 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniChat: Enhancing Spoken Dialogue Systems with Scalable Synthetic Data for Diverse Scenarios
Jan 02, 2025



With the rapid development of large language models, researchers have created increasingly advanced spoken dialogue systems that can naturally converse with humans. However, these systems still struggle to handle the full complexity of real-world conversations, including audio events, musical contexts, and emotional expressions, mainly because current dialogue datasets are constrained in both scale and scenario diversity. In this paper, we propose leveraging synthetic data to enhance the dialogue models across diverse scenarios. We introduce ShareChatX, the first comprehensive, large-scale dataset for spoken dialogue that spans diverse scenarios. Based on this dataset, we introduce OmniChat, a multi-turn dialogue system with a heterogeneous feature fusion module, designed to optimize feature selection in different dialogue contexts. In addition, we explored critical aspects of training dialogue systems using synthetic data. Through comprehensive experimentation, we determined the ideal balance between synthetic and real data, achieving state-of-the-art results on the real-world dialogue dataset DailyTalk. We also highlight the crucial importance of synthetic data in tackling diverse, complex dialogue scenarios, especially those involving audio and music. For more details, please visit our demo page at \url{https://sharechatx.github.io/}.
EAGER: Two-Stream Generative Recommender with Behavior-Semantic Collaboration
Jun 20, 2024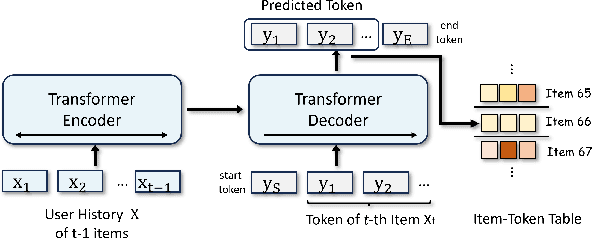

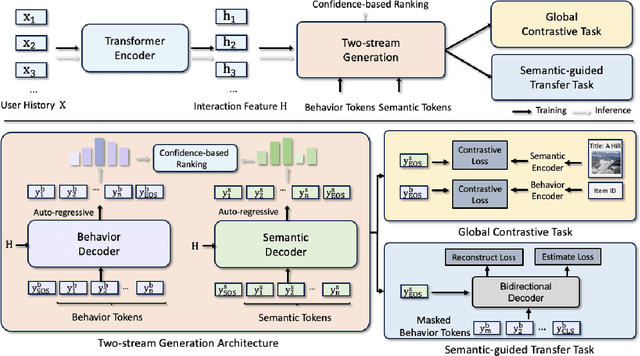

Generative retrieval has recently emerged as a promising approach to sequential recommendation, framing candidate item retrieval as an autoregressive sequence generation problem. However, existing generative methods typically focus solely on either behavioral or semantic aspects of item information, neglecting their complementary nature and thus resulting in limited effectiveness. To address this limitation, we introduce EAGER, a novel generative recommendation framework that seamlessly integrates both behavioral and semantic information. Specifically, we identify three key challenges in combining these two types of information: a unified generative architecture capable of handling two feature types, ensuring sufficient and independent learning for each type, and fostering subtle interactions that enhance collaborative information utilization. To achieve these goals, we propose (1) a two-stream generation architecture leveraging a shared encoder and two separate decoders to decode behavior tokens and semantic tokens with a confidence-based ranking strategy; (2) a global contrastive task with summary tokens to achieve discriminative decoding for each type of information; and (3) a semantic-guided transfer task designed to implicitly promote cross-interactions through reconstruction and estimation objectives. We validate the effectiveness of EAGER on four public benchmarks, demonstrating its superior performance compared to existing methods.
TransFace: Unit-Based Audio-Visual Speech Synthesizer for Talking Head Translation
Dec 23, 2023

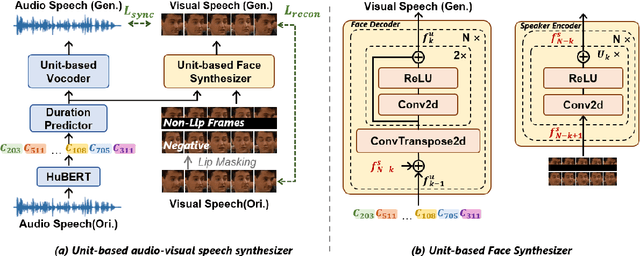
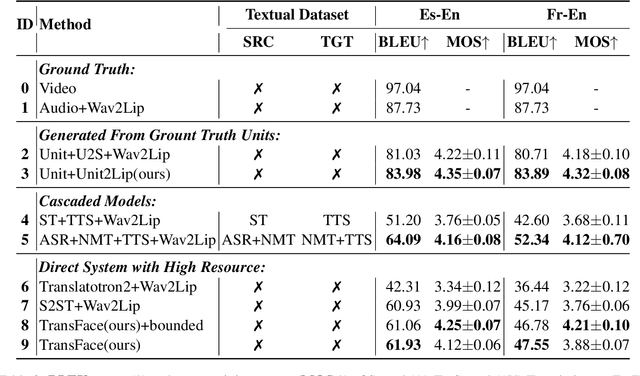
Direct speech-to-speech translation achieves high-quality results through the introduction of discrete units obtained from self-supervised learning. This approach circumvents delays and cascading errors associated with model cascading. However, talking head translation, converting audio-visual speech (i.e., talking head video) from one language into another, still confronts several challenges compared to audio speech: (1) Existing methods invariably rely on cascading, synthesizing via both audio and text, resulting in delays and cascading errors. (2) Talking head translation has a limited set of reference frames. If the generated translation exceeds the length of the original speech, the video sequence needs to be supplemented by repeating frames, leading to jarring video transitions. In this work, we propose a model for talking head translation, \textbf{TransFace}, which can directly translate audio-visual speech into audio-visual speech in other languages. It consists of a speech-to-unit translation model to convert audio speech into discrete units and a unit-based audio-visual speech synthesizer, Unit2Lip, to re-synthesize synchronized audio-visual speech from discrete units in parallel. Furthermore, we introduce a Bounded Duration Predictor, ensuring isometric talking head translation and preventing duplicate reference frames. Experiments demonstrate that our proposed Unit2Lip model significantly improves synchronization (1.601 and 0.982 on LSE-C for the original and generated audio speech, respectively) and boosts inference speed by a factor of 4.35 on LRS2. Additionally, TransFace achieves impressive BLEU scores of 61.93 and 47.55 for Es-En and Fr-En on LRS3-T and 100% isochronous translations.
3DRP-Net: 3D Relative Position-aware Network for 3D Visual Grounding
Jul 25, 2023



3D visual grounding aims to localize the target object in a 3D point cloud by a free-form language description. Typically, the sentences describing the target object tend to provide information about its relative relation between other objects and its position within the whole scene. In this work, we propose a relation-aware one-stage framework, named 3D Relative Position-aware Network (3DRP-Net), which can effectively capture the relative spatial relationships between objects and enhance object attributes. Specifically, 1) we propose a 3D Relative Position Multi-head Attention (3DRP-MA) module to analyze relative relations from different directions in the context of object pairs, which helps the model to focus on the specific object relations mentioned in the sentence. 2) We designed a soft-labeling strategy to alleviate the spatial ambiguity caused by redundant points, which further stabilizes and enhances the learning process through a constant and discriminative distribution. Extensive experiments conducted on three benchmarks (i.e., ScanRefer and Nr3D/Sr3D) demonstrate that our method outperforms all the state-of-the-art methods in general. The source code will be released on GitHub.
Distilling Coarse-to-Fine Semantic Matching Knowledge for Weakly Supervised 3D Visual Grounding
Jul 18, 2023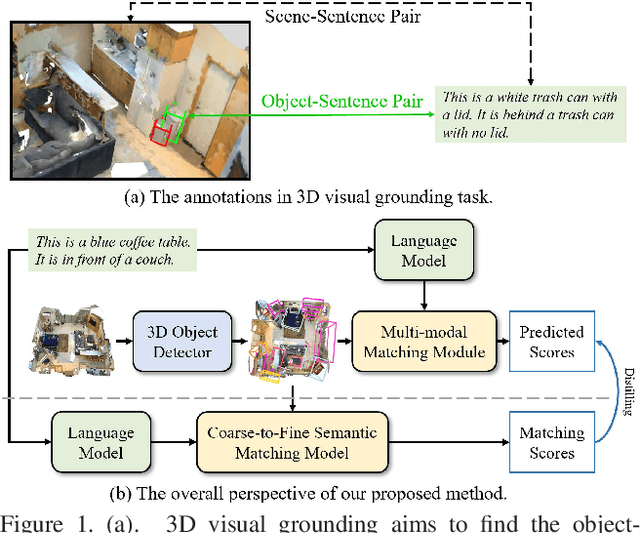
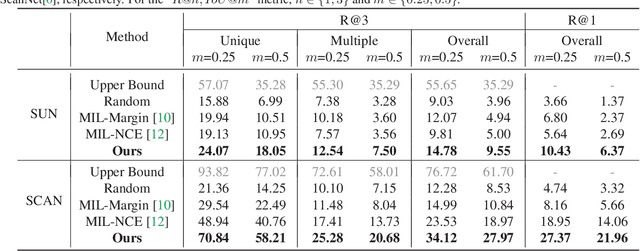
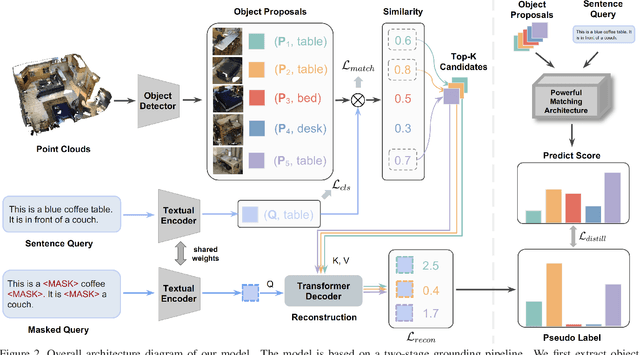
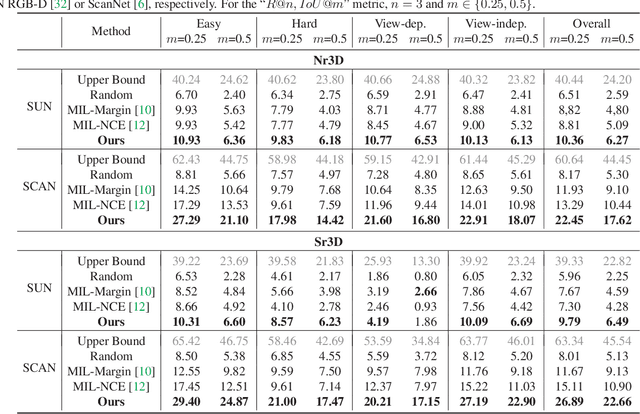
3D visual grounding involves finding a target object in a 3D scene that corresponds to a given sentence query. Although many approaches have been proposed and achieved impressive performance, they all require dense object-sentence pair annotations in 3D point clouds, which are both time-consuming and expensive. To address the problem that fine-grained annotated data is difficult to obtain, we propose to leverage weakly supervised annotations to learn the 3D visual grounding model, i.e., only coarse scene-sentence correspondences are used to learn object-sentence links. To accomplish this, we design a novel semantic matching model that analyzes the semantic similarity between object proposals and sentences in a coarse-to-fine manner. Specifically, we first extract object proposals and coarsely select the top-K candidates based on feature and class similarity matrices. Next, we reconstruct the masked keywords of the sentence using each candidate one by one, and the reconstructed accuracy finely reflects the semantic similarity of each candidate to the query. Additionally, we distill the coarse-to-fine semantic matching knowledge into a typical two-stage 3D visual grounding model, which reduces inference costs and improves performance by taking full advantage of the well-studied structure of the existing architectures. We conduct extensive experiments on ScanRefer, Nr3D, and Sr3D, which demonstrate the effectiveness of our proposed method.
OpenSR: Open-Modality Speech Recognition via Maintaining Multi-Modality Alignment
Jun 10, 2023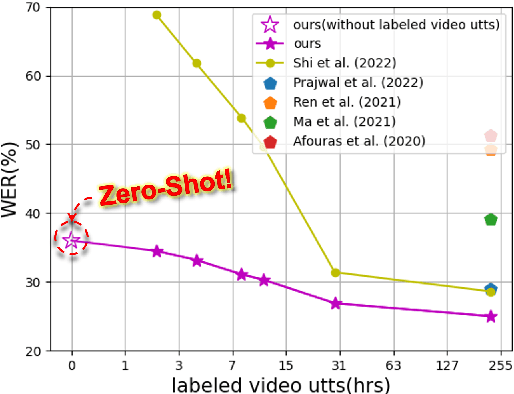
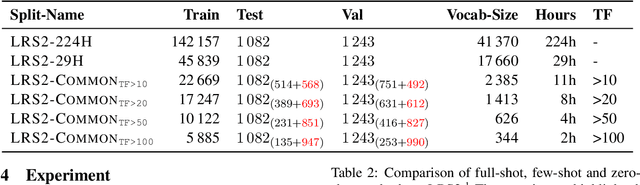
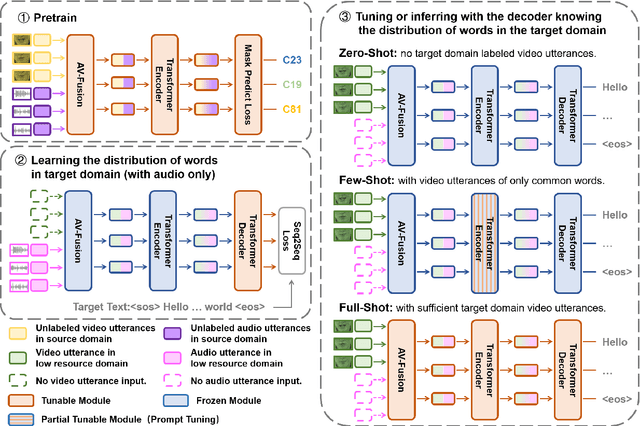
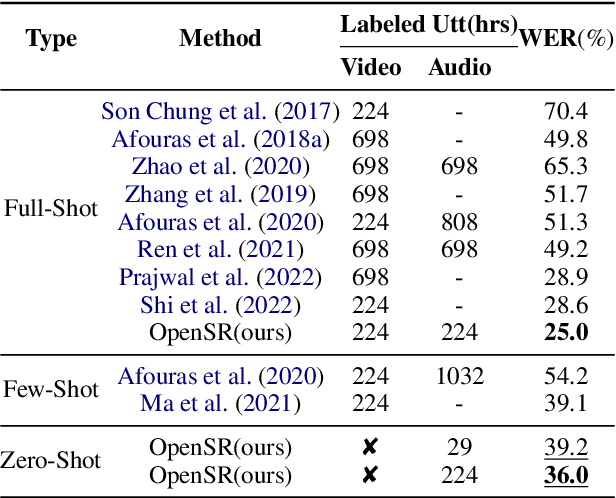
Speech Recognition builds a bridge between the multimedia streaming (audio-only, visual-only or audio-visual) and the corresponding text transcription. However, when training the specific model of new domain, it often gets stuck in the lack of new-domain utterances, especially the labeled visual utterances. To break through this restriction, we attempt to achieve zero-shot modality transfer by maintaining the multi-modality alignment in phoneme space learned with unlabeled multimedia utterances in the high resource domain during the pre-training \cite{shi2022learning}, and propose a training system Open-modality Speech Recognition (\textbf{OpenSR}) that enables the models trained on a single modality (e.g., audio-only) applicable to more modalities (e.g., visual-only and audio-visual). Furthermore, we employ a cluster-based prompt tuning strategy to handle the domain shift for the scenarios with only common words in the new domain utterances. We demonstrate that OpenSR enables modality transfer from one to any in three different settings (zero-, few- and full-shot), and achieves highly competitive zero-shot performance compared to the existing few-shot and full-shot lip-reading methods. To the best of our knowledge, OpenSR achieves the state-of-the-art performance of word error rate in LRS2 on audio-visual speech recognition and lip-reading with 2.7\% and 25.0\%, respectively. The code and demo are available at https://github.com/Exgc/OpenSR.
AV-TranSpeech: Audio-Visual Robust Speech-to-Speech Translation
May 24, 2023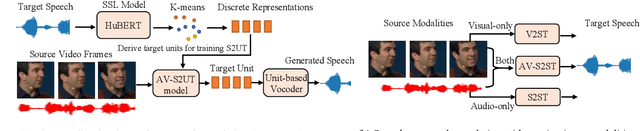
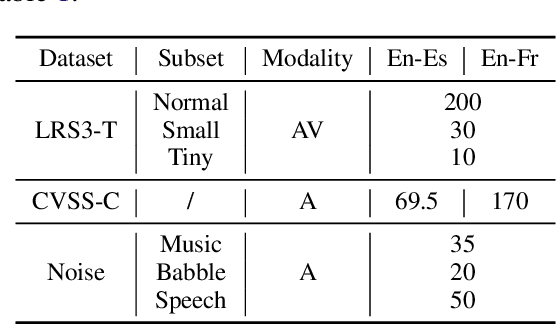
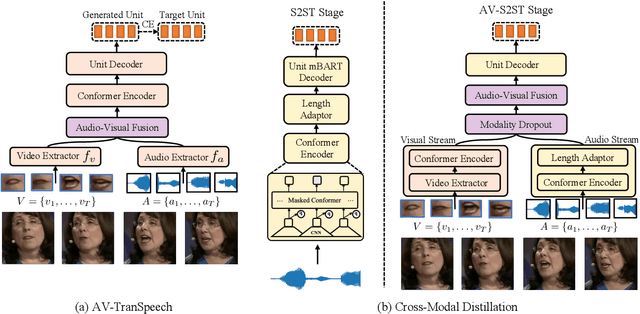
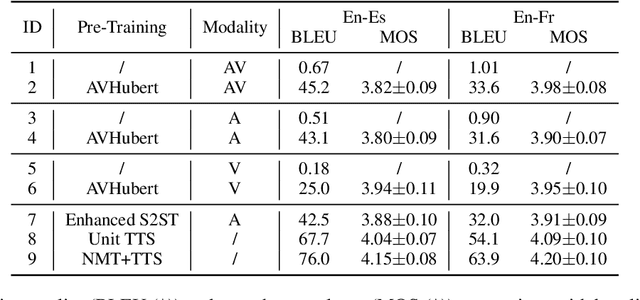
Direct speech-to-speech translation (S2ST) aims to convert speech from one language into another, and has demonstrated significant progress to date. Despite the recent success, current S2ST models still suffer from distinct degradation in noisy environments and fail to translate visual speech (i.e., the movement of lips and teeth). In this work, we present AV-TranSpeech, the first audio-visual speech-to-speech (AV-S2ST) translation model without relying on intermediate text. AV-TranSpeech complements the audio stream with visual information to promote system robustness and opens up a host of practical applications: dictation or dubbing archival films. To mitigate the data scarcity with limited parallel AV-S2ST data, we 1) explore self-supervised pre-training with unlabeled audio-visual data to learn contextual representation, and 2) introduce cross-modal distillation with S2ST models trained on the audio-only corpus to further reduce the requirements of visual data. Experimental results on two language pairs demonstrate that AV-TranSpeech outperforms audio-only models under all settings regardless of the type of noise. With low-resource audio-visual data (10h, 30h), cross-modal distillation yields an improvement of 7.6 BLEU on average compared with baselines. Audio samples are available at https://AV-TranSpeech.github.io
Connecting Multi-modal Contrastive Representations
May 22, 2023



Multi-modal Contrastive Representation (MCR) learning aims to encode different modalities into a semantically aligned shared space. This paradigm shows remarkable generalization ability on numerous downstream tasks across various modalities. However, the reliance on massive high-quality data pairs limits its further development on more modalities. This paper proposes a novel training-efficient method for learning MCR without paired data called Connecting Multi-modal Contrastive Representations (C-MCR). Specifically, given two existing MCRs pre-trained on (A, B) and (B, C) modality pairs, we project them to a new space and use the data from the overlapping modality B to aligning the two MCRs in the new space. Meanwhile, since the modality pairs (A, B) and (B, C) are already aligned within each MCR, the connection learned by overlapping modality can also be transferred to non-overlapping modality pair (A, C). To unleash the potential of C-MCR, we further introduce a semantic-enhanced inter- and intra-MCR connection method. We first enhance the semantic consistency and completion of embeddings across different modalities for more robust alignment. Then we utilize the inter-MCR alignment to establish the connection, and employ the intra-MCR alignment to better maintain the connection for inputs from non-overlapping modalities. We take the field of audio-visual contrastive learning as an example to demonstrate the effectiveness of C-MCR. We connect pre-trained CLIP and CLAP models via texts to derive audio-visual contrastive representations. Remarkably, without using any paired audio-visual data and further tuning, C-MCR achieves state-of-the-art performance on six datasets across three audio-visual downstream tasks.
MixSpeech: Cross-Modality Self-Learning with Audio-Visual Stream Mixup for Visual Speech Translation and Recognition
Mar 09, 2023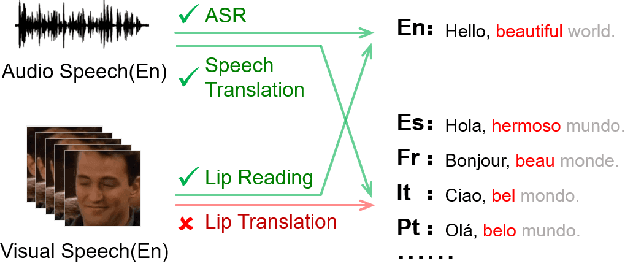
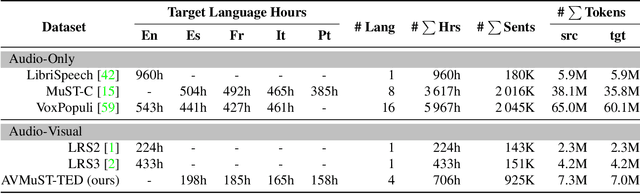
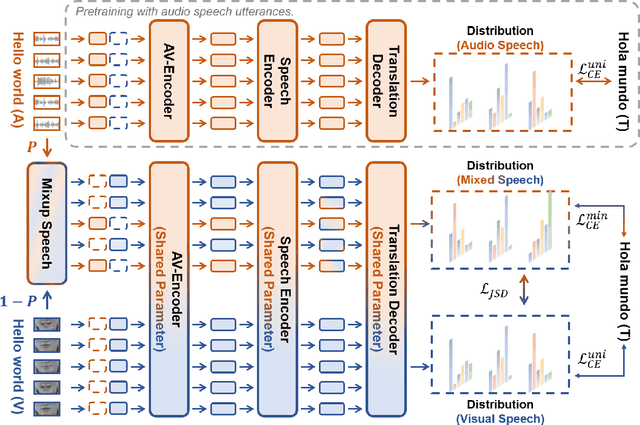
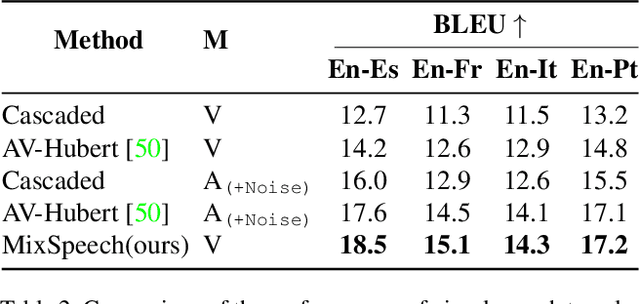
Multi-media communications facilitate global interaction among people. However, despite researchers exploring cross-lingual translation techniques such as machine translation and audio speech translation to overcome language barriers, there is still a shortage of cross-lingual studies on visual speech. This lack of research is mainly due to the absence of datasets containing visual speech and translated text pairs. In this paper, we present \textbf{AVMuST-TED}, the first dataset for \textbf{A}udio-\textbf{V}isual \textbf{Mu}ltilingual \textbf{S}peech \textbf{T}ranslation, derived from \textbf{TED} talks. Nonetheless, visual speech is not as distinguishable as audio speech, making it difficult to develop a mapping from source speech phonemes to the target language text. To address this issue, we propose MixSpeech, a cross-modality self-learning framework that utilizes audio speech to regularize the training of visual speech tasks. To further minimize the cross-modality gap and its impact on knowledge transfer, we suggest adopting mixed speech, which is created by interpolating audio and visual streams, along with a curriculum learning strategy to adjust the mixing ratio as needed. MixSpeech enhances speech translation in noisy environments, improving BLEU scores for four languages on AVMuST-TED by +1.4 to +4.2. Moreover, it achieves state-of-the-art performance in lip reading on CMLR (11.1\%), LRS2 (25.5\%), and LRS3 (28.0\%).
Motion Planning Transformers: One Model to Plan Them All
Jun 05, 2021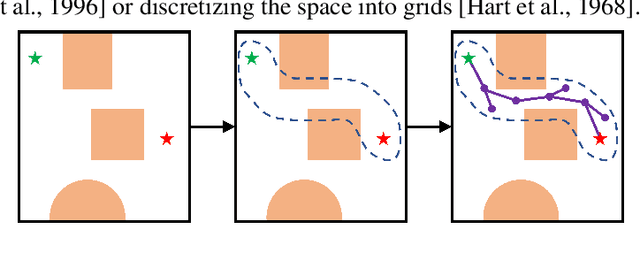
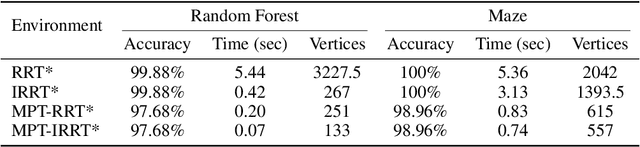
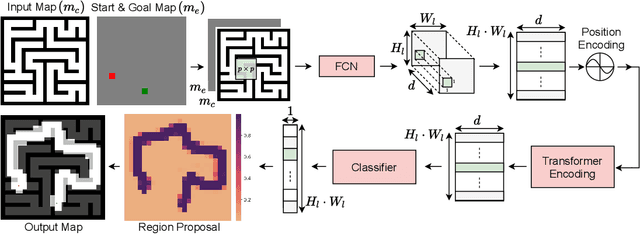
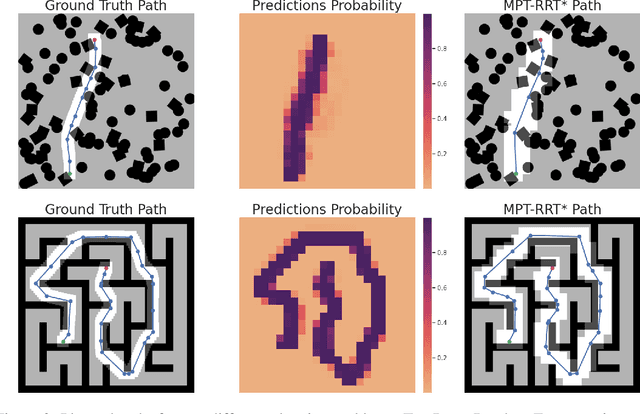
Transformers have become the powerhouse of natural language processing and recently found use in computer vision tasks. Their effective use of attention can be used in other contexts as well, and in this paper, we propose a transformer-based approach for efficiently solving the complex motion planning problems. Traditional neural network-based motion planning uses convolutional networks to encode the planning space, but these methods are limited to fixed map sizes, which is often not realistic in the real-world. Our approach first identifies regions on the map using transformers to provide attention to map areas likely to include the best path, and then applies local planners to generate the final collision-free path. We validate our method on a variety of randomly generated environments with different map sizes, demonstrating reduction in planning complexity and achieving comparable accuracy to traditional planners.