 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEAGER: Two-Stream Generative Recommender with Behavior-Semantic Collaboration
Jun 20, 2024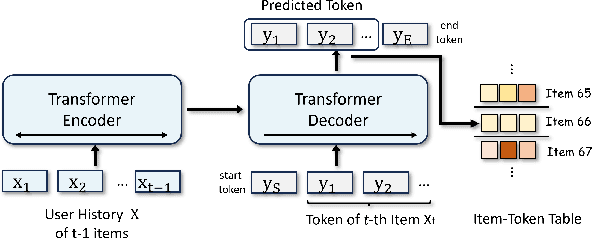

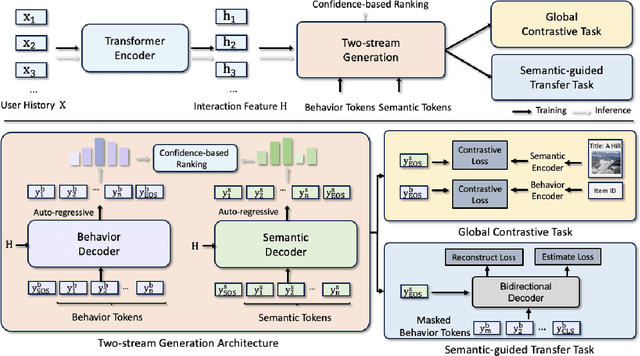

Generative retrieval has recently emerged as a promising approach to sequential recommendation, framing candidate item retrieval as an autoregressive sequence generation problem. However, existing generative methods typically focus solely on either behavioral or semantic aspects of item information, neglecting their complementary nature and thus resulting in limited effectiveness. To address this limitation, we introduce EAGER, a novel generative recommendation framework that seamlessly integrates both behavioral and semantic information. Specifically, we identify three key challenges in combining these two types of information: a unified generative architecture capable of handling two feature types, ensuring sufficient and independent learning for each type, and fostering subtle interactions that enhance collaborative information utilization. To achieve these goals, we propose (1) a two-stream generation architecture leveraging a shared encoder and two separate decoders to decode behavior tokens and semantic tokens with a confidence-based ranking strategy; (2) a global contrastive task with summary tokens to achieve discriminative decoding for each type of information; and (3) a semantic-guided transfer task designed to implicitly promote cross-interactions through reconstruction and estimation objectives. We validate the effectiveness of EAGER on four public benchmarks, demonstrating its superior performance compared to existing methods.
DisCover: Disentangled Music Representation Learning for Cover Song Identification
Jul 19, 2023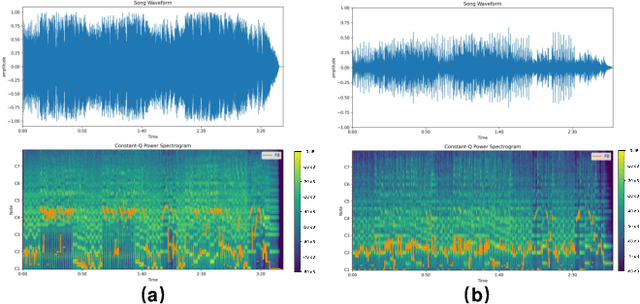

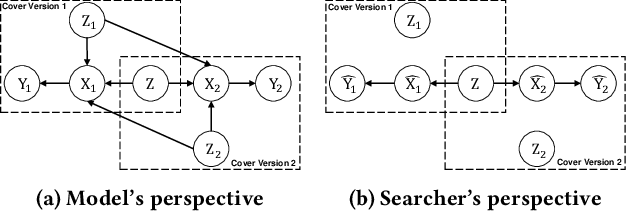
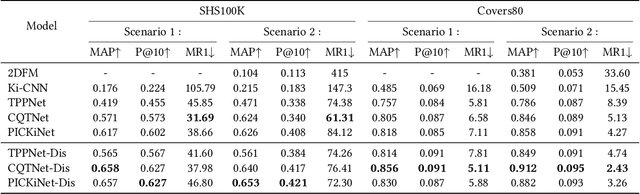
In the field of music information retrieval (MIR), cover song identification (CSI) is a challenging task that aims to identify cover versions of a query song from a massive collection. Existing works still suffer from high intra-song variances and inter-song correlations, due to the entangled nature of version-specific and version-invariant factors in their modeling. In this work, we set the goal of disentangling version-specific and version-invariant factors, which could make it easier for the model to learn invariant music representations for unseen query songs. We analyze the CSI task in a disentanglement view with the causal graph technique, and identify the intra-version and inter-version effects biasing the invariant learning. To block these effects, we propose the disentangled music representation learning framework (DisCover) for CSI. DisCover consists of two critical components: (1) Knowledge-guided Disentanglement Module (KDM) and (2) Gradient-based Adversarial Disentanglement Module (GADM), which block intra-version and inter-version biased effects, respectively. KDM minimizes the mutual information between the learned representations and version-variant factors that are identified with prior domain knowledge. GADM identifies version-variant factors by simulating the representation transitions between intra-song versions, and exploits adversarial distillation for effect blocking. Extensive comparisons with best-performing methods and in-depth analysis demonstrate the effectiveness of DisCover and the and necessity of disentanglement for CSI.
Why Do We Click: Visual Impression-aware News Recommendation
Sep 26, 2021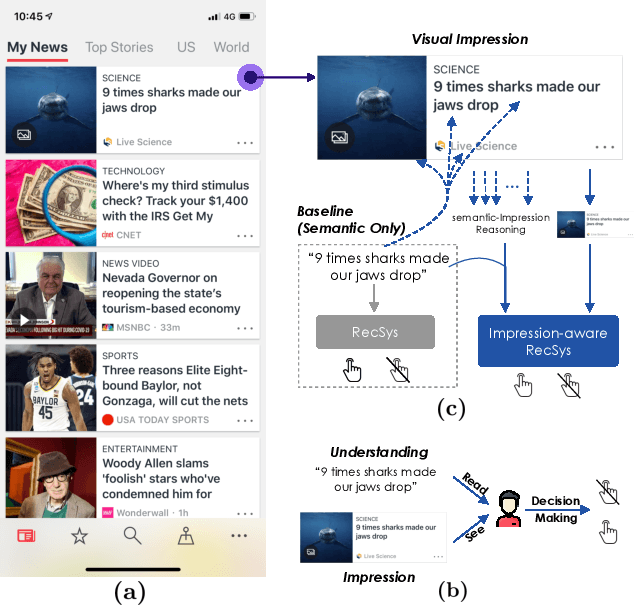
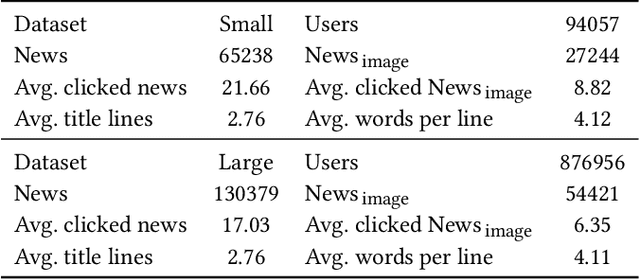
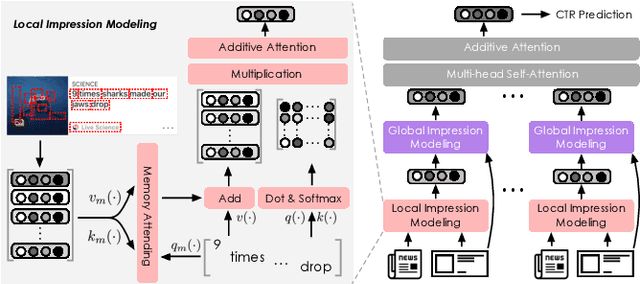
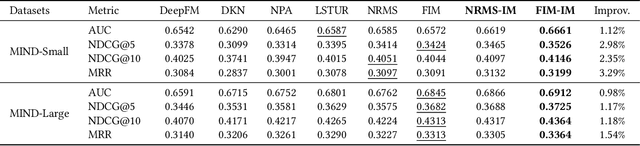
There is a soaring interest in the news recommendation research scenario due to the information overload. To accurately capture users' interests, we propose to model multi-modal features, in addition to the news titles that are widely used in existing works, for news recommendation. Besides, existing research pays little attention to the click decision-making process in designing multi-modal modeling modules. In this work, inspired by the fact that users make their click decisions mostly based on the visual impression they perceive when browsing news, we propose to capture such visual impression information with visual-semantic modeling for news recommendation. Specifically, we devise the local impression modeling module to simultaneously attend to decomposed details in the impression when understanding the semantic meaning of news title, which could explicitly get close to the process of users reading news. In addition, we inspect the impression from a global view and take structural information, such as the arrangement of different fields and spatial position of different words on the impression, into the modeling of multiple modalities. To accommodate the research of visual impression-aware news recommendation, we extend the text-dominated news recommendation dataset MIND by adding snapshot impression images and will release it to nourish the research field. Extensive comparisons with the state-of-the-art news recommenders along with the in-depth analyses demonstrate the effectiveness of the proposed method and the promising capability of modeling visual impressions for the content-based recommenders.