 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGGAvatar: Reconstructing Garment-Separated 3D Gaussian Splatting Avatars from Monocular Video
Nov 15, 2024



Avatar modelling has broad applications in human animation and virtual try-ons. Recent advancements in this field have focused on high-quality and comprehensive human reconstruction but often overlook the separation of clothing from the body. To bridge this gap, this paper introduces GGAvatar (Garment-separated 3D Gaussian Splatting Avatar), which relies on monocular videos. Through advanced parameterized templates and unique phased training, this model effectively achieves decoupled, editable, and realistic reconstruction of clothed humans. Comparative evaluations with other costly models confirm GGAvatar's superior quality and efficiency in modelling both clothed humans and separable garments. The paper also showcases applications in clothing editing, as illustrated in Figure 1, highlighting the model's benefits and the advantages of effective disentanglement. The code is available at https://github.com/J-X-Chen/GGAvatar/.
GUI Agents with Foundation Models: A Comprehensive Survey
Nov 07, 2024

Recent advances in foundation models, particularly Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs), facilitate intelligent agents being capable of performing complex tasks. By leveraging the ability of (M)LLMs to process and interpret Graphical User Interfaces (GUIs), these agents can autonomously execute user instructions by simulating human-like interactions such as clicking and typing. This survey consolidates recent research on (M)LLM-based GUI agents, highlighting key innovations in data, frameworks, and applications. We begin by discussing representative datasets and benchmarks. Next, we summarize a unified framework that captures the essential components used in prior research, accompanied by a taxonomy. Additionally, we explore commercial applications of (M)LLM-based GUI agents. Drawing from existing work, we identify several key challenges and propose future research directions. We hope this paper will inspire further developments in the field of (M)LLM-based GUI agents.
SPA-Bench: A Comprehensive Benchmark for SmartPhone Agent Evaluation
Oct 19, 2024



Smartphone agents are increasingly important for helping users control devices efficiently, with (Multimodal) Large Language Model (MLLM)-based approaches emerging as key contenders. Fairly comparing these agents is essential but challenging, requiring a varied task scope, the integration of agents with different implementations, and a generalisable evaluation pipeline to assess their strengths and weaknesses. In this paper, we present SPA-Bench, a comprehensive SmartPhone Agent Benchmark designed to evaluate (M)LLM-based agents in an interactive environment that simulates real-world conditions. SPA-Bench offers three key contributions: (1) A diverse set of tasks covering system and third-party apps in both English and Chinese, focusing on features commonly used in daily routines; (2) A plug-and-play framework enabling real-time agent interaction with Android devices, integrating over ten agents with the flexibility to add more; (3) A novel evaluation pipeline that automatically assesses agent performance across multiple dimensions, encompassing seven metrics related to task completion and resource consumption. Our extensive experiments across tasks and agents reveal challenges like interpreting mobile user interfaces, action grounding, memory retention, and execution costs. We propose future research directions to ease these difficulties, moving closer to real-world smartphone agent applications.
RIMformer: An End-to-End Transformer for FMCW Radar Interference Mitigation
Jul 16, 2024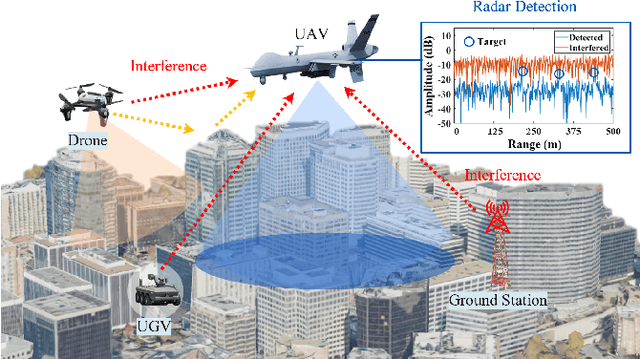

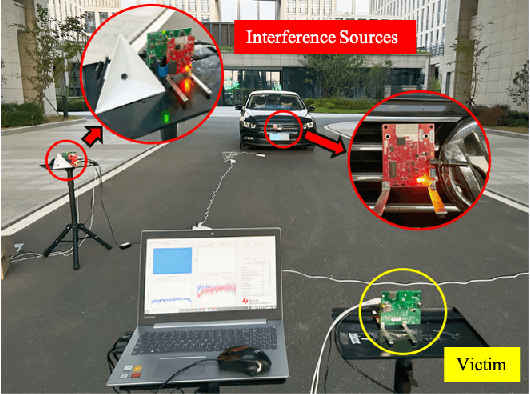

Frequency-modulated continuous-wave (FMCW) radar plays a pivotal role in the field of remote sensing. The increasing degree of FMCW radar deployment has increased the mutual interference, which weakens the detection capabilities of radars and threatens reliability and safety of systems. In this paper, a novel FMCW radar interference mitigation (RIM) method, termed as RIMformer, is proposed by using an end-to-end Transformer-based structure. In the RIMformer, a dual multi-head self-attention mechanism is proposed to capture the correlations among the distinct distance elements of intermediate frequency (IF) signals. Additionally, an improved convolutional block is integrated to harness the power of convolution for extracting local features. The architecture is designed to process time-domain IF signals in an end-to-end manner, thereby avoiding the need for additional manual data processing steps. The improved decoder structure ensures the parallelization of the network to increase its computational efficiency. Simulation and measurement experiments are carried out to validate the accuracy and effectiveness of the proposed method. The results show that the proposed RIMformer can effectively mitigate interference and restore the target signals.
Pangu-Agent: A Fine-Tunable Generalist Agent with Structured Reasoning
Dec 22, 2023



A key method for creating Artificial Intelligence (AI) agents is Reinforcement Learning (RL). However, constructing a standalone RL policy that maps perception to action directly encounters severe problems, chief among them being its lack of generality across multiple tasks and the need for a large amount of training data. The leading cause is that it cannot effectively integrate prior information into the perception-action cycle when devising the policy. Large language models (LLMs) emerged as a fundamental way to incorporate cross-domain knowledge into AI agents but lack crucial learning and adaptation toward specific decision problems. This paper presents a general framework model for integrating and learning structured reasoning into AI agents' policies. Our methodology is motivated by the modularity found in the human brain. The framework utilises the construction of intrinsic and extrinsic functions to add previous understandings of reasoning structures. It also provides the adaptive ability to learn models inside every module or function, consistent with the modular structure of cognitive processes. We describe the framework in-depth and compare it with other AI pipelines and existing frameworks. The paper explores practical applications, covering experiments that show the effectiveness of our method. Our results indicate that AI agents perform and adapt far better when organised reasoning and prior knowledge are embedded. This opens the door to more resilient and general AI agent systems.
Power Control for a URLLC-enabled UAV system incorporated with DNN-Based Channel Estimation
Nov 14, 2020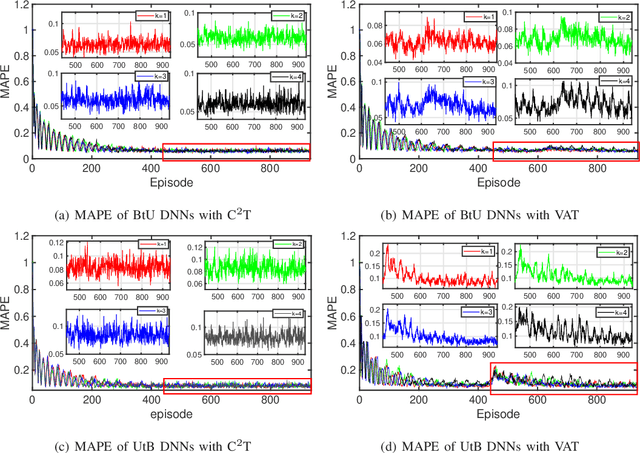
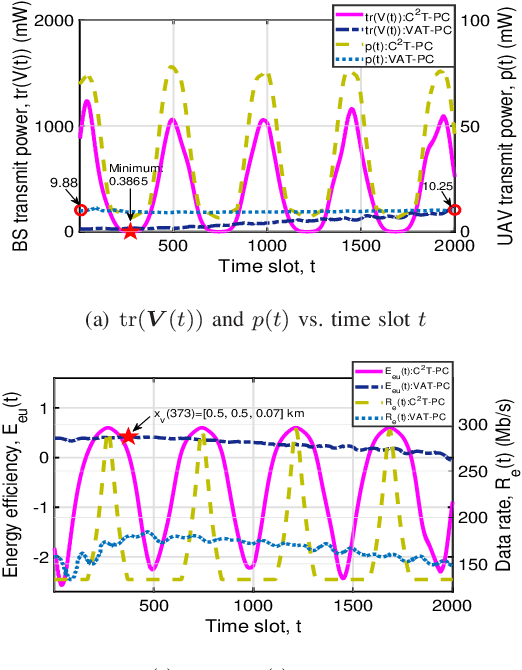
This letter is concerned with power control for a ultra-reliable and low-latency communications (URLLC) enabled unmanned aerial vehicle (UAV) system incorporated with deep neural network (DNN) based channel estimation. Particularly, we formulate the power control problem for the UAV system as an optimization problem to accommodate the URLLC requirement of uplink control and non-payload signal delivery while ensuring the downlink high-speed payload transmission. This problem is challenging to be solved due to the requirement of analytically tractable channel models and the non-convex characteristic as well. To address the challenges, we propose a novel power control algorithm, which constructs analytically tractable channel models based on DNN estimation results and explores a semidefinite relaxation (SDR) scheme to tackle the non-convexity. Simulation results demonstrate the accuracy of the DNN estimation and verify the effectiveness of the proposed algorithm.