 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMimicTalk: Mimicking a personalized and expressive 3D talking face in minutes
Oct 09, 2024



Talking face generation (TFG) aims to animate a target identity's face to create realistic talking videos. Personalized TFG is a variant that emphasizes the perceptual identity similarity of the synthesized result (from the perspective of appearance and talking style). While previous works typically solve this problem by learning an individual neural radiance field (NeRF) for each identity to implicitly store its static and dynamic information, we find it inefficient and non-generalized due to the per-identity-per-training framework and the limited training data. To this end, we propose MimicTalk, the first attempt that exploits the rich knowledge from a NeRF-based person-agnostic generic model for improving the efficiency and robustness of personalized TFG. To be specific, (1) we first come up with a person-agnostic 3D TFG model as the base model and propose to adapt it into a specific identity; (2) we propose a static-dynamic-hybrid adaptation pipeline to help the model learn the personalized static appearance and facial dynamic features; (3) To generate the facial motion of the personalized talking style, we propose an in-context stylized audio-to-motion model that mimics the implicit talking style provided in the reference video without information loss by an explicit style representation. The adaptation process to an unseen identity can be performed in 15 minutes, which is 47 times faster than previous person-dependent methods. Experiments show that our MimicTalk surpasses previous baselines regarding video quality, efficiency, and expressiveness. Source code and video samples are available at https://mimictalk.github.io .
MulliVC: Multi-lingual Voice Conversion With Cycle Consistency
Aug 08, 2024Voice conversion aims to modify the source speaker's voice to resemble the target speaker while preserving the original speech content. Despite notable advancements in voice conversion these days, multi-lingual voice conversion (including both monolingual and cross-lingual scenarios) has yet to be extensively studied. It faces two main challenges: 1) the considerable variability in prosody and articulation habits across languages; and 2) the rarity of paired multi-lingual datasets from the same speaker. In this paper, we propose MulliVC, a novel voice conversion system that only converts timbre and keeps original content and source language prosody without multi-lingual paired data. Specifically, each training step of MulliVC contains three substeps: In step one the model is trained with monolingual speech data; then, steps two and three take inspiration from back translation, construct a cyclical process to disentangle the timbre and other information (content, prosody, and other language-related information) in the absence of multi-lingual data from the same speaker. Both objective and subjective results indicate that MulliVC significantly surpasses other methods in both monolingual and cross-lingual contexts, demonstrating the system's efficacy and the viability of the three-step approach with cycle consistency. Audio samples can be found on our demo page (mullivc.github.io).
Real3D-Portrait: One-shot Realistic 3D Talking Portrait Synthesis
Jan 20, 2024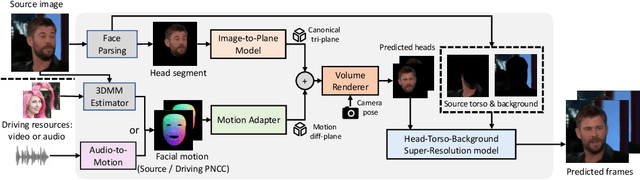

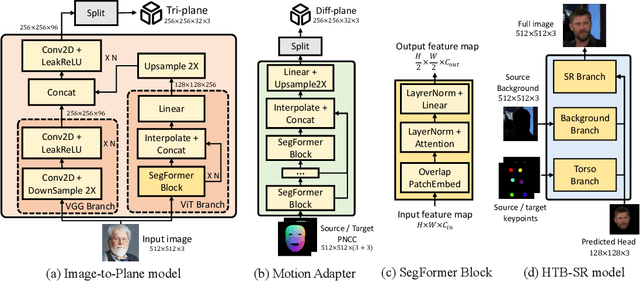
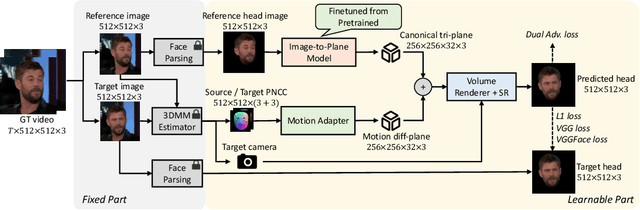
One-shot 3D talking portrait generation aims to reconstruct a 3D avatar from an unseen image, and then animate it with a reference video or audio to generate a talking portrait video. The existing methods fail to simultaneously achieve the goals of accurate 3D avatar reconstruction and stable talking face animation. Besides, while the existing works mainly focus on synthesizing the head part, it is also vital to generate natural torso and background segments to obtain a realistic talking portrait video. To address these limitations, we present Real3D-Potrait, a framework that (1) improves the one-shot 3D reconstruction power with a large image-to-plane model that distills 3D prior knowledge from a 3D face generative model; (2) facilitates accurate motion-conditioned animation with an efficient motion adapter; (3) synthesizes realistic video with natural torso movement and switchable background using a head-torso-background super-resolution model; and (4) supports one-shot audio-driven talking face generation with a generalizable audio-to-motion model. Extensive experiments show that Real3D-Portrait generalizes well to unseen identities and generates more realistic talking portrait videos compared to previous methods. Video samples and source code are available at https://real3dportrait.github.io .
C2G2: Controllable Co-speech Gesture Generation with Latent Diffusion Model
Aug 29, 2023



Co-speech gesture generation is crucial for automatic digital avatar animation. However, existing methods suffer from issues such as unstable training and temporal inconsistency, particularly in generating high-fidelity and comprehensive gestures. Additionally, these methods lack effective control over speaker identity and temporal editing of the generated gestures. Focusing on capturing temporal latent information and applying practical controlling, we propose a Controllable Co-speech Gesture Generation framework, named C2G2. Specifically, we propose a two-stage temporal dependency enhancement strategy motivated by latent diffusion models. We further introduce two key features to C2G2, namely a speaker-specific decoder to generate speaker-related real-length skeletons and a repainting strategy for flexible gesture generation/editing. Extensive experiments on benchmark gesture datasets verify the effectiveness of our proposed C2G2 compared with several state-of-the-art baselines. The link of the project demo page can be found at https://c2g2-gesture.github.io/c2_gesture
Mega-TTS 2: Zero-Shot Text-to-Speech with Arbitrary Length Speech Prompts
Jul 14, 2023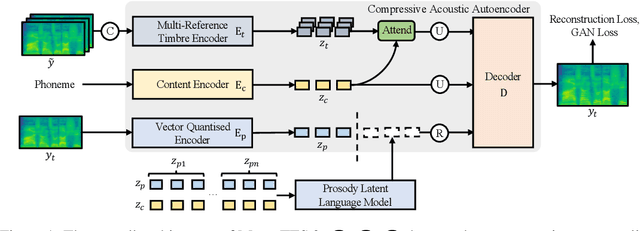
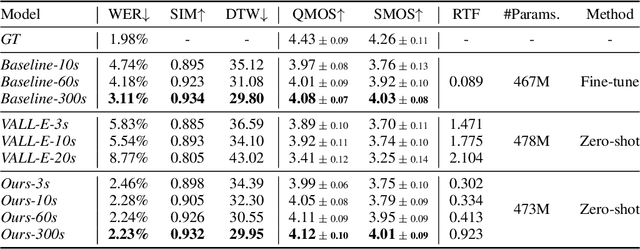
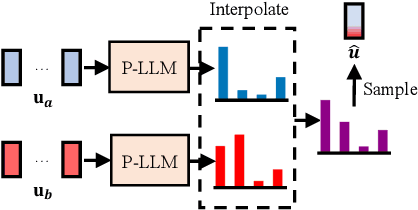

Zero-shot text-to-speech aims at synthesizing voices with unseen speech prompts. Previous large-scale multispeaker TTS models have successfully achieved this goal with an enrolled recording within 10 seconds. However, most of them are designed to utilize only short speech prompts. The limited information in short speech prompts significantly hinders the performance of fine-grained identity imitation. In this paper, we introduce Mega-TTS 2, a generic zero-shot multispeaker TTS model that is capable of synthesizing speech for unseen speakers with arbitrary-length prompts. Specifically, we 1) design a multi-reference timbre encoder to extract timbre information from multiple reference speeches; 2) and train a prosody language model with arbitrary-length speech prompts; With these designs, our model is suitable for prompts of different lengths, which extends the upper bound of speech quality for zero-shot text-to-speech. Besides arbitrary-length prompts, we introduce arbitrary-source prompts, which leverages the probabilities derived from multiple P-LLM outputs to produce expressive and controlled prosody. Furthermore, we propose a phoneme-level auto-regressive duration model to introduce in-context learning capabilities to duration modeling. Experiments demonstrate that our method could not only synthesize identity-preserving speech with a short prompt of an unseen speaker but also achieve improved performance with longer speech prompts. Audio samples can be found in https://mega-tts.github.io/mega2_demo/.
Mega-TTS: Zero-Shot Text-to-Speech at Scale with Intrinsic Inductive Bias
Jun 06, 2023Scaling text-to-speech to a large and wild dataset has been proven to be highly effective in achieving timbre and speech style generalization, particularly in zero-shot TTS. However, previous works usually encode speech into latent using audio codec and use autoregressive language models or diffusion models to generate it, which ignores the intrinsic nature of speech and may lead to inferior or uncontrollable results. We argue that speech can be decomposed into several attributes (e.g., content, timbre, prosody, and phase) and each of them should be modeled using a module with appropriate inductive biases. From this perspective, we carefully design a novel and large zero-shot TTS system called Mega-TTS, which is trained with large-scale wild data and models different attributes in different ways: 1) Instead of using latent encoded by audio codec as the intermediate feature, we still choose spectrogram as it separates the phase and other attributes very well. Phase can be appropriately constructed by the GAN-based vocoder and does not need to be modeled by the language model. 2) We model the timbre using global vectors since timbre is a global attribute that changes slowly over time. 3) We further use a VQGAN-based acoustic model to generate the spectrogram and a latent code language model to fit the distribution of prosody, since prosody changes quickly over time in a sentence, and language models can capture both local and long-range dependencies. We scale Mega-TTS to multi-domain datasets with 20K hours of speech and evaluate its performance on unseen speakers. Experimental results demonstrate that Mega-TTS surpasses state-of-the-art TTS systems on zero-shot TTS, speech editing, and cross-lingual TTS tasks, with superior naturalness, robustness, and speaker similarity due to the proper inductive bias of each module. Audio samples are available at https://mega-tts.github.io/demo-page.
Ada-TTA: Towards Adaptive High-Quality Text-to-Talking Avatar Synthesis
Jun 06, 2023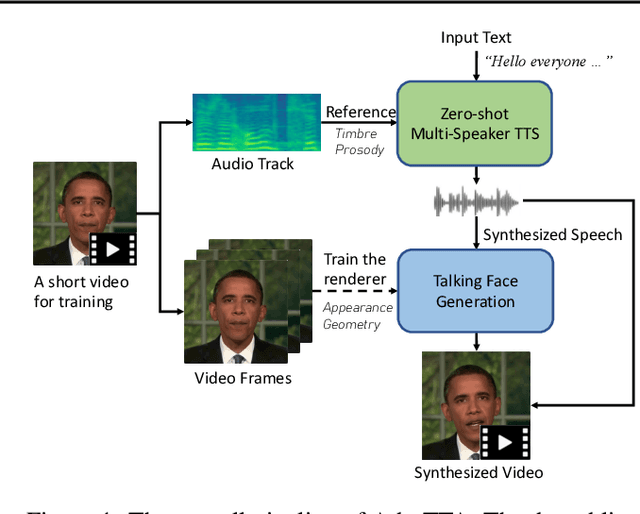



We are interested in a novel task, namely low-resource text-to-talking avatar. Given only a few-minute-long talking person video with the audio track as the training data and arbitrary texts as the driving input, we aim to synthesize high-quality talking portrait videos corresponding to the input text. This task has broad application prospects in the digital human industry but has not been technically achieved yet due to two challenges: (1) It is challenging to mimic the timbre from out-of-domain audio for a traditional multi-speaker Text-to-Speech system. (2) It is hard to render high-fidelity and lip-synchronized talking avatars with limited training data. In this paper, we introduce Adaptive Text-to-Talking Avatar (Ada-TTA), which (1) designs a generic zero-shot multi-speaker TTS model that well disentangles the text content, timbre, and prosody; and (2) embraces recent advances in neural rendering to achieve realistic audio-driven talking face video generation. With these designs, our method overcomes the aforementioned two challenges and achieves to generate identity-preserving speech and realistic talking person video. Experiments demonstrate that our method could synthesize realistic, identity-preserving, and audio-visual synchronized talking avatar videos.
Make-An-Audio 2: Temporal-Enhanced Text-to-Audio Generation
May 29, 2023



Large diffusion models have been successful in text-to-audio (T2A) synthesis tasks, but they often suffer from common issues such as semantic misalignment and poor temporal consistency due to limited natural language understanding and data scarcity. Additionally, 2D spatial structures widely used in T2A works lead to unsatisfactory audio quality when generating variable-length audio samples since they do not adequately prioritize temporal information. To address these challenges, we propose Make-an-Audio 2, a latent diffusion-based T2A method that builds on the success of Make-an-Audio. Our approach includes several techniques to improve semantic alignment and temporal consistency: Firstly, we use pre-trained large language models (LLMs) to parse the text into structured <event & order> pairs for better temporal information capture. We also introduce another structured-text encoder to aid in learning semantic alignment during the diffusion denoising process. To improve the performance of variable length generation and enhance the temporal information extraction, we design a feed-forward Transformer-based diffusion denoiser. Finally, we use LLMs to augment and transform a large amount of audio-label data into audio-text datasets to alleviate the problem of scarcity of temporal data. Extensive experiments show that our method outperforms baseline models in both objective and subjective metrics, and achieves significant gains in temporal information understanding, semantic consistency, and sound quality.
AlignSTS: Speech-to-Singing Conversion via Cross-Modal Alignment
May 24, 2023The speech-to-singing (STS) voice conversion task aims to generate singing samples corresponding to speech recordings while facing a major challenge: the alignment between the target (singing) pitch contour and the source (speech) content is difficult to learn in a text-free situation. This paper proposes AlignSTS, an STS model based on explicit cross-modal alignment, which views speech variance such as pitch and content as different modalities. Inspired by the mechanism of how humans will sing the lyrics to the melody, AlignSTS: 1) adopts a novel rhythm adaptor to predict the target rhythm representation to bridge the modality gap between content and pitch, where the rhythm representation is computed in a simple yet effective way and is quantized into a discrete space; and 2) uses the predicted rhythm representation to re-align the content based on cross-attention and conducts a cross-modal fusion for re-synthesize. Extensive experiments show that AlignSTS achieves superior performance in terms of both objective and subjective metrics. Audio samples are available at https://alignsts.github.io.
AV-TranSpeech: Audio-Visual Robust Speech-to-Speech Translation
May 24, 2023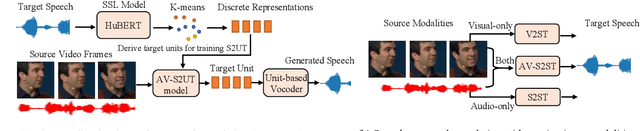
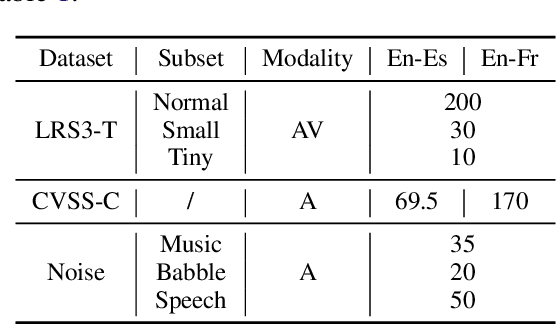
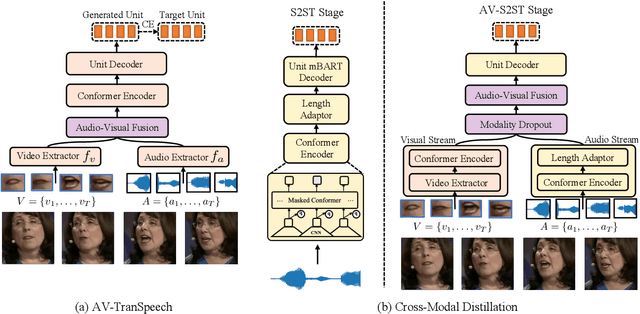
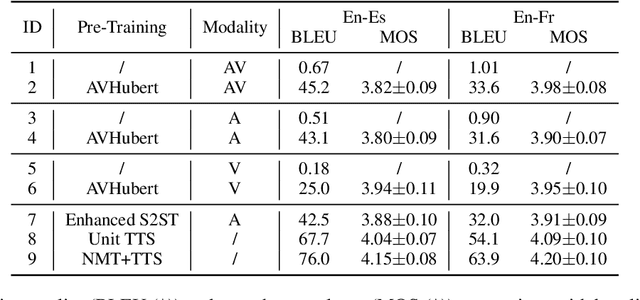
Direct speech-to-speech translation (S2ST) aims to convert speech from one language into another, and has demonstrated significant progress to date. Despite the recent success, current S2ST models still suffer from distinct degradation in noisy environments and fail to translate visual speech (i.e., the movement of lips and teeth). In this work, we present AV-TranSpeech, the first audio-visual speech-to-speech (AV-S2ST) translation model without relying on intermediate text. AV-TranSpeech complements the audio stream with visual information to promote system robustness and opens up a host of practical applications: dictation or dubbing archival films. To mitigate the data scarcity with limited parallel AV-S2ST data, we 1) explore self-supervised pre-training with unlabeled audio-visual data to learn contextual representation, and 2) introduce cross-modal distillation with S2ST models trained on the audio-only corpus to further reduce the requirements of visual data. Experimental results on two language pairs demonstrate that AV-TranSpeech outperforms audio-only models under all settings regardless of the type of noise. With low-resource audio-visual data (10h, 30h), cross-modal distillation yields an improvement of 7.6 BLEU on average compared with baselines. Audio samples are available at https://AV-TranSpeech.github.io