 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Correction Distillation for Structured Data Question Answering
Nov 17, 2025Structured data question answering (QA), including table QA, Knowledge Graph (KG) QA, and temporal KG QA, is a pivotal research area. Advances in large language models (LLMs) have driven significant progress in unified structural QA frameworks like TrustUQA. However, these frameworks face challenges when applied to small-scale LLMs since small-scale LLMs are prone to errors in generating structured queries. To improve the structured data QA ability of small-scale LLMs, we propose a self-correction distillation (SCD) method. In SCD, an error prompt mechanism (EPM) is designed to detect errors and provide customized error messages during inference, and a two-stage distillation strategy is designed to transfer large-scale LLMs' query-generation and error-correction capabilities to small-scale LLM. Experiments across 5 benchmarks with 3 structured data types demonstrate that our SCD achieves the best performance and superior generalization on small-scale LLM (8B) compared to other distillation methods, and closely approaches the performance of GPT4 on some datasets. Furthermore, large-scale LLMs equipped with EPM surpass the state-of-the-art results on most datasets.
Multi-modal Knowledge Graph Generation with Semantics-enriched Prompts
Apr 18, 2025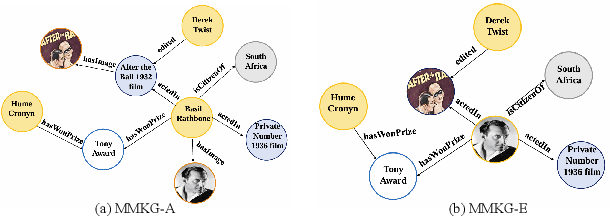
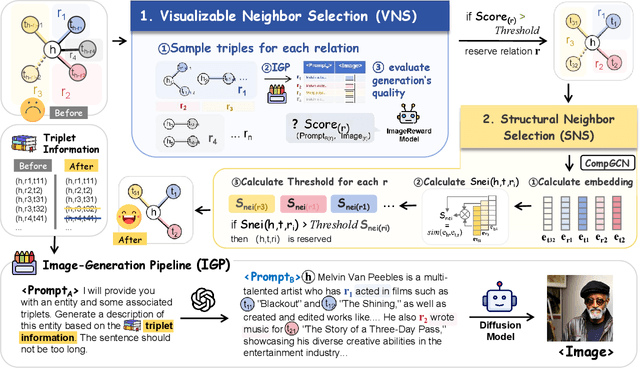
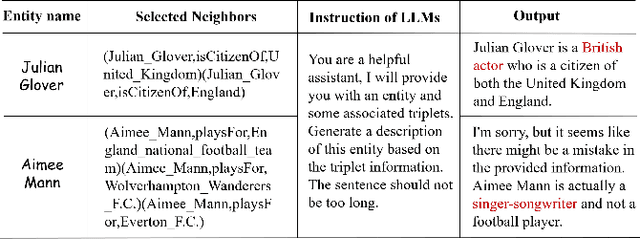

Multi-modal Knowledge Graphs (MMKGs) have been widely applied across various domains for knowledge representation. However, the existing MMKGs are significantly fewer than required, and their construction faces numerous challenges, particularly in ensuring the selection of high-quality, contextually relevant images for knowledge graph enrichment. To address these challenges, we present a framework for constructing MMKGs from conventional KGs. Furthermore, to generate higher-quality images that are more relevant to the context in the given knowledge graph, we designed a neighbor selection method called Visualizable Structural Neighbor Selection (VSNS). This method consists of two modules: Visualizable Neighbor Selection (VNS) and Structural Neighbor Selection (SNS). The VNS module filters relations that are difficult to visualize, while the SNS module selects neighbors that most effectively capture the structural characteristics of the entity. To evaluate the quality of the generated images, we performed qualitative and quantitative evaluations on two datasets, MKG-Y and DB15K. The experimental results indicate that using the VSNS method to select neighbors results in higher-quality images that are more relevant to the knowledge graph.
Croppable Knowledge Graph Embedding
Jul 03, 2024Knowledge Graph Embedding (KGE) is a common method for Knowledge Graphs (KGs) to serve various artificial intelligence tasks. The suitable dimensions of the embeddings depend on the storage and computing conditions of the specific application scenarios. Once a new dimension is required, a new KGE model needs to be trained from scratch, which greatly increases the training cost and limits the efficiency and flexibility of KGE in serving various scenarios. In this work, we propose a novel KGE training framework MED, through which we could train once to get a croppable KGE model applicable to multiple scenarios with different dimensional requirements, sub-models of the required dimensions can be cropped out of it and used directly without any additional training. In MED, we propose a mutual learning mechanism to improve the low-dimensional sub-models performance and make the high-dimensional sub-models retain the capacity that low-dimensional sub-models have, an evolutionary improvement mechanism to promote the high-dimensional sub-models to master the knowledge that the low-dimensional sub-models can not learn, and a dynamic loss weight to balance the multiple losses adaptively. Experiments on 3 KGE models over 4 standard KG completion datasets, 3 real application scenarios over a real-world large-scale KG, and the experiments of extending MED to the language model BERT show the effectiveness, high efficiency, and flexible extensibility of MED.
SF-GNN: Self Filter for Message Lossless Propagation in Deep Graph Neural Network
Jul 03, 2024



Graph Neural Network (GNN), with the main idea of encoding graph structure information of graphs by propagation and aggregation, has developed rapidly. It achieved excellent performance in representation learning of multiple types of graphs such as homogeneous graphs, heterogeneous graphs, and more complex graphs like knowledge graphs. However, merely stacking GNN layers may not improve the model's performance and can even be detrimental. For the phenomenon of performance degradation in deep GNNs, we propose a new perspective. Unlike the popular explanations of over-smoothing or over-squashing, we think the issue arises from the interference of low-quality node representations during message propagation. We introduce a simple and general method, SF-GNN, to address this problem. In SF-GNN, we define two representations for each node, one is the node representation that represents the feature of the node itself, and the other is the message representation specifically for propagating messages to neighbor nodes. A self-filter module evaluates the quality of the node representation and decides whether to integrate it into the message propagation based on this quality assessment. Experiments on node classification tasks for both homogeneous and heterogeneous graphs, as well as link prediction tasks on knowledge graphs, demonstrate that our method can be applied to various GNN models and outperforms state-of-the-art baseline methods in addressing deep GNN degradation.
TrustUQA: A Trustful Framework for Unified Structured Data Question Answering
Jun 27, 2024



Natural language question answering (QA) over structured data sources such as tables and knowledge graphs (KGs) have been widely investigated, for example with Large Language Models (LLMs). The main solutions include question to formal query parsing and retrieval-based answer generation. However, current methods of the former often suffer from weak generalization, failing to dealing with multiple sources simultaneously, while the later is limited in trustfulness. In this paper, we propose UnifiedTQA, a trustful QA framework that can simultaneously support multiple types of structured data in a unified way. To this end, it adopts an LLM-friendly and unified knowledge representation method called Condition Graph (CG), and uses an LLM and demonstration-based two-level method for CG querying. For enhancement, it is also equipped with dynamic demonstration retrieval. We have evaluated UnifiedTQA with 5 benchmarks covering 3 types of structured data. It outperforms 2 existing unified structured data QA methods and in comparison with the baselines that are specific to a data type, it achieves state-of-the-art on 2 of them. Further more, we demonstrates potential of our method for more general QA tasks, QA over mixed structured data and QA across structured data.
Knowledge Graphs Meet Multi-Modal Learning: A Comprehensive Survey
Feb 26, 2024



Knowledge Graphs (KGs) play a pivotal role in advancing various AI applications, with the semantic web community's exploration into multi-modal dimensions unlocking new avenues for innovation. In this survey, we carefully review over 300 articles, focusing on KG-aware research in two principal aspects: KG-driven Multi-Modal (KG4MM) learning, where KGs support multi-modal tasks, and Multi-Modal Knowledge Graph (MM4KG), which extends KG studies into the MMKG realm. We begin by defining KGs and MMKGs, then explore their construction progress. Our review includes two primary task categories: KG-aware multi-modal learning tasks, such as Image Classification and Visual Question Answering, and intrinsic MMKG tasks like Multi-modal Knowledge Graph Completion and Entity Alignment, highlighting specific research trajectories. For most of these tasks, we provide definitions, evaluation benchmarks, and additionally outline essential insights for conducting relevant research. Finally, we discuss current challenges and identify emerging trends, such as progress in Large Language Modeling and Multi-modal Pre-training strategies. This survey aims to serve as a comprehensive reference for researchers already involved in or considering delving into KG and multi-modal learning research, offering insights into the evolving landscape of MMKG research and supporting future work.
Structure Pretraining and Prompt Tuning for Knowledge Graph Transfer
Mar 03, 2023Knowledge graphs (KG) are essential background knowledge providers in many tasks. When designing models for KG-related tasks, one of the key tasks is to devise the Knowledge Representation and Fusion (KRF) module that learns the representation of elements from KGs and fuses them with task representations. While due to the difference of KGs and perspectives to be considered during fusion across tasks, duplicate and ad hoc KRF modules design are conducted among tasks. In this paper, we propose a novel knowledge graph pretraining model KGTransformer that could serve as a uniform KRF module in diverse KG-related tasks. We pretrain KGTransformer with three self-supervised tasks with sampled sub-graphs as input. For utilization, we propose a general prompt-tuning mechanism regarding task data as a triple prompt to allow flexible interactions between task KGs and task data. We evaluate pretrained KGTransformer on three tasks, triple classification, zero-shot image classification, and question answering. KGTransformer consistently achieves better results than specifically designed task models. Through experiments, we justify that the pretrained KGTransformer could be used off the shelf as a general and effective KRF module across KG-related tasks. The code and datasets are available at https://github.com/zjukg/KGTransformer.
Entity-Agnostic Representation Learning for Parameter-Efficient Knowledge Graph Embedding
Feb 03, 2023



We propose an entity-agnostic representation learning method for handling the problem of inefficient parameter storage costs brought by embedding knowledge graphs. Conventional knowledge graph embedding methods map elements in a knowledge graph, including entities and relations, into continuous vector spaces by assigning them one or multiple specific embeddings (i.e., vector representations). Thus the number of embedding parameters increases linearly as the growth of knowledge graphs. In our proposed model, Entity-Agnostic Representation Learning (EARL), we only learn the embeddings for a small set of entities and refer to them as reserved entities. To obtain the embeddings for the full set of entities, we encode their distinguishable information from their connected relations, k-nearest reserved entities, and multi-hop neighbors. We learn universal and entity-agnostic encoders for transforming distinguishable information into entity embeddings. This approach allows our proposed EARL to have a static, efficient, and lower parameter count than conventional knowledge graph embedding methods. Experimental results show that EARL uses fewer parameters and performs better on link prediction tasks than baselines, reflecting its parameter efficiency.
NeuralKG: An Open Source Library for Diverse Representation Learning of Knowledge Graphs
Feb 25, 2022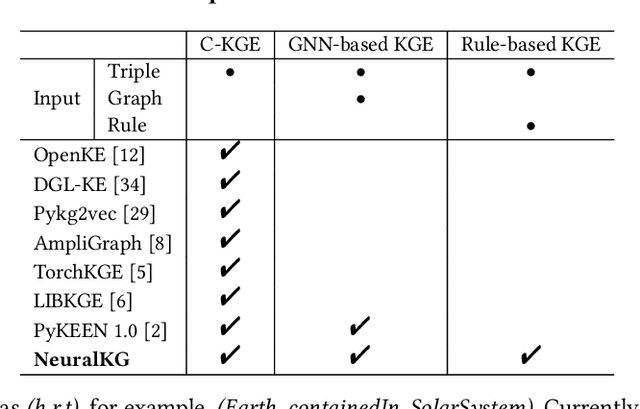
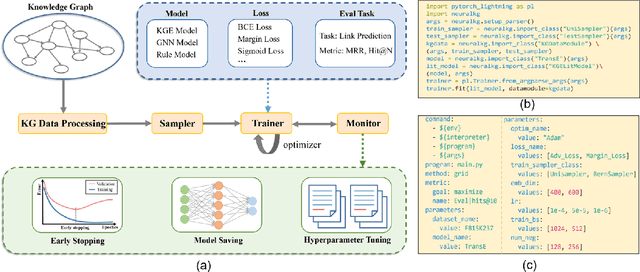
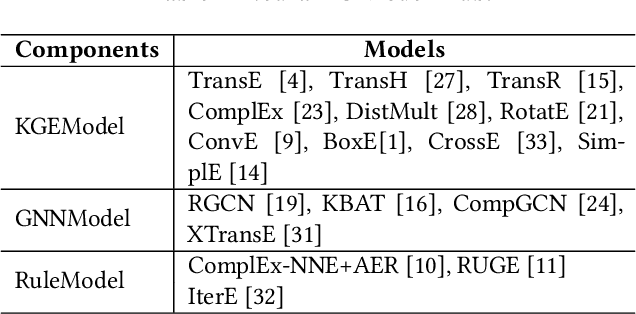
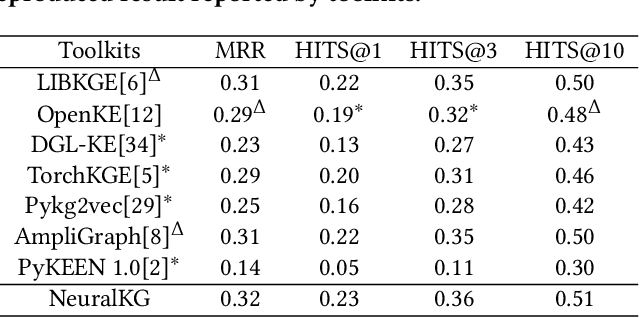
NeuralKG is an open-source Python-based library for diverse representation learning of knowledge graphs. It implements three different series of Knowledge Graph Embedding (KGE) methods, including conventional KGEs, GNN-based KGEs, and Rule-based KGEs. With a unified framework, NeuralKG successfully reproduces link prediction results of these methods on benchmarks, freeing users from the laborious task of reimplementing them, especially for some methods originally written in non-python programming languages. Besides, NeuralKG is highly configurable and extensible. It provides various decoupled modules that can be mixed and adapted to each other. Thus with NeuralKG, developers and researchers can quickly implement their own designed models and obtain the optimal training methods to achieve the best performance efficiently. We built an website in http://neuralkg.zjukg.cn to organize an open and shared KG representation learning community. The source code is all publicly released at https://github.com/zjukg/NeuralKG.
Standing on the Shoulders of Predecessors: Meta-Knowledge Transfer for Knowledge Graphs
Oct 27, 2021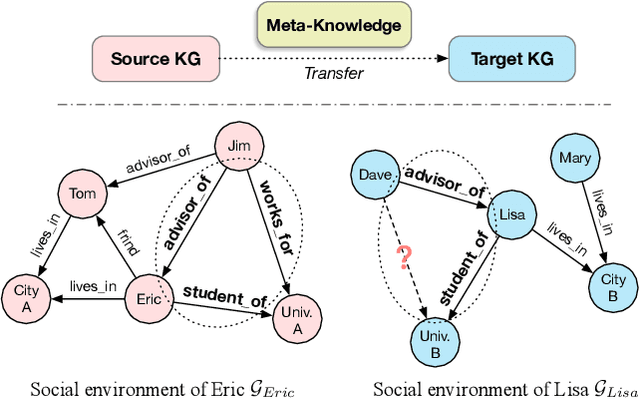
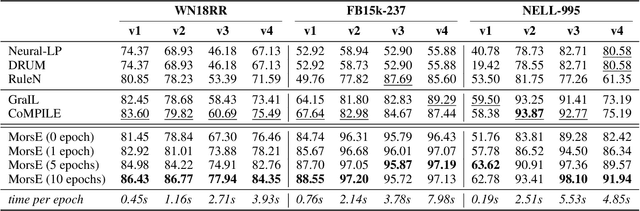
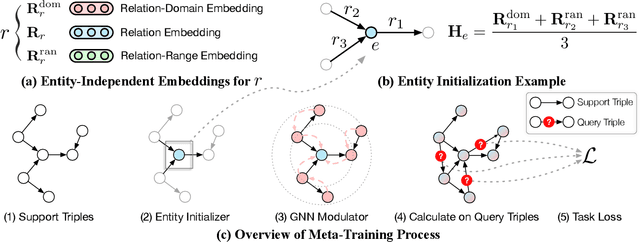
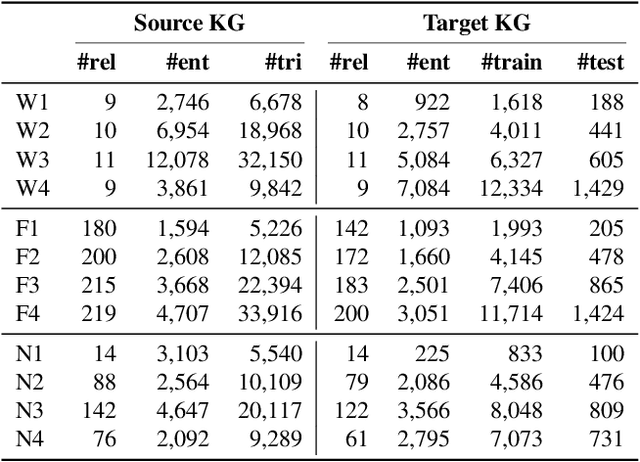
Knowledge graphs (KGs) have become widespread, and various knowledge graphs are constructed incessantly to support many in-KG and out-of-KG applications. During the construction of KGs, although new KGs may contain new entities with respect to constructed KGs, some entity-independent knowledge can be transferred from constructed KGs to new KGs. We call such knowledge meta-knowledge, and refer to the problem of transferring meta-knowledge from constructed (source) KGs to new (target) KGs to improve the performance of tasks on target KGs as meta-knowledge transfer for knowledge graphs. However, there is no available general framework that can tackle meta-knowledge transfer for both in-KG and out-of-KG tasks uniformly. Therefore, in this paper, we propose a framework, MorsE, which means conducting Meta-Learning for Meta-Knowledge Transfer via Knowledge Graph Embedding. MorsE represents the meta-knowledge via Knowledge Graph Embedding and learns the meta-knowledge by Meta-Learning. Specifically, MorsE uses an entity initializer and a Graph Neural Network (GNN) modulator to entity-independently obtain entity embeddings given a KG and is trained following the meta-learning setting to gain the ability of effectively obtaining embeddings. Experimental results on meta-knowledge transfer for both in-KG and out-of-KG tasks show that MorsE is able to learn and transfer meta-knowledge between KGs effectively, and outperforms existing state-of-the-art models.