.