 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinetuning Generative Large Language Models with Discrimination Instructions for Knowledge Graph Completion
Paper and Code
Jul 23, 2024

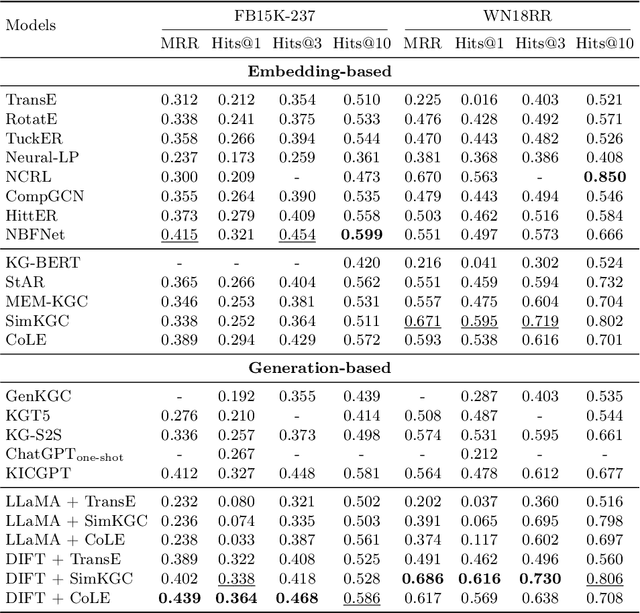

Traditional knowledge graph (KG) completion models learn embeddings to predict missing facts. Recent works attempt to complete KGs in a text-generation manner with large language models (LLMs). However, they need to ground the output of LLMs to KG entities, which inevitably brings errors. In this paper, we present a finetuning framework, DIFT, aiming to unleash the KG completion ability of LLMs and avoid grounding errors. Given an incomplete fact, DIFT employs a lightweight model to obtain candidate entities and finetunes an LLM with discrimination instructions to select the correct one from the given candidates. To improve performance while reducing instruction data, DIFT uses a truncated sampling method to select useful facts for finetuning and injects KG embeddings into the LLM. Extensive experiments on benchmark datasets demonstrate the effectiveness of our proposed framework.