 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Reasoning Recommendation via LLMs
Oct 23, 2025Despite their remarkable reasoning capabilities across diverse domains, large language models (LLMs) face fundamental challenges in natively functioning as generative reasoning recommendation models (GRRMs), where the intrinsic modeling gap between textual semantics and collaborative filtering signals, combined with the sparsity and stochasticity of user feedback, presents significant obstacles. This work explores how to build GRRMs by adapting pre-trained LLMs, which achieves a unified understanding-reasoning-prediction manner for recommendation tasks. We propose GREAM, an end-to-end framework that integrates three components: (i) Collaborative-Semantic Alignment, which fuses heterogeneous textual evidence to construct semantically consistent, discrete item indices and auxiliary alignment tasks that ground linguistic representations in interaction semantics; (ii) Reasoning Curriculum Activation, which builds a synthetic dataset with explicit Chain-of-Thought supervision and a curriculum that progresses through behavioral evidence extraction, latent preference modeling, intent inference, recommendation formulation, and denoised sequence rewriting; and (iii) Sparse-Regularized Group Policy Optimization (SRPO), which stabilizes post-training via Residual-Sensitive Verifiable Reward and Bonus-Calibrated Group Advantage Estimation, enabling end-to-end optimization under verifiable signals despite sparse successes. GREAM natively supports two complementary inference modes: Direct Sequence Recommendation for high-throughput, low-latency deployment, and Sequential Reasoning Recommendation that first emits an interpretable reasoning chain for causal transparency. Experiments on three datasets demonstrate consistent gains over strong baselines, providing a practical path toward verifiable-RL-driven LLM recommenders.
DSI-Bench: A Benchmark for Dynamic Spatial Intelligence
Oct 21, 2025Reasoning about dynamic spatial relationships is essential, as both observers and objects often move simultaneously. Although vision-language models (VLMs) and visual expertise models excel in 2D tasks and static scenarios, their ability to fully understand dynamic 3D scenarios remains limited. We introduce Dynamic Spatial Intelligence and propose DSI-Bench, a benchmark with nearly 1,000 dynamic videos and over 1,700 manually annotated questions covering nine decoupled motion patterns of observers and objects. Spatially and temporally symmetric designs reduce biases and enable systematic evaluation of models' reasoning about self-motion and object motion. Our evaluation of 14 VLMs and expert models reveals key limitations: models often conflate observer and object motion, exhibit semantic biases, and fail to accurately infer relative relationships in dynamic scenarios. Our DSI-Bench provides valuable findings and insights about the future development of general and expertise models with dynamic spatial intelligence.
GenSpace: Benchmarking Spatially-Aware Image Generation
May 30, 2025

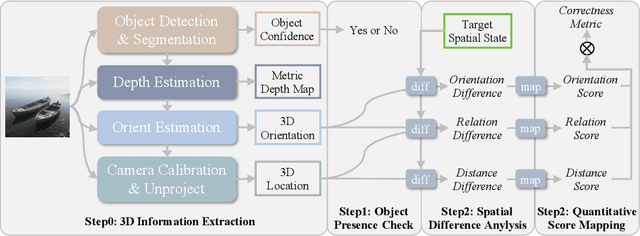
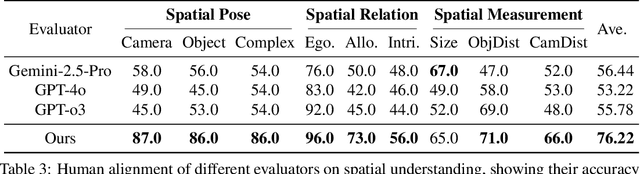
Humans can intuitively compose and arrange scenes in the 3D space for photography. However, can advanced AI image generators plan scenes with similar 3D spatial awareness when creating images from text or image prompts? We present GenSpace, a novel benchmark and evaluation pipeline to comprehensively assess the spatial awareness of current image generation models. Furthermore, standard evaluations using general Vision-Language Models (VLMs) frequently fail to capture the detailed spatial errors. To handle this challenge, we propose a specialized evaluation pipeline and metric, which reconstructs 3D scene geometry using multiple visual foundation models and provides a more accurate and human-aligned metric of spatial faithfulness. Our findings show that while AI models create visually appealing images and can follow general instructions, they struggle with specific 3D details like object placement, relationships, and measurements. We summarize three core limitations in the spatial perception of current state-of-the-art image generation models: 1) Object Perspective Understanding, 2) Egocentric-Allocentric Transformation and 3) Metric Measurement Adherence, highlighting possible directions for improving spatial intelligence in image generation.
Depth Anything with Any Prior
May 15, 2025This work presents Prior Depth Anything, a framework that combines incomplete but precise metric information in depth measurement with relative but complete geometric structures in depth prediction, generating accurate, dense, and detailed metric depth maps for any scene. To this end, we design a coarse-to-fine pipeline to progressively integrate the two complementary depth sources. First, we introduce pixel-level metric alignment and distance-aware weighting to pre-fill diverse metric priors by explicitly using depth prediction. It effectively narrows the domain gap between prior patterns, enhancing generalization across varying scenarios. Second, we develop a conditioned monocular depth estimation (MDE) model to refine the inherent noise of depth priors. By conditioning on the normalized pre-filled prior and prediction, the model further implicitly merges the two complementary depth sources. Our model showcases impressive zero-shot generalization across depth completion, super-resolution, and inpainting over 7 real-world datasets, matching or even surpassing previous task-specific methods. More importantly, it performs well on challenging, unseen mixed priors and enables test-time improvements by switching prediction models, providing a flexible accuracy-efficiency trade-off while evolving with advancements in MDE models.
Orient Anything: Learning Robust Object Orientation Estimation from Rendering 3D Models
Dec 24, 2024Orientation is a key attribute of objects, crucial for understanding their spatial pose and arrangement in images. However, practical solutions for accurate orientation estimation from a single image remain underexplored. In this work, we introduce Orient Anything, the first expert and foundational model designed to estimate object orientation in a single- and free-view image. Due to the scarcity of labeled data, we propose extracting knowledge from the 3D world. By developing a pipeline to annotate the front face of 3D objects and render images from random views, we collect 2M images with precise orientation annotations. To fully leverage the dataset, we design a robust training objective that models the 3D orientation as probability distributions of three angles and predicts the object orientation by fitting these distributions. Besides, we employ several strategies to improve synthetic-to-real transfer. Our model achieves state-of-the-art orientation estimation accuracy in both rendered and real images and exhibits impressive zero-shot ability in various scenarios. More importantly, our model enhances many applications, such as comprehension and generation of complex spatial concepts and 3D object pose adjustment.
OmniSep: Unified Omni-Modality Sound Separation with Query-Mixup
Oct 28, 2024



The scaling up has brought tremendous success in the fields of vision and language in recent years. When it comes to audio, however, researchers encounter a major challenge in scaling up the training data, as most natural audio contains diverse interfering signals. To address this limitation, we introduce Omni-modal Sound Separation (OmniSep), a novel framework capable of isolating clean soundtracks based on omni-modal queries, encompassing both single-modal and multi-modal composed queries. Specifically, we introduce the Query-Mixup strategy, which blends query features from different modalities during training. This enables OmniSep to optimize multiple modalities concurrently, effectively bringing all modalities under a unified framework for sound separation. We further enhance this flexibility by allowing queries to influence sound separation positively or negatively, facilitating the retention or removal of specific sounds as desired. Finally, OmniSep employs a retrieval-augmented approach known as Query-Aug, which enables open-vocabulary sound separation. Experimental evaluations on MUSIC, VGGSOUND-CLEAN+, and MUSIC-CLEAN+ datasets demonstrate effectiveness of OmniSep, achieving state-of-the-art performance in text-, image-, and audio-queried sound separation tasks. For samples and further information, please visit the demo page at \url{https://omnisep.github.io/}.
MuVi: Video-to-Music Generation with Semantic Alignment and Rhythmic Synchronization
Oct 16, 2024



Generating music that aligns with the visual content of a video has been a challenging task, as it requires a deep understanding of visual semantics and involves generating music whose melody, rhythm, and dynamics harmonize with the visual narratives. This paper presents MuVi, a novel framework that effectively addresses these challenges to enhance the cohesion and immersive experience of audio-visual content. MuVi analyzes video content through a specially designed visual adaptor to extract contextually and temporally relevant features. These features are used to generate music that not only matches the video's mood and theme but also its rhythm and pacing. We also introduce a contrastive music-visual pre-training scheme to ensure synchronization, based on the periodicity nature of music phrases. In addition, we demonstrate that our flow-matching-based music generator has in-context learning ability, allowing us to control the style and genre of the generated music. Experimental results show that MuVi demonstrates superior performance in both audio quality and temporal synchronization. The generated music video samples are available at https://muvi-v2m.github.io.
WavTokenizer: an Efficient Acoustic Discrete Codec Tokenizer for Audio Language Modeling
Aug 29, 2024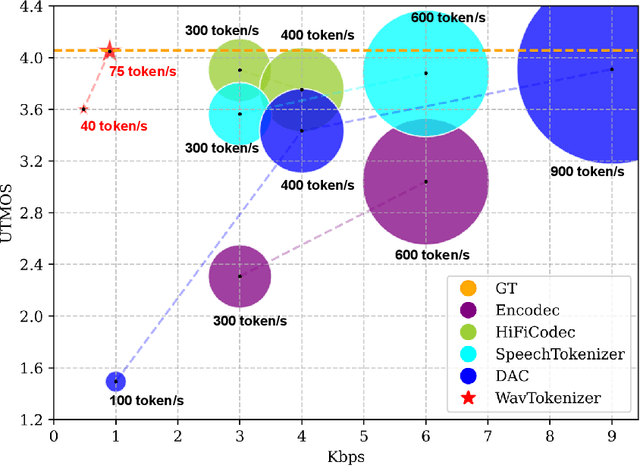
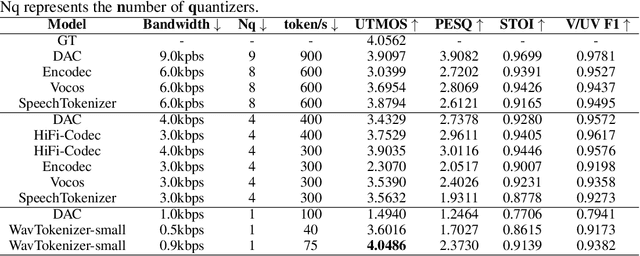
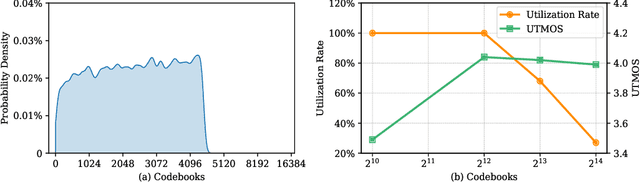
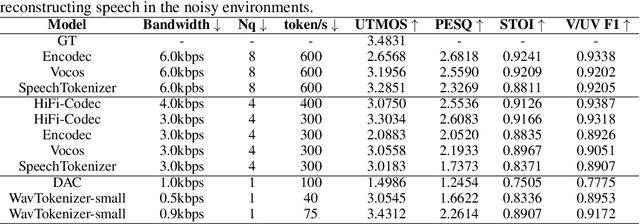
Language models have been effectively applied to modeling natural signals, such as images, video, speech, and audio. A crucial component of these models is the codec tokenizer, which compresses high-dimensional natural signals into lower-dimensional discrete tokens. In this paper, we introduce WavTokenizer, which offers several advantages over previous SOTA acoustic codec models in the audio domain: 1)extreme compression. By compressing the layers of quantizers and the temporal dimension of the discrete codec, one-second audio of 24kHz sampling rate requires only a single quantizer with 40 or 75 tokens. 2)improved subjective quality. Despite the reduced number of tokens, WavTokenizer achieves state-of-the-art reconstruction quality with outstanding UTMOS scores and inherently contains richer semantic information. Specifically, we achieve these results by designing a broader VQ space, extended contextual windows, and improved attention networks, as well as introducing a powerful multi-scale discriminator and an inverse Fourier transform structure. We conducted extensive reconstruction experiments in the domains of speech, audio, and music. WavTokenizer exhibited strong performance across various objective and subjective metrics compared to state-of-the-art models. We also tested semantic information, VQ utilization, and adaptability to generative models. Comprehensive ablation studies confirm the necessity of each module in WavTokenizer. The related code, demos, and pre-trained models are available at https://github.com/jishengpeng/WavTokenizer.
RIMformer: An End-to-End Transformer for FMCW Radar Interference Mitigation
Jul 16, 2024

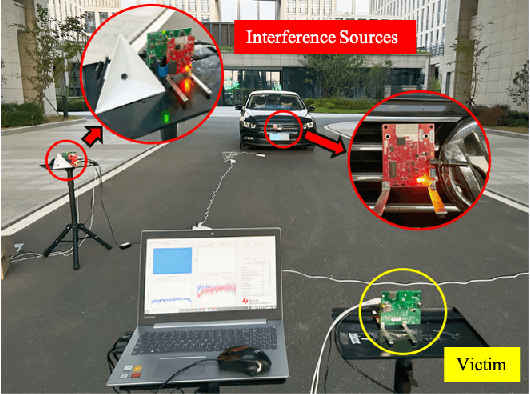

Frequency-modulated continuous-wave (FMCW) radar plays a pivotal role in the field of remote sensing. The increasing degree of FMCW radar deployment has increased the mutual interference, which weakens the detection capabilities of radars and threatens reliability and safety of systems. In this paper, a novel FMCW radar interference mitigation (RIM) method, termed as RIMformer, is proposed by using an end-to-end Transformer-based structure. In the RIMformer, a dual multi-head self-attention mechanism is proposed to capture the correlations among the distinct distance elements of intermediate frequency (IF) signals. Additionally, an improved convolutional block is integrated to harness the power of convolution for extracting local features. The architecture is designed to process time-domain IF signals in an end-to-end manner, thereby avoiding the need for additional manual data processing steps. The improved decoder structure ensures the parallelization of the network to increase its computational efficiency. Simulation and measurement experiments are carried out to validate the accuracy and effectiveness of the proposed method. The results show that the proposed RIMformer can effectively mitigate interference and restore the target signals.
OmniBind: Large-scale Omni Multimodal Representation via Binding Spaces
Jul 16, 2024Recently, human-computer interaction with various modalities has shown promising applications, like GPT-4o and Gemini. Given the foundational role of multimodal joint representation in understanding and generation pipelines, high-quality omni joint representations would be a step toward co-processing more diverse multimodal information. In this work, we present OmniBind, large-scale multimodal joint representation models ranging in scale from 7 billion to 30 billion parameters, which support 3D, audio, image, and language inputs. Due to the scarcity of data pairs across all modalities, instead of training large models from scratch, we propose remapping and binding the spaces of various pre-trained specialist models together. This approach enables "scaling up" by indirectly increasing the model parameters and the amount of seen data. To effectively integrate various spaces, we dynamically assign weights to different spaces by learning routers with two objectives: cross-modal overall alignment and language representation decoupling. Notably, since binding and routing spaces both only require lightweight networks, OmniBind is extremely training-efficient. Learning the largest 30B model requires merely unpaired unimodal data and approximately 3 days on a single 8-4090 node. Extensive experiments demonstrate the versatility and superiority of OmniBind as an omni representation model, highlighting its great potential for diverse applications, such as any-query and composable multimodal understanding.