 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinker: Training LLMs in Hierarchical Thinking for Deep Search via Multi-Turn Interaction
Nov 14, 2025
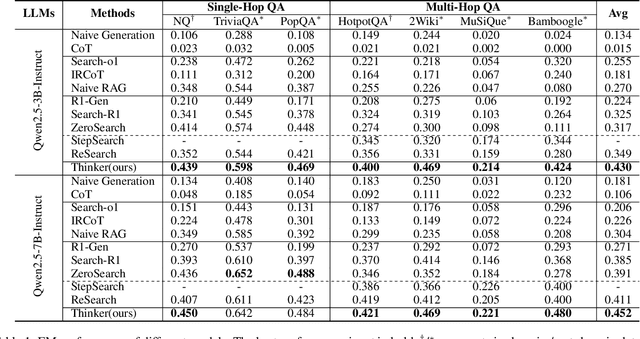
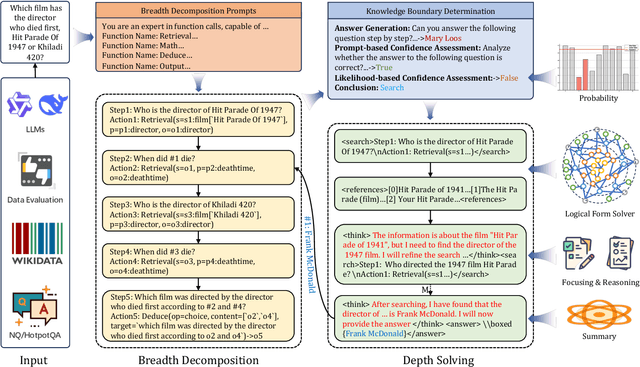
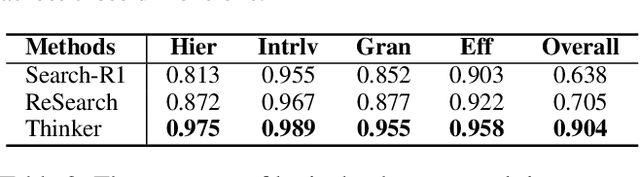
Efficient retrieval of external knowledge bases and web pages is crucial for enhancing the reasoning abilities of LLMs. Previous works on training LLMs to leverage external retrievers for solving complex problems have predominantly employed end-to-end reinforcement learning. However, these approaches neglect supervision over the reasoning process, making it difficult to guarantee logical coherence and rigor. To address these limitations, we propose Thinker, a hierarchical thinking model for deep search through multi-turn interaction, making the reasoning process supervisable and verifiable. It decomposes complex problems into independently solvable sub-problems, each dually represented in both natural language and an equivalent logical function to support knowledge base and web searches. Concurrently, dependencies between sub-problems are passed as parameters via these logical functions, enhancing the logical coherence of the problem-solving process. To avoid unnecessary external searches, we perform knowledge boundary determination to check if a sub-problem is within the LLM's intrinsic knowledge, allowing it to answer directly. Experimental results indicate that with as few as several hundred training samples, the performance of Thinker is competitive with established baselines. Furthermore, when scaled to the full training set, Thinker significantly outperforms these methods across various datasets and model sizes. The source code is available at https://github.com/OpenSPG/KAG-Thinker.
K-ON: Stacking Knowledge On the Head Layer of Large Language Model
Feb 10, 2025



Recent advancements in large language models (LLMs) have significantly improved various natural language processing (NLP) tasks. Typically, LLMs are trained to predict the next token, aligning well with many NLP tasks. However, in knowledge graph (KG) scenarios, entities are the fundamental units and identifying an entity requires at least several tokens. This leads to a granularity mismatch between KGs and natural languages. To address this issue, we propose K-ON, which integrates KG knowledge into the LLM by employing multiple head layers for next k-step prediction. K-ON can not only generate entity-level results in one step, but also enables contrastive loss against entities, which is the most powerful tool in KG representation learning. Experimental results show that K-ON outperforms state-of-the-art methods that incorporate text and even the other modalities.
OntoTune: Ontology-Driven Self-training for Aligning Large Language Models
Feb 08, 2025



Existing domain-specific Large Language Models (LLMs) are typically developed by fine-tuning general-purposed LLMs with large-scale domain-specific corpora. However, training on large-scale corpora often fails to effectively organize domain knowledge of LLMs, leading to fragmented understanding. Inspired by how humans connect concepts and organize knowledge through mind maps, we aim to emulate this approach by using ontology with hierarchical conceptual knowledge to reorganize LLM's domain knowledge. From this perspective, we propose an ontology-driven self-training framework called OntoTune, which aims to align LLMs with ontology through in-context learning, enabling the generation of responses guided by the ontology. We leverage in-context learning to identify whether the LLM has acquired the specific concept's ontology knowledge, and select the entries not yet mastered by LLM as the training set to further align the LLM with ontology. Compared to existing domain LLMs based on newly collected large-scale domain-specific corpora, our OntoTune, which relies on the existing, long-term developed ontology and LLM itself, significantly reduces data maintenance costs and offers improved generalization ability. We conduct our study in the medical domain to evaluate the effectiveness of OntoTune, utilizing a standardized medical ontology, SNOMED CT as our ontology source. Experimental results demonstrate that OntoTune achieves state-of-the-art performance in both in-ontology task hypernym discovery and out-of-ontology task medical domain QA. Moreover, compared to the latest direct ontology injection method TaxoLLaMA, our OntoTune better preserves original knowledge of LLM. The code and data are available at https://github.com/zjukg/OntoTune.
MKGL: Mastery of a Three-Word Language
Oct 10, 2024



Large language models (LLMs) have significantly advanced performance across a spectrum of natural language processing (NLP) tasks. Yet, their application to knowledge graphs (KGs), which describe facts in the form of triplets and allow minimal hallucinations, remains an underexplored frontier. In this paper, we investigate the integration of LLMs with KGs by introducing a specialized KG Language (KGL), where a sentence precisely consists of an entity noun, a relation verb, and ends with another entity noun. Despite KGL's unfamiliar vocabulary to the LLM, we facilitate its learning through a tailored dictionary and illustrative sentences, and enhance context understanding via real-time KG context retrieval and KGL token embedding augmentation. Our results reveal that LLMs can achieve fluency in KGL, drastically reducing errors compared to conventional KG embedding methods on KG completion. Furthermore, our enhanced LLM shows exceptional competence in generating accurate three-word sentences from an initial entity and interpreting new unseen terms out of KGs.