 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing Structural Context for Entity Alignment Foundation Models
Jun 04, 2026Entity alignment (EA) aims to identify equivalent entities across heterogeneous knowledge graphs (KGs) and is a key component of knowledge fusion and cross-KG reasoning. The recent EA foundation model demonstrates that alignment knowledge, once pretrained, can be directly applied to diverse previously unseen KG pairs. However, it still underuses structural context in two places: cross-KG interaction is weak during encoding, and final candidate ranking still relies too heavily on coarse similarity. We address these limitations with ContextEA, an enhanced encoder-decoder framework for transferable EA. On the encoder side, we introduce a cross-KG interaction encoder that unifies the two KGs with anchor bridges and performs earlier relation-aware cross-graph propagation. On the decoder side, we introduce a structural calibration decoder that calibrates alignment scores with entity-level, neighborhood-level, relation-level, and anchor-aware structural evidence. This design strengthens both structural context construction and structural context exploitation while remaining lightweight. Experiments on 29 EA datasets in OpenEA, SRPRS, and DBP show consistent gains over strong transferable baselines. Notably, the pretrained ContextEA already surpasses the finetuned baselines on all three benchmark groups, demonstrating substantially stronger transfer to unseen KGs. These results suggest that explicitly harnessing structural context is an effective direction for improving EA foundation models.
From Agent Traces to Trust: Evidence Tracing and Execution Provenance in LLM Agents
Jun 03, 2026Large language model (LLM)-based agents increasingly solve complex tasks by interacting with external tools, retrieval systems, memory modules, environments, and other agents. These capabilities expand agent autonomy, but also make agent behavior harder to verify, debug, and audit. Final-answer accuracy alone cannot explain how an output was produced, which evidence supported each claim, whether tool calls were justified, how memory influenced later decisions, or where execution failures originated. Evidence tracing and execution provenance address this gap by modeling how retrieved evidence, tool outputs, memory items, environment observations, intermediate claims, actions, and final answers are connected throughout agent execution. This survey provides a systematic review and conceptual framework for evidence tracing and execution provenance in LLM agents. We organize related work around a unified provenance perspective that connects retrieval grounding, claim support, tool-use safety, memory lineage, observability, debugging, audit, and recovery. We introduce a taxonomy covering trace sources, evidence and execution units, provenance relations, tracing granularity and timing, representation forms, and trust functions. We review key methodological directions, including provenance representation, evidence attribution, tool-use provenance, runtime guardrails, provenance-bearing memory, trace-based observability, and failure diagnosis. We also map existing benchmarks, datasets, and evaluation metrics to provenance-related capabilities, and discuss how evaluation can move from final-answer correctness toward process-level accountability. Finally, we outline open challenges, including unified trace schemas, claim-level and semantic provenance, provenance-aware safety mechanisms, realistic execution-trace benchmarks, recovery-oriented evaluation, and privacy-aware audit infrastructure.
Asymmetric On-Policy Distillation: Bridging Exploitation and Imitation at the Token Level
May 07, 2026On-policy distillation (OPD) trains a student on its own trajectories with token-level teacher feedback and often outperforms off-policy distillation and standard reinforcement learning. However, we find that its standard advantage weighted policy gradient suffers from three structural weaknesses, including high variance updates, vanishing gradients in zero-advantage regions, and exploration bottlenecks when corrective signals are insufficient.We therefore propose Asymmetric On-Policy Distillation (AOPD), which replaces ineffective negative reinforcement with localized divergence minimization in non-positive advantage regions while preserving positive reinforcement learning. Experiments on mathematical reasoning benchmarks show that AOPD consistently outperforms standard OPD, with average gains of 4.09 / 8.34 under strong / weak initialization, respectively. AOPD also maintains higher policy entropy during training and better capability retention during sequential tool-use adaptation.
Breaking the Reasoning Horizon in Entity Alignment Foundation Models
Jan 29, 2026Entity alignment (EA) is critical for knowledge graph (KG) fusion. Existing EA models lack transferability and are incapable of aligning unseen KGs without retraining. While using graph foundation models (GFMs) offer a solution, we find that directly adapting GFMs to EA remains largely ineffective. This stems from a critical "reasoning horizon gap": unlike link prediction in GFMs, EA necessitates capturing long-range dependencies across sparse and heterogeneous KG structuresTo address this challenge, we propose a EA foundation model driven by a parallel encoding strategy. We utilize seed EA pairs as local anchors to guide the information flow, initializing and encoding two parallel streams simultaneously. This facilitates anchor-conditioned message passing and significantly shortens the inference trajectory by leveraging local structural proximity instead of global search. Additionally, we incorporate a merged relation graph to model global dependencies and a learnable interaction module for precise matching. Extensive experiments verify the effectiveness of our framework, highlighting its strong generalizability to unseen KGs.
SafeThinker: Reasoning about Risk to Deepen Safety Beyond Shallow Alignment
Jan 23, 2026Despite the intrinsic risk-awareness of Large Language Models (LLMs), current defenses often result in shallow safety alignment, rendering models vulnerable to disguised attacks (e.g., prefilling) while degrading utility. To bridge this gap, we propose SafeThinker, an adaptive framework that dynamically allocates defensive resources via a lightweight gateway classifier. Based on the gateway's risk assessment, inputs are routed through three distinct mechanisms: (i) a Standardized Refusal Mechanism for explicit threats to maximize efficiency; (ii) a Safety-Aware Twin Expert (SATE) module to intercept deceptive attacks masquerading as benign queries; and (iii) a Distribution-Guided Think (DDGT) component that adaptively intervenes during uncertain generation. Experiments show that SafeThinker significantly lowers attack success rates across diverse jailbreak strategies without compromising utility, demonstrating that coordinating intrinsic judgment throughout the generation process effectively balances robustness and practicality.
Beyond Static Summarization: Proactive Memory Extraction for LLM Agents
Jan 08, 2026Memory management is vital for LLM agents to handle long-term interaction and personalization. Most research focuses on how to organize and use memory summary, but often overlooks the initial memory extraction stage. In this paper, we argue that existing summary-based methods have two major limitations based on the recurrent processing theory. First, summarization is "ahead-of-time", acting as a blind "feed-forward" process that misses important details because it doesn't know future tasks. Second, extraction is usually "one-off", lacking a feedback loop to verify facts, which leads to the accumulation of information loss. To address these issues, we propose proactive memory extraction (namely ProMem). Unlike static summarization, ProMem treats extraction as an iterative cognitive process. We introduce a recurrent feedback loop where the agent uses self-questioning to actively probe the dialogue history. This mechanism allows the agent to recover missing information and correct errors. Our ProMem significantly improves the completeness of the extracted memory and QA accuracy. It also achieves a superior trade-off between extraction quality and token cost.
KGFR: A Foundation Retriever for Generalized Knowledge Graph Question Answering
Nov 06, 2025Large language models (LLMs) excel at reasoning but struggle with knowledge-intensive questions due to limited context and parametric knowledge. However, existing methods that rely on finetuned LLMs or GNN retrievers are limited by dataset-specific tuning and scalability on large or unseen graphs. We propose the LLM-KGFR collaborative framework, where an LLM works with a structured retriever, the Knowledge Graph Foundation Retriever (KGFR). KGFR encodes relations using LLM-generated descriptions and initializes entities based on their roles in the question, enabling zero-shot generalization to unseen KGs. To handle large graphs efficiently, it employs Asymmetric Progressive Propagation (APP)- a stepwise expansion that selectively limits high-degree nodes while retaining informative paths. Through node-, edge-, and path-level interfaces, the LLM iteratively requests candidate answers, supporting facts, and reasoning paths, forming a controllable reasoning loop. Experiments demonstrate that LLM-KGFR achieves strong performance while maintaining scalability and generalization, providing a practical solution for KG-augmented reasoning.
Answering the Unanswerable Is to Err Knowingly: Analyzing and Mitigating Abstention Failures in Large Reasoning Models
Aug 26, 2025
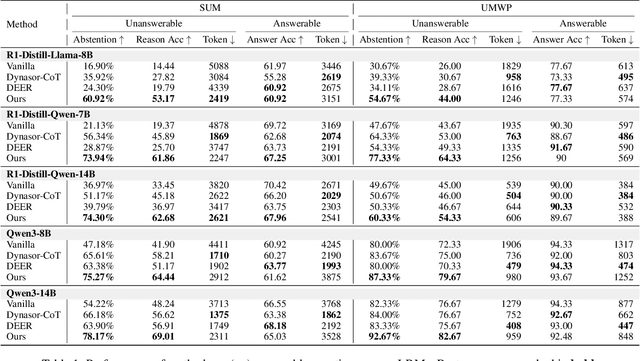
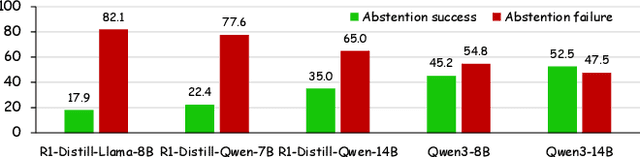
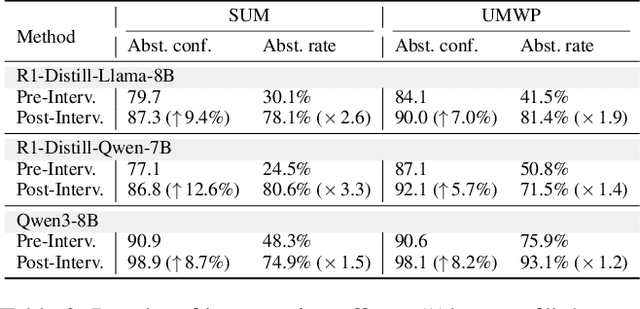
Large reasoning models (LRMs) have shown remarkable progress on complex reasoning tasks. However, some questions posed to LRMs are inherently unanswerable, such as math problems lacking sufficient conditions. We find that LRMs continually fail to provide appropriate abstentions when confronted with these unanswerable questions. In this paper, we systematically analyze, investigate, and resolve this issue for trustworthy AI. We first conduct a detailed analysis of the distinct response behaviors of LRMs when facing unanswerable questions. Then, we show that LRMs possess sufficient cognitive capabilities to recognize the flaws in these questions. However, they fail to exhibit appropriate abstention behavior, revealing a misalignment between their internal cognition and external response. Finally, to resolve this issue, we propose a lightweight, two-stage method that combines cognitive monitoring with inference-time intervention. Experimental results demonstrate that our method significantly improves the abstention rate while maintaining the overall reasoning performance.
When Can Large Reasoning Models Save Thinking? Mechanistic Analysis of Behavioral Divergence in Reasoning
May 21, 2025Large reasoning models (LRMs) have significantly advanced performance on complex tasks, yet their tendency to overthink introduces inefficiencies. This study investigates the internal mechanisms of reinforcement learning (RL)-trained LRMs when prompted to save thinking, revealing three distinct thinking modes: no thinking (NT), explicit thinking (ET), and implicit thinking (IT). Through comprehensive analysis of confidence in thinking termination, attention from thinking to generation, and attentional focus on input sections, we uncover key factors influencing the reasoning behaviors. We further find that NT reduces output length at the cost of accuracy, while ET and IT maintain accuracy with reduced response length. Our findings expose fundamental inconsistencies in RL-optimized LRMs, necessitating adaptive improvements for reliable efficiency.
Mitigating Lost-in-Retrieval Problems in Retrieval Augmented Multi-Hop Question Answering
Feb 20, 2025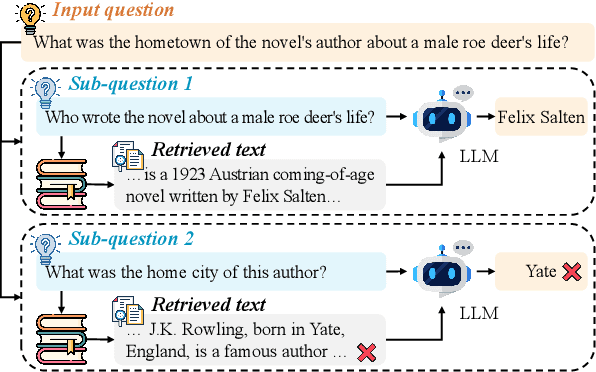



In this paper, we identify a critical problem, "lost-in-retrieval", in retrieval-augmented multi-hop question answering (QA): the key entities are missed in LLMs' sub-question decomposition. "Lost-in-retrieval" significantly degrades the retrieval performance, which disrupts the reasoning chain and leads to the incorrect answers. To resolve this problem, we propose a progressive retrieval and rewriting method, namely ChainRAG, which sequentially handles each sub-question by completing missing key entities and retrieving relevant sentences from a sentence graph for answer generation. Each step in our retrieval and rewriting process builds upon the previous one, creating a seamless chain that leads to accurate retrieval and answers. Finally, all retrieved sentences and sub-question answers are integrated to generate a comprehensive answer to the original question. We evaluate ChainRAG on three multi-hop QA datasets$\unicode{x2013}$MuSiQue, 2Wiki, and HotpotQA$\unicode{x2013}$using three large language models: GPT4o-mini, Qwen2.5-72B, and GLM-4-Plus. Empirical results demonstrate that ChainRAG consistently outperforms baselines in both effectiveness and efficiency.