 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Transformer with Multi-level Fusion for Multimodal Knowledge Graph Completion
May 04, 2022
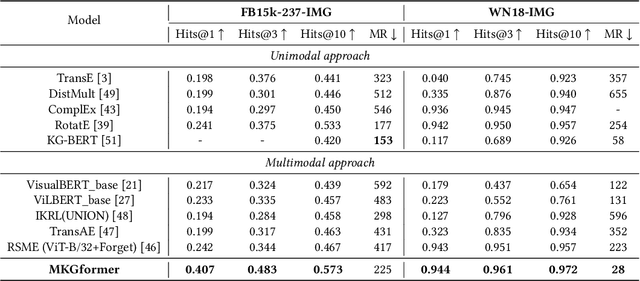
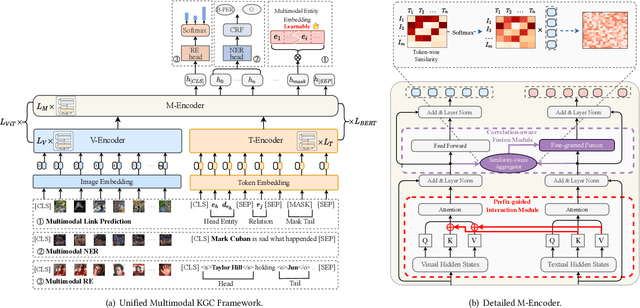
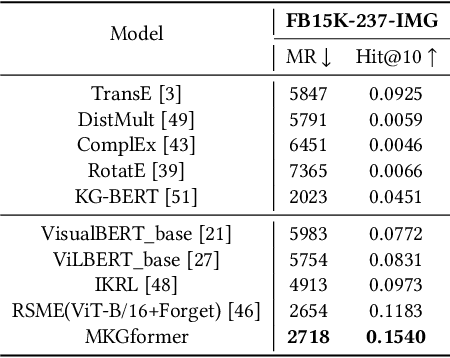
Multimodal Knowledge Graphs (MKGs), which organize visual-text factual knowledge, have recently been successfully applied to tasks such as information retrieval, question answering, and recommendation system. Since most MKGs are far from complete, extensive knowledge graph completion studies have been proposed focusing on the multimodal entity, relation extraction and link prediction. However, different tasks and modalities require changes to the model architecture, and not all images/objects are relevant to text input, which hinders the applicability to diverse real-world scenarios. In this paper, we propose a hybrid transformer with multi-level fusion to address those issues. Specifically, we leverage a hybrid transformer architecture with unified input-output for diverse multimodal knowledge graph completion tasks. Moreover, we propose multi-level fusion, which integrates visual and text representation via coarse-grained prefix-guided interaction and fine-grained correlation-aware fusion modules. We conduct extensive experiments to validate that our MKGformer can obtain SOTA performance on four datasets of multimodal link prediction, multimodal RE, and multimodal NER. Code is available in https://github.com/zjunlp/MKGformer.
MR-SVS: Singing Voice Synthesis with Multi-Reference Encoder
Jan 11, 2022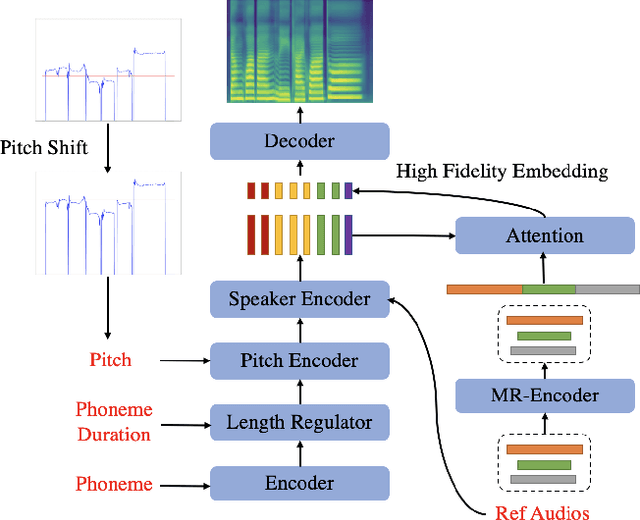

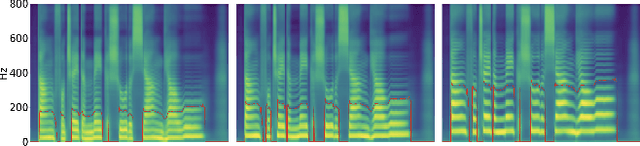
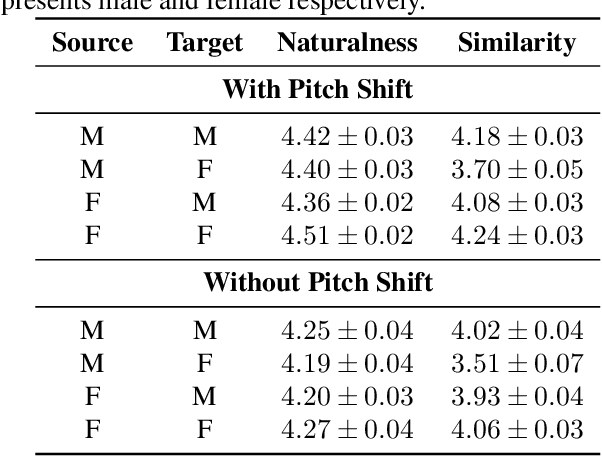
Multi-speaker singing voice synthesis is to generate the singing voice sung by different speakers. To generalize to new speakers, previous zero-shot singing adaptation methods obtain the timbre of the target speaker with a fixed-size embedding from single reference audio. However, they face several challenges: 1) the fixed-size speaker embedding is not powerful enough to capture full details of the target timbre; 2) single reference audio does not contain sufficient timbre information of the target speaker; 3) the pitch inconsistency between different speakers also leads to a degradation in the generated voice. In this paper, we propose a new model called MR-SVS to tackle these problems. Specifically, we employ both a multi-reference encoder and a fixed-size encoder to encode the timbre of the target speaker from multiple reference audios. The Multi-reference encoder can capture more details and variations of the target timbre. Besides, we propose a well-designed pitch shift method to address the pitch inconsistency problem. Experiments indicate that our method outperforms the baseline method both in naturalness and similarity.
Standing on the Shoulders of Predecessors: Meta-Knowledge Transfer for Knowledge Graphs
Oct 27, 2021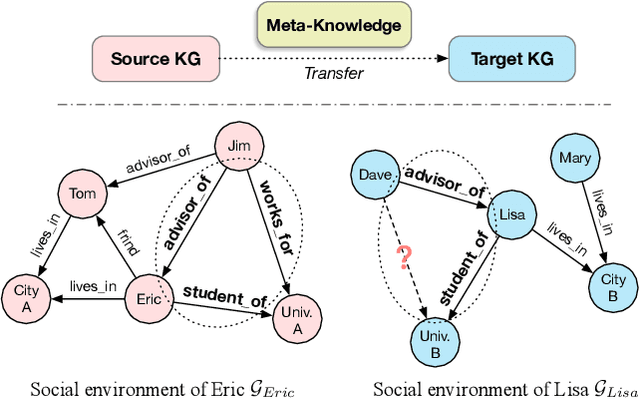
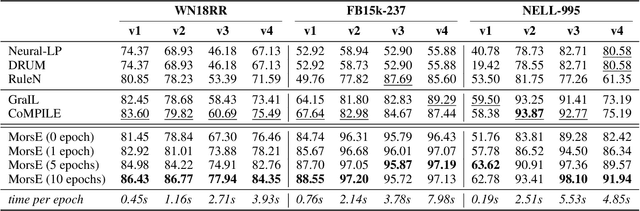
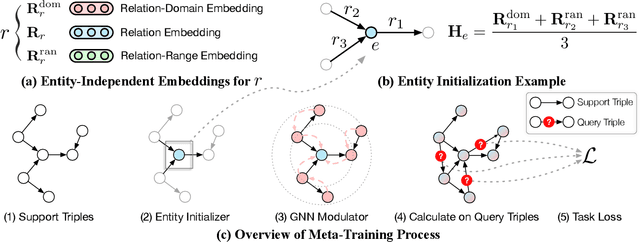
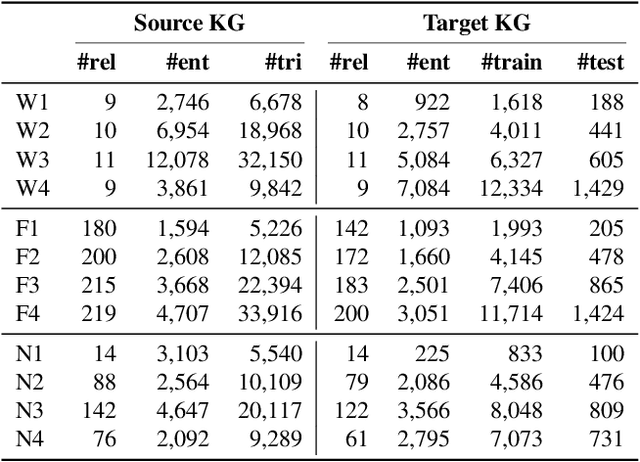
Knowledge graphs (KGs) have become widespread, and various knowledge graphs are constructed incessantly to support many in-KG and out-of-KG applications. During the construction of KGs, although new KGs may contain new entities with respect to constructed KGs, some entity-independent knowledge can be transferred from constructed KGs to new KGs. We call such knowledge meta-knowledge, and refer to the problem of transferring meta-knowledge from constructed (source) KGs to new (target) KGs to improve the performance of tasks on target KGs as meta-knowledge transfer for knowledge graphs. However, there is no available general framework that can tackle meta-knowledge transfer for both in-KG and out-of-KG tasks uniformly. Therefore, in this paper, we propose a framework, MorsE, which means conducting Meta-Learning for Meta-Knowledge Transfer via Knowledge Graph Embedding. MorsE represents the meta-knowledge via Knowledge Graph Embedding and learns the meta-knowledge by Meta-Learning. Specifically, MorsE uses an entity initializer and a Graph Neural Network (GNN) modulator to entity-independently obtain entity embeddings given a KG and is trained following the meta-learning setting to gain the ability of effectively obtaining embeddings. Experimental results on meta-knowledge transfer for both in-KG and out-of-KG tasks show that MorsE is able to learn and transfer meta-knowledge between KGs effectively, and outperforms existing state-of-the-art models.
WSRGlow: A Glow-based Waveform Generative Model for Audio Super-Resolution
Jun 16, 2021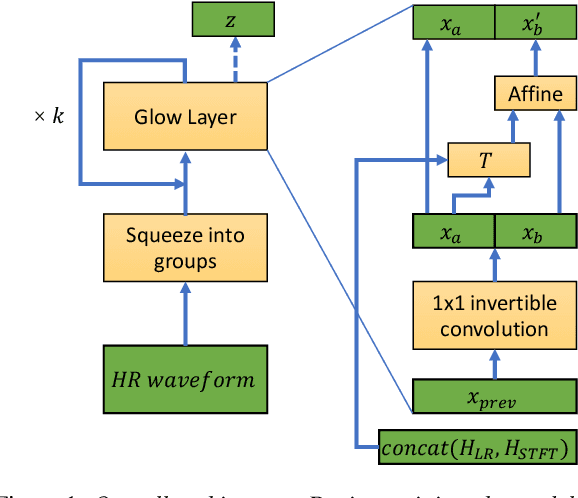

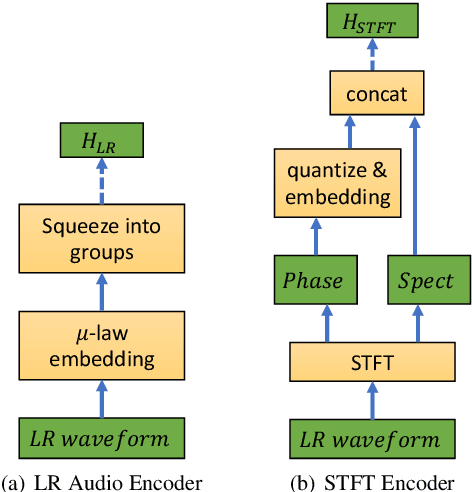
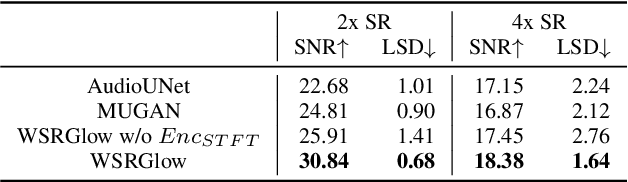
Audio super-resolution is the task of constructing a high-resolution (HR) audio from a low-resolution (LR) audio by adding the missing band. Previous methods based on convolutional neural networks and mean squared error training objective have relatively low performance, while adversarial generative models are difficult to train and tune. Recently, normalizing flow has attracted a lot of attention for its high performance, simple training and fast inference. In this paper, we propose WSRGlow, a Glow-based waveform generative model to perform audio super-resolution. Specifically, 1) we integrate WaveNet and Glow to directly maximize the exact likelihood of the target HR audio conditioned on LR information; and 2) to exploit the audio information from low-resolution audio, we propose an LR audio encoder and an STFT encoder, which encode the LR information from the time domain and frequency domain respectively. The experimental results show that the proposed model is easier to train and outperforms the previous works in terms of both objective and perceptual quality. WSRGlow is also the first model to produce 48kHz waveforms from 12kHz LR audio.
Comprehensive Soccer Video Understanding: Towards Human-comparable Video Understanding System in Constrained Environment
Dec 13, 2019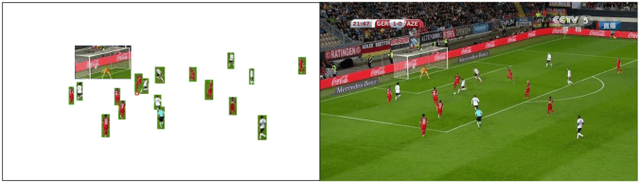
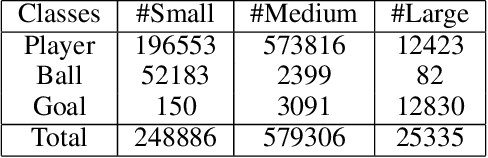
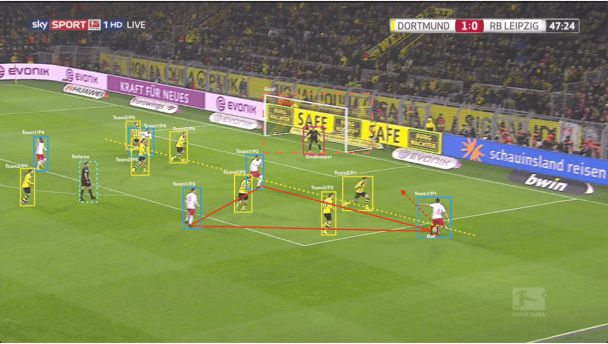
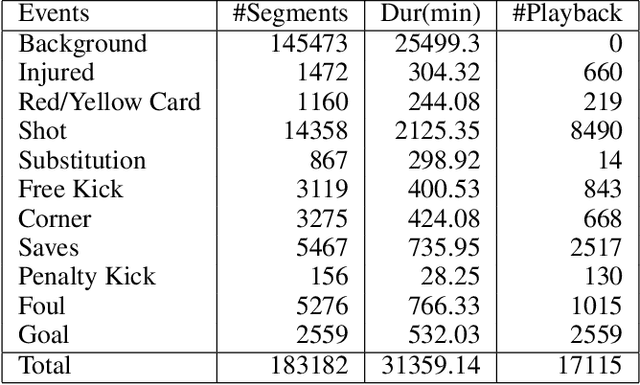
Comprehensive video understanding, a challenging task in computer vision to understand videos like humans, has been explored in ways including object detection and tracking, action classification. However, most works for video understanding mainly focus on isolated aspects of video analysis, yet ignore the inner correlation among those tasks. Sports games videos can serve as a perfect research object with restrictive conditions, while complex and challenging enough to study the core problems in computer vision comprehensively. In this paper, we propose a new soccer video database named SoccerDB with the benchmark of object detection, action recognition, temporal action detection, and highlight detection. We further survey a collection of strong baselines on SoccerDB, which have demonstrated state-of-the-art performance on each independent task in recent years. We believe that the release of SoccerDB will tremendously advance researches of combining different tasks in closed form around the comprehensive video understanding problem. Our dataset and code will be published after the paper accepted.
Comprehensive Video Understanding: Video summarization with content-based video recommender design
Oct 30, 2019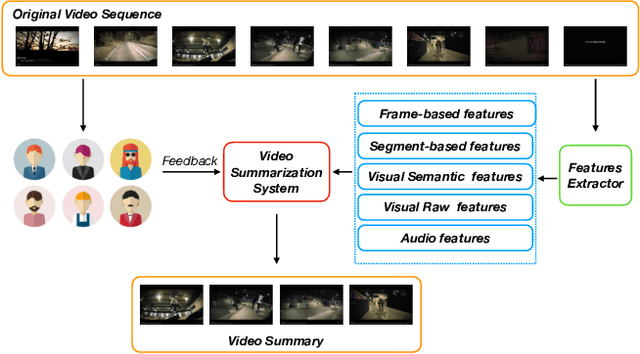
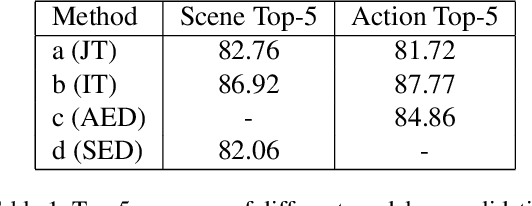
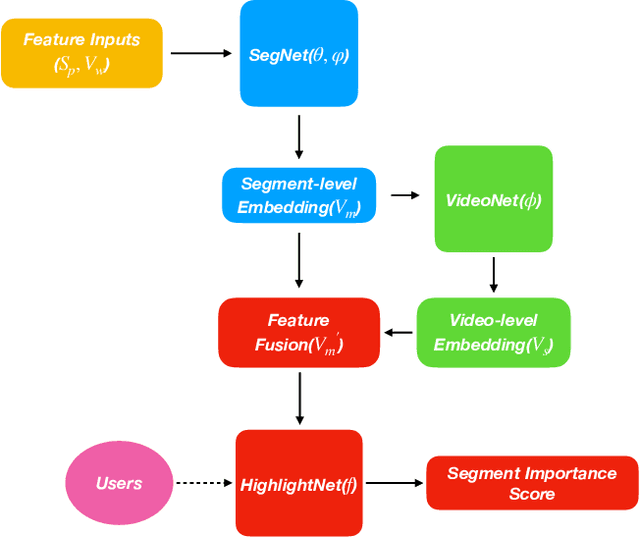
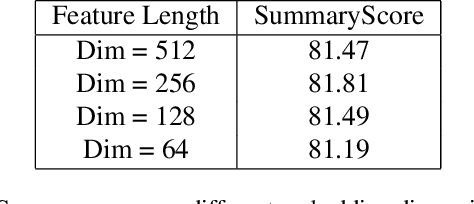
Video summarization aims to extract keyframes/shots from a long video. Previous methods mainly take diversity and representativeness of generated summaries as prior knowledge in algorithm design. In this paper, we formulate video summarization as a content-based recommender problem, which should distill the most useful content from a long video for users who suffer from information overload. A scalable deep neural network is proposed on predicting if one video segment is a useful segment for users by explicitly modelling both segment and video. Moreover, we accomplish scene and action recognition in untrimmed videos in order to find more correlations among different aspects of video understanding tasks. Also, our paper will discuss the effect of audio and visual features in summarization task. We also extend our work by data augmentation and multi-task learning for preventing the model from early-stage overfitting. The final results of our model win the first place in ICCV 2019 CoView Workshop Challenge Track.