 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinetuning Generative Large Language Models with Discrimination Instructions for Knowledge Graph Completion
Jul 23, 2024

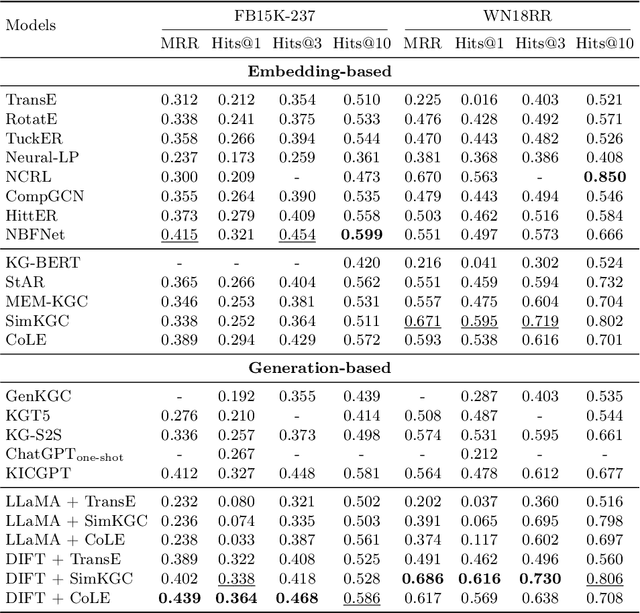

Traditional knowledge graph (KG) completion models learn embeddings to predict missing facts. Recent works attempt to complete KGs in a text-generation manner with large language models (LLMs). However, they need to ground the output of LLMs to KG entities, which inevitably brings errors. In this paper, we present a finetuning framework, DIFT, aiming to unleash the KG completion ability of LLMs and avoid grounding errors. Given an incomplete fact, DIFT employs a lightweight model to obtain candidate entities and finetunes an LLM with discrimination instructions to select the correct one from the given candidates. To improve performance while reducing instruction data, DIFT uses a truncated sampling method to select useful facts for finetuning and injects KG embeddings into the LLM. Extensive experiments on benchmark datasets demonstrate the effectiveness of our proposed framework.
Generating Explanations to Understand and Repair Embedding-based Entity Alignment
Dec 19, 2023



Entity alignment (EA) seeks identical entities in different knowledge graphs, which is a long-standing task in the database research. Recent work leverages deep learning to embed entities in vector space and align them via nearest neighbor search. Although embedding-based EA has gained marked success in recent years, it lacks explanations for alignment decisions. In this paper, we present the first framework that can generate explanations for understanding and repairing embedding-based EA results. Given an EA pair produced by an embedding model, we first compare its neighbor entities and relations to build a matching subgraph as a local explanation. We then construct an alignment dependency graph to understand the pair from an abstract perspective. Finally, we repair the pair by resolving three types of alignment conflicts based on dependency graphs. Experiments on a variety of EA datasets demonstrate the effectiveness, generalization, and robustness of our framework in explaining and repairing embedding-based EA results.
EventEA: Benchmarking Entity Alignment for Event-centric Knowledge Graphs
Nov 05, 2022



Entity alignment is to find identical entities in different knowledge graphs (KGs) that refer to the same real-world object. Embedding-based entity alignment techniques have been drawing a lot of attention recently because they can help solve the issue of symbolic heterogeneity in different KGs. However, in this paper, we show that the progress made in the past was due to biased and unchallenging evaluation. We highlight two major flaws in existing datasets that favor embedding-based entity alignment techniques, i.e., the isomorphic graph structures in relation triples and the weak heterogeneity in attribute triples. Towards a critical evaluation of embedding-based entity alignment methods, we construct a new dataset with heterogeneous relations and attributes based on event-centric KGs. We conduct extensive experiments to evaluate existing popular methods, and find that they fail to achieve promising performance. As a new approach to this difficult problem, we propose a time-aware literal encoder for entity alignment. The dataset and source code are publicly available to foster future research. Our work calls for more effective and practical embedding-based solutions to entity alignment.