 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeK-ON: Stacking Knowledge On the Head Layer of Large Language Model
Feb 10, 2025



Recent advancements in large language models (LLMs) have significantly improved various natural language processing (NLP) tasks. Typically, LLMs are trained to predict the next token, aligning well with many NLP tasks. However, in knowledge graph (KG) scenarios, entities are the fundamental units and identifying an entity requires at least several tokens. This leads to a granularity mismatch between KGs and natural languages. To address this issue, we propose K-ON, which integrates KG knowledge into the LLM by employing multiple head layers for next k-step prediction. K-ON can not only generate entity-level results in one step, but also enables contrastive loss against entities, which is the most powerful tool in KG representation learning. Experimental results show that K-ON outperforms state-of-the-art methods that incorporate text and even the other modalities.
Have We Designed Generalizable Structural Knowledge Promptings? Systematic Evaluation and Rethinking
Dec 31, 2024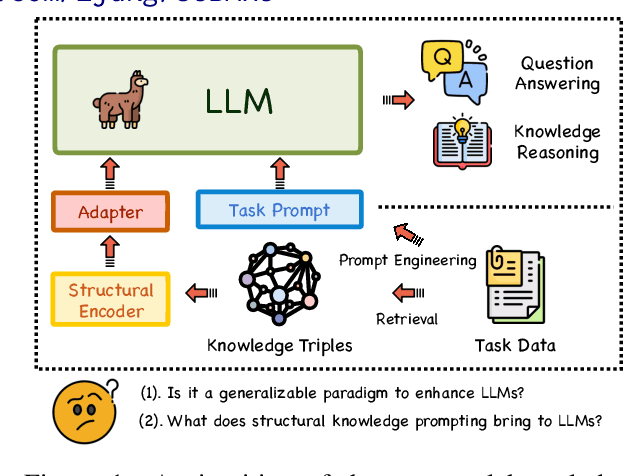
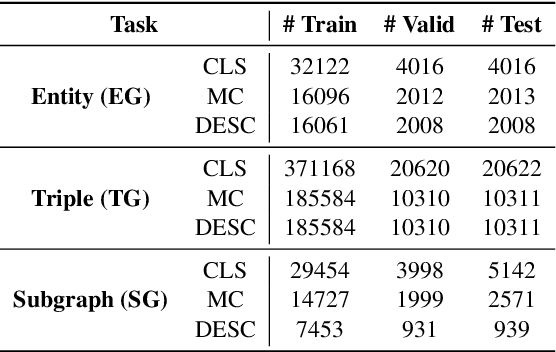
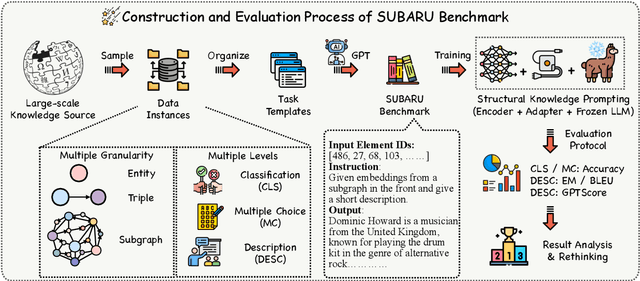
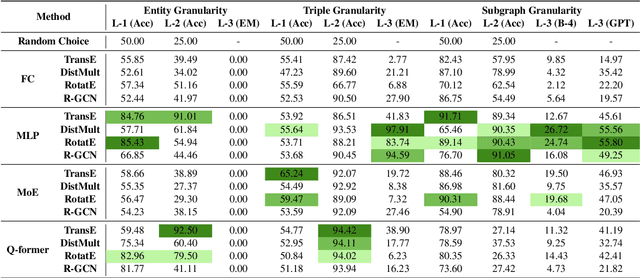
Large language models (LLMs) have demonstrated exceptional performance in text generation within current NLP research. However, the lack of factual accuracy is still a dark cloud hanging over the LLM skyscraper. Structural knowledge prompting (SKP) is a prominent paradigm to integrate external knowledge into LLMs by incorporating structural representations, achieving state-of-the-art results in many knowledge-intensive tasks. However, existing methods often focus on specific problems, lacking a comprehensive exploration of the generalization and capability boundaries of SKP. This paper aims to evaluate and rethink the generalization capability of the SKP paradigm from four perspectives including Granularity, Transferability, Scalability, and Universality. To provide a thorough evaluation, we introduce a novel multi-granular, multi-level benchmark called SUBARU, consisting of 9 different tasks with varying levels of granularity and difficulty.
MKGL: Mastery of a Three-Word Language
Oct 10, 2024



Large language models (LLMs) have significantly advanced performance across a spectrum of natural language processing (NLP) tasks. Yet, their application to knowledge graphs (KGs), which describe facts in the form of triplets and allow minimal hallucinations, remains an underexplored frontier. In this paper, we investigate the integration of LLMs with KGs by introducing a specialized KG Language (KGL), where a sentence precisely consists of an entity noun, a relation verb, and ends with another entity noun. Despite KGL's unfamiliar vocabulary to the LLM, we facilitate its learning through a tailored dictionary and illustrative sentences, and enhance context understanding via real-time KG context retrieval and KGL token embedding augmentation. Our results reveal that LLMs can achieve fluency in KGL, drastically reducing errors compared to conventional KG embedding methods on KG completion. Furthermore, our enhanced LLM shows exceptional competence in generating accurate three-word sentences from an initial entity and interpreting new unseen terms out of KGs.
Mixture of Modality Knowledge Experts for Robust Multi-modal Knowledge Graph Completion
May 27, 2024Multi-modal knowledge graph completion (MMKGC) aims to automatically discover new knowledge triples in the given multi-modal knowledge graphs (MMKGs), which is achieved by collaborative modeling the structural information concealed in massive triples and the multi-modal features of the entities. Existing methods tend to focus on crafting elegant entity-wise multi-modal fusion strategies, yet they overlook the utilization of multi-perspective features concealed within the modalities under diverse relational contexts. To address this issue, we introduce a novel MMKGC framework with Mixture of Modality Knowledge experts (MoMoK for short) to learn adaptive multi-modal embedding under intricate relational contexts. We design relation-guided modality knowledge experts to acquire relation-aware modality embeddings and integrate the predictions from multi-modalities to achieve comprehensive decisions. Additionally, we disentangle the experts by minimizing their mutual information. Experiments on four public MMKG benchmarks demonstrate the outstanding performance of MoMoK under complex scenarios.
Multi-domain Knowledge Graph Collaborative Pre-training and Prompt Tuning for Diverse Downstream Tasks
May 21, 2024


Knowledge graphs (KGs) provide reliable external knowledge for a wide variety of AI tasks in the form of structured triples. Knowledge graph pre-training (KGP) aims to pre-train neural networks on large-scale KGs and provide unified interfaces to enhance different downstream tasks, which is a key direction for KG management, maintenance, and applications. Existing works often focus on purely research questions in open domains, or they are not open source due to data security and privacy in real scenarios. Meanwhile, existing studies have not explored the training efficiency and transferability of KGP models in depth. To address these problems, We propose a framework MuDoK to achieve multi-domain collaborative pre-training and efficient prefix prompt tuning to serve diverse downstream tasks like recommendation and text understanding. Our design is a plug-and-play prompt learning approach that can be flexibly adapted to different downstream task backbones. In response to the lack of open-source benchmarks, we constructed a new multi-domain KGP benchmark called KPI with two large-scale KGs and six different sub-domain tasks to evaluate our method and open-sourced it for subsequent research. We evaluated our approach based on constructed KPI benchmarks using diverse backbone models in heterogeneous downstream tasks. The experimental results show that our framework brings significant performance gains, along with its generality, efficiency, and transferability.
MyGO: Discrete Modality Information as Fine-Grained Tokens for Multi-modal Knowledge Graph Completion
Apr 15, 2024



Multi-modal knowledge graphs (MMKG) store structured world knowledge containing rich multi-modal descriptive information. To overcome their inherent incompleteness, multi-modal knowledge graph completion (MMKGC) aims to discover unobserved knowledge from given MMKGs, leveraging both structural information from the triples and multi-modal information of the entities. Existing MMKGC methods usually extract multi-modal features with pre-trained models and employ a fusion module to integrate multi-modal features with triple prediction. However, this often results in a coarse handling of multi-modal data, overlooking the nuanced, fine-grained semantic details and their interactions. To tackle this shortfall, we introduce a novel framework MyGO to process, fuse, and augment the fine-grained modality information from MMKGs. MyGO tokenizes multi-modal raw data as fine-grained discrete tokens and learns entity representations with a cross-modal entity encoder. To further augment the multi-modal representations, MyGO incorporates fine-grained contrastive learning to highlight the specificity of the entity representations. Experiments on standard MMKGC benchmarks reveal that our method surpasses 20 of the latest models, underlining its superior performance. Code and data are available at https://github.com/zjukg/MyGO
The Power of Noise: Toward a Unified Multi-modal Knowledge Graph Representation Framework
Mar 20, 2024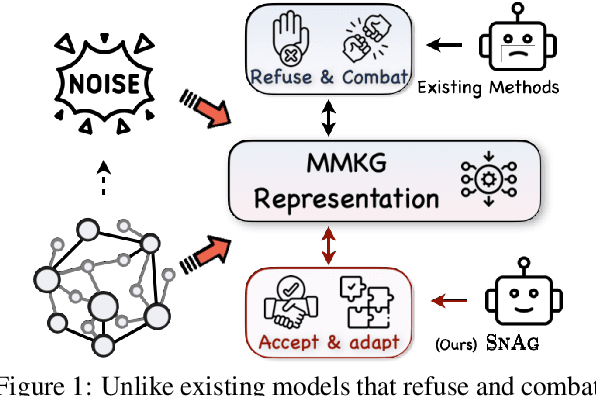
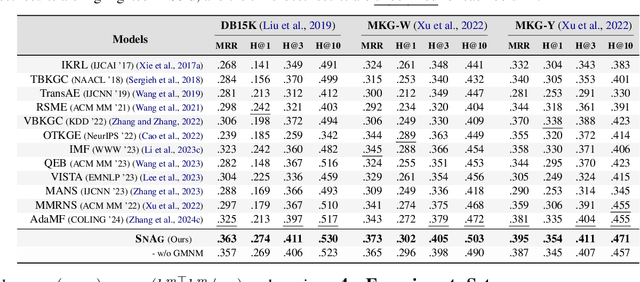
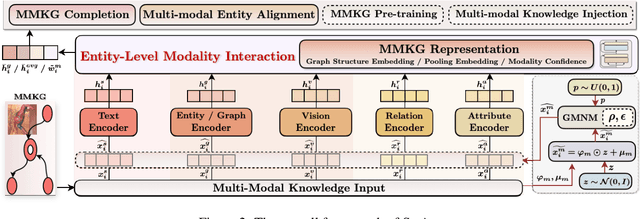
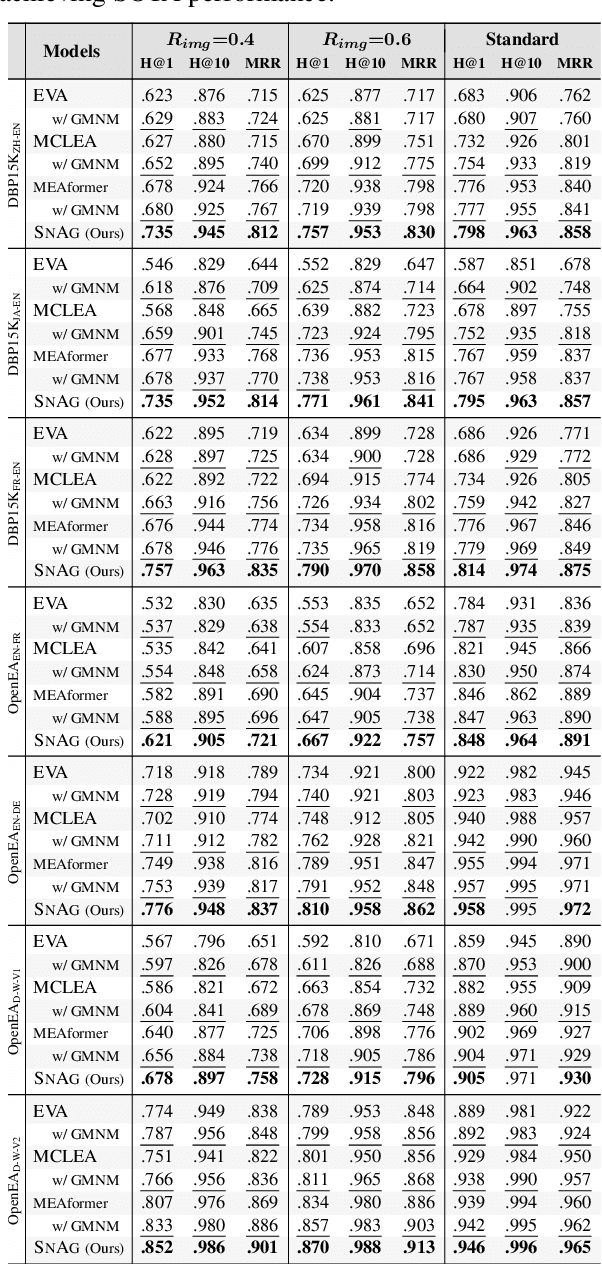
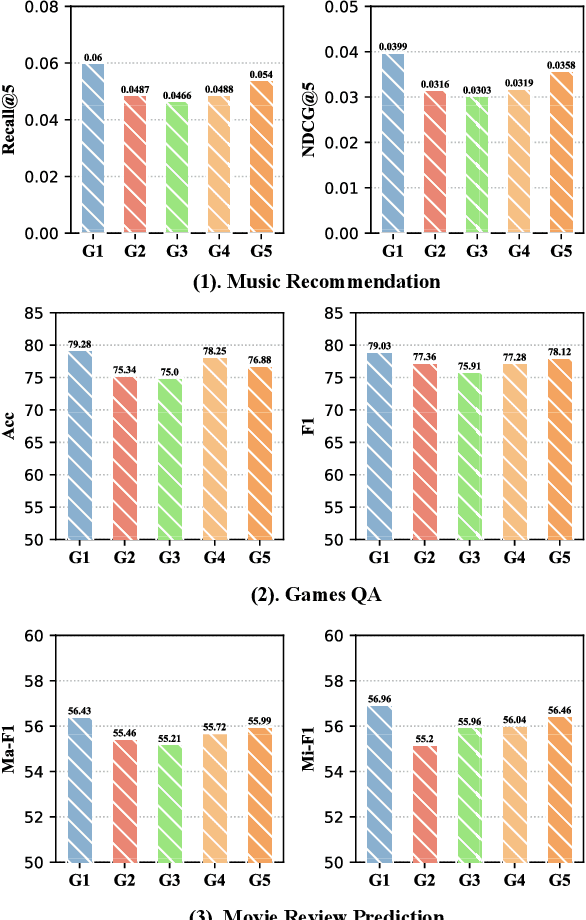
The advancement of Multi-modal Pre-training highlights the necessity for a robust Multi-Modal Knowledge Graph (MMKG) representation learning framework. This framework is crucial for integrating structured knowledge into multi-modal Large Language Models (LLMs) at scale, aiming to alleviate issues like knowledge misconceptions and multi-modal hallucinations. In this work, to evaluate models' ability to accurately embed entities within MMKGs, we focus on two widely researched tasks: Multi-modal Knowledge Graph Completion (MKGC) and Multi-modal Entity Alignment (MMEA). Building on this foundation, we propose a novel SNAG method that utilizes a Transformer-based architecture equipped with modality-level noise masking for the robust integration of multi-modal entity features in KGs. By incorporating specific training objectives for both MKGC and MMEA, our approach achieves SOTA performance across a total of ten datasets (three for MKGC and seven for MEMA), demonstrating its robustness and versatility. Besides, SNAG can not only function as a standalone model but also enhance other existing methods, providing stable performance improvements. Our code and data are available at: https://github.com/zjukg/SNAG.
Knowledge Graphs Meet Multi-Modal Learning: A Comprehensive Survey
Feb 26, 2024



Knowledge Graphs (KGs) play a pivotal role in advancing various AI applications, with the semantic web community's exploration into multi-modal dimensions unlocking new avenues for innovation. In this survey, we carefully review over 300 articles, focusing on KG-aware research in two principal aspects: KG-driven Multi-Modal (KG4MM) learning, where KGs support multi-modal tasks, and Multi-Modal Knowledge Graph (MM4KG), which extends KG studies into the MMKG realm. We begin by defining KGs and MMKGs, then explore their construction progress. Our review includes two primary task categories: KG-aware multi-modal learning tasks, such as Image Classification and Visual Question Answering, and intrinsic MMKG tasks like Multi-modal Knowledge Graph Completion and Entity Alignment, highlighting specific research trajectories. For most of these tasks, we provide definitions, evaluation benchmarks, and additionally outline essential insights for conducting relevant research. Finally, we discuss current challenges and identify emerging trends, such as progress in Large Language Modeling and Multi-modal Pre-training strategies. This survey aims to serve as a comprehensive reference for researchers already involved in or considering delving into KG and multi-modal learning research, offering insights into the evolving landscape of MMKG research and supporting future work.
ASGEA: Exploiting Logic Rules from Align-Subgraphs for Entity Alignment
Feb 16, 2024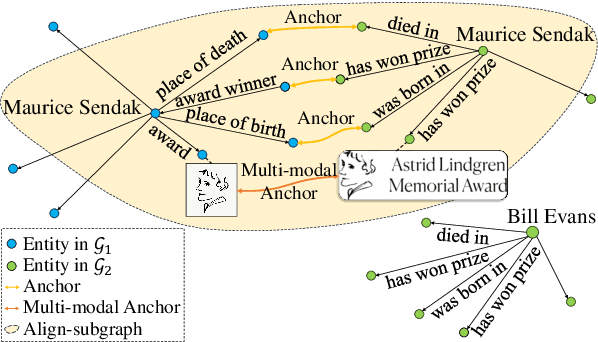
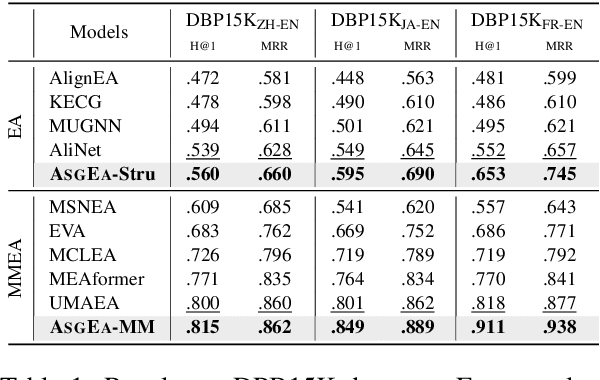
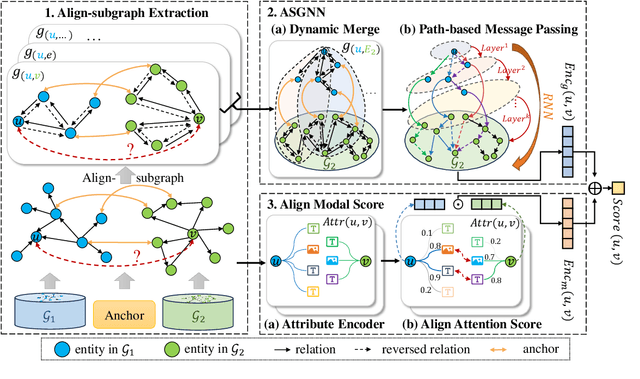
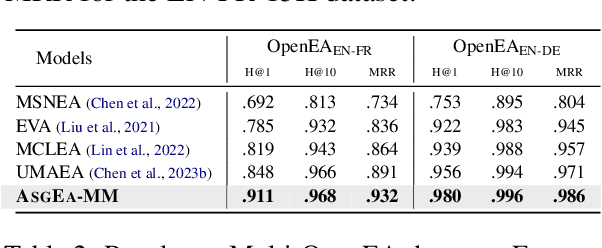
Entity alignment (EA) aims to identify entities across different knowledge graphs that represent the same real-world objects. Recent embedding-based EA methods have achieved state-of-the-art performance in EA yet faced interpretability challenges as they purely rely on the embedding distance and neglect the logic rules behind a pair of aligned entities. In this paper, we propose the Align-Subgraph Entity Alignment (ASGEA) framework to exploit logic rules from Align-Subgraphs. ASGEA uses anchor links as bridges to construct Align-Subgraphs and spreads along the paths across KGs, which distinguishes it from the embedding-based methods. Furthermore, we design an interpretable Path-based Graph Neural Network, ASGNN, to effectively identify and integrate the logic rules across KGs. We also introduce a node-level multi-modal attention mechanism coupled with multi-modal enriched anchors to augment the Align-Subgraph. Our experimental results demonstrate the superior performance of ASGEA over the existing embedding-based methods in both EA and Multi-Modal EA (MMEA) tasks. Our code will be available soon.
Universal Multi-modal Entity Alignment via Iteratively Fusing Modality Similarity Paths
Oct 13, 2023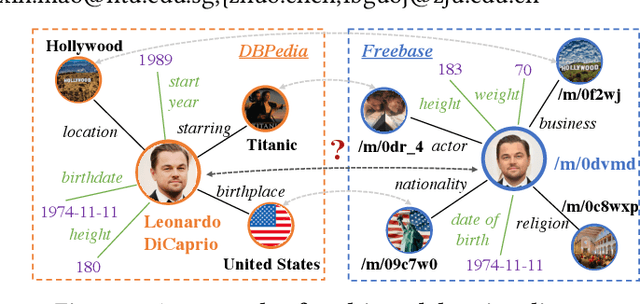

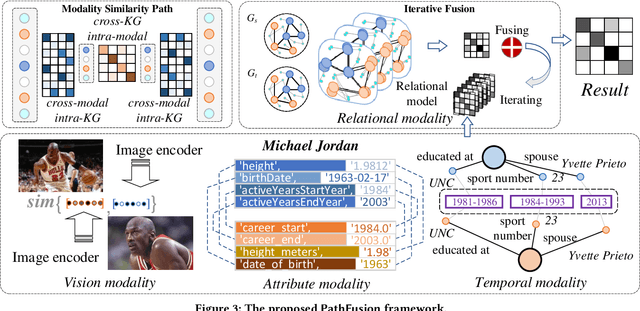
The objective of Entity Alignment (EA) is to identify equivalent entity pairs from multiple Knowledge Graphs (KGs) and create a more comprehensive and unified KG. The majority of EA methods have primarily focused on the structural modality of KGs, lacking exploration of multi-modal information. A few multi-modal EA methods have made good attempts in this field. Still, they have two shortcomings: (1) inconsistent and inefficient modality modeling that designs complex and distinct models for each modality; (2) ineffective modality fusion due to the heterogeneous nature of modalities in EA. To tackle these challenges, we propose PathFusion, consisting of two main components: (1) MSP, a unified modeling approach that simplifies the alignment process by constructing paths connecting entities and modality nodes to represent multiple modalities; (2) IRF, an iterative fusion method that effectively combines information from different modalities using the path as an information carrier. Experimental results on real-world datasets demonstrate the superiority of PathFusion over state-of-the-art methods, with 22.4%-28.9% absolute improvement on Hits@1, and 0.194-0.245 absolute improvement on MRR.