 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise-Robust Tiny Object Localization with Flows
Jan 02, 2026Despite significant advances in generic object detection, a persistent performance gap remains for tiny objects compared to normal-scale objects. We demonstrate that tiny objects are highly sensitive to annotation noise, where optimizing strict localization objectives risks noise overfitting. To address this, we propose Tiny Object Localization with Flows (TOLF), a noise-robust localization framework leveraging normalizing flows for flexible error modeling and uncertainty-guided optimization. Our method captures complex, non-Gaussian prediction distributions through flow-based error modeling, enabling robust learning under noisy supervision. An uncertainty-aware gradient modulation mechanism further suppresses learning from high-uncertainty, noise-prone samples, mitigating overfitting while stabilizing training. Extensive experiments across three datasets validate our approach's effectiveness. Especially, TOLF boosts the DINO baseline by 1.2% AP on the AI-TOD dataset.
Adaptive Subarray Segmentation: A New Paradigm of Spatial Non-Stationary Near-Field Channel Estimation for XL-MIMO Systems
Mar 06, 2025



To tackle the complexities of spatial non-stationary (SnS) effects and spherical wave propagation in near-field channel estimation (CE) for extremely large-scale multiple-input multiple-output (XL-MIMO) systems, this paper introduces an innovative SnS near-field CE framework grounded in adaptive subarray partitioning. Conventional methods relying on equal subarray partitioning often lead to suboptimal divisions, undermining CE precision. To overcome this, we propose an adaptive subarray segmentation approach. First, we develop a spherical-wave channel model customized for line-of-sight (LoS) XL-MIMO systems to capture SnS traits. Next, we define and evaluate the adverse effects of over-segmentation and under-segmentation on CE efficacy. To counter these issues, we introduce a novel dynamic hybrid beamforming-assisted power-based subarray segmentation paradigm (DHBF-PSSP), which merges cost-effective power measurements with a DHBF structure, enabling joint subarray partitioning and decoupling. A robust partitioning algorithm, termed power-adaptive subarray segmentation (PASS), exploits statistical features of power profiles, while the DHBF utilizes subarray segmentation-based group time block code (SS-GTBC) to enable efficient subarray decoupling with limited radio frequency (RF) chain resources. Additionally, by utilizing angular-domain block sparsity and inter-subcarrier structured sparsity, we propose a subarray segmentation-based assorted block sparse Bayesian learning algorithm under the multiple measurement vectors framework (SS-ABSBL-MMV), employing discrete Fourier transform (DFT) codebooks to lower complexity. Extensive simulation results validate the exceptional performance of the proposed framework over its counterparts.
Prompt as Knowledge Bank: Boost Vision-language model via Structural Representation for zero-shot medical detection
Feb 22, 2025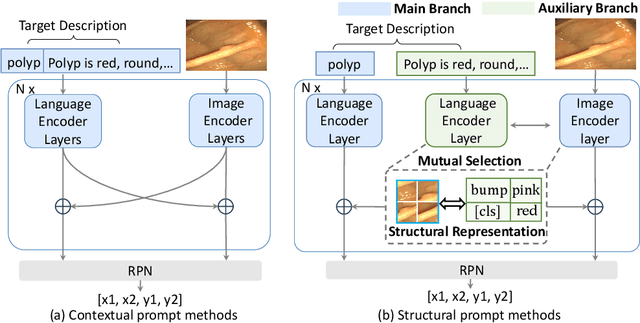

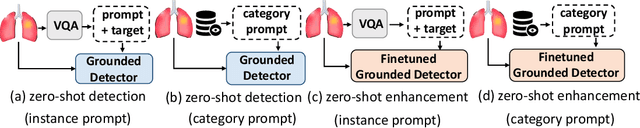

Zero-shot medical detection can further improve detection performance without relying on annotated medical images even upon the fine-tuned model, showing great clinical value. Recent studies leverage grounded vision-language models (GLIP) to achieve this by using detailed disease descriptions as prompts for the target disease name during the inference phase. However, these methods typically treat prompts as equivalent context to the target name, making it difficult to assign specific disease knowledge based on visual information, leading to a coarse alignment between images and target descriptions. In this paper, we propose StructuralGLIP, which introduces an auxiliary branch to encode prompts into a latent knowledge bank layer-by-layer, enabling more context-aware and fine-grained alignment. Specifically, in each layer, we select highly similar features from both the image representation and the knowledge bank, forming structural representations that capture nuanced relationships between image patches and target descriptions. These features are then fused across modalities to further enhance detection performance. Extensive experiments demonstrate that StructuralGLIP achieves a +4.1\% AP improvement over prior state-of-the-art methods across seven zero-shot medical detection benchmarks, and consistently improves fine-tuned models by +3.2\% AP on endoscopy image datasets.
DNN Task Assignment in UAV Networks: A Generative AI Enhanced Multi-Agent Reinforcement Learning Approach
Nov 13, 2024



Unmanned Aerial Vehicles (UAVs) possess high mobility and flexible deployment capabilities, prompting the development of UAVs for various application scenarios within the Internet of Things (IoT). The unique capabilities of UAVs give rise to increasingly critical and complex tasks in uncertain and potentially harsh environments. The substantial amount of data generated from these applications necessitates processing and analysis through deep neural networks (DNNs). However, UAVs encounter challenges due to their limited computing resources when managing DNN models. This paper presents a joint approach that combines multiple-agent reinforcement learning (MARL) and generative diffusion models (GDM) for assigning DNN tasks to a UAV swarm, aimed at reducing latency from task capture to result output. To address these challenges, we first consider the task size of the target area to be inspected and the shortest flying path as optimization constraints, employing a greedy algorithm to resolve the subproblem with a focus on minimizing the UAV's flying path and the overall system cost. In the second stage, we introduce a novel DNN task assignment algorithm, termed GDM-MADDPG, which utilizes the reverse denoising process of GDM to replace the actor network in multi-agent deep deterministic policy gradient (MADDPG). This approach generates specific DNN task assignment actions based on agents' observations in a dynamic environment. Simulation results indicate that our algorithm performs favorably compared to benchmarks in terms of path planning, Age of Information (AoI), energy consumption, and task load balancing.
P4Q: Learning to Prompt for Quantization in Visual-language Models
Sep 26, 2024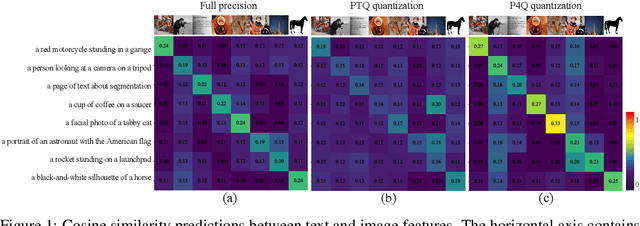
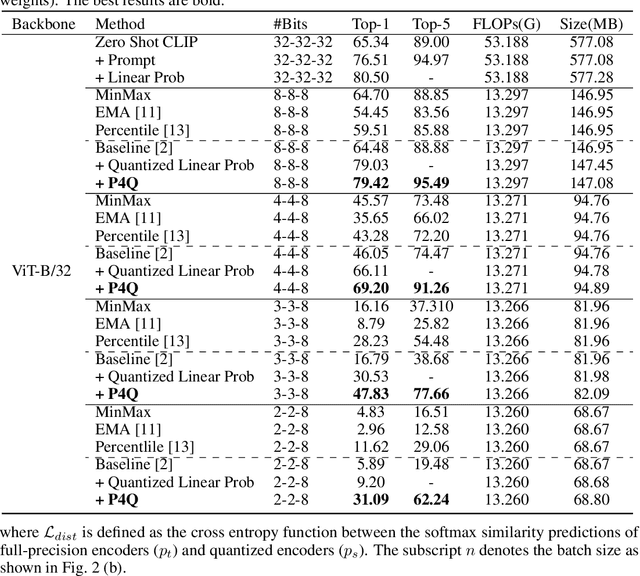
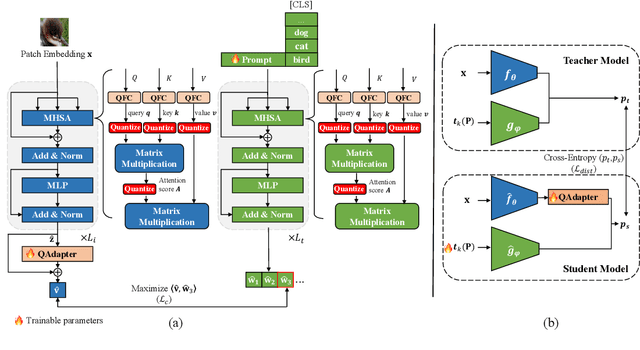
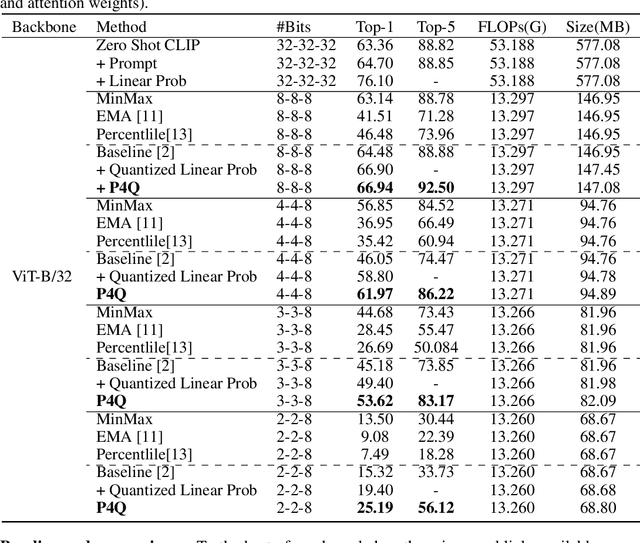
Large-scale pre-trained Vision-Language Models (VLMs) have gained prominence in various visual and multimodal tasks, yet the deployment of VLMs on downstream application platforms remains challenging due to their prohibitive requirements of training samples and computing resources. Fine-tuning and quantization of VLMs can substantially reduce the sample and computation costs, which are in urgent need. There are two prevailing paradigms in quantization, Quantization-Aware Training (QAT) can effectively quantize large-scale VLMs but incur a huge training cost, while low-bit Post-Training Quantization (PTQ) suffers from a notable performance drop. We propose a method that balances fine-tuning and quantization named ``Prompt for Quantization'' (P4Q), in which we design a lightweight architecture to leverage contrastive loss supervision to enhance the recognition performance of a PTQ model. Our method can effectively reduce the gap between image features and text features caused by low-bit quantization, based on learnable prompts to reorganize textual representations and a low-bit adapter to realign the distributions of image and text features. We also introduce a distillation loss based on cosine similarity predictions to distill the quantized model using a full-precision teacher. Extensive experimental results demonstrate that our P4Q method outperforms prior arts, even achieving comparable results to its full-precision counterparts. For instance, our 8-bit P4Q can theoretically compress the CLIP-ViT/B-32 by 4 $\times$ while achieving 66.94\% Top-1 accuracy, outperforming the learnable prompt fine-tuned full-precision model by 2.24\% with negligible additional parameters on the ImageNet dataset.
Joint Source-Channel Optimization for UAV Video Coding and Transmission
Aug 13, 2024
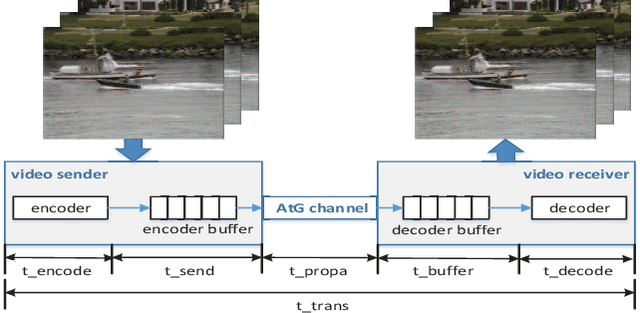
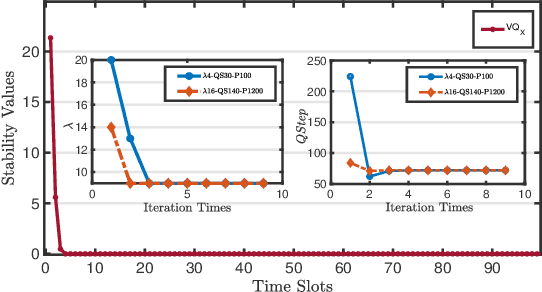
This paper is concerned with unmanned aerial vehicle (UAV) video coding and transmission in scenarios such as emergency rescue and environmental monitoring. Unlike existing methods of modeling video source coding and channel transmission separately, we investigate the joint source-channel optimization issue for video coding and transmission. Particularly, we design eight-dimensional delay-power-rate-distortion models in terms of source coding and channel transmission and characterize the correlation between video coding and transmission, with which a joint source-channel optimization problem is formulated. Its objective is to minimize end-to-end distortion and UAV power consumption by optimizing fine-grained parameters related to UAV video coding and transmission. This problem is confirmed to be a challenging sequential-decision and non-convex optimization problem. We therefore decompose it into a family of repeated optimization problems by Lyapunov optimization and design an approximate convex optimization scheme with provable performance guarantees to tackle these problems. Based on the theoretical transformation, we propose a Lyapunov repeated iteration (LyaRI) algorithm. Extensive experiments are conducted to comprehensively evaluate the performance of LyaRI. Experimental results indicate that compared to its counterparts, LyaRI is robust to initial settings of encoding parameters, and the variance of its achieved encoding bitrate is reduced by 47.74%.
Pilot-Aided Joint Time Synchronization and Channel Estimation for OTFS
Aug 08, 2024



In this letter, we propose a joint time synchronization and channel estimation (JTSCE) algorithm with embedded pilot for orthogonal time frequency space (OTFS) systems. It completes both synchronization and channel estimation using the same pilot signal. Unlike existing synchronization and channel estimation algorithms based on embedded pilots, JTSCE employs a maximum length sequence (MLS) rather than an isolated signal as the pilot. Specifically, JTSCE first explores the autocorrelation properties of MLS to estimate timing offset (TO) and channel delay taps. After obtaining these types of delay taps, the closed-form estimation expressions of the Doppler and channel gain of each propagation path are derived. Extensive simulation results indicate that compared to its counterparts, JTSCE achieves better bit error rate (BER) performance, close to that with perfect time synchronization and channel state information.
Survey on Near-Space Information Networks: Channel Modeling, Networking, and Transmission Perspectives
Oct 13, 2023



Near-space information networks (NSIN) composed of high-altitude platforms (HAPs), high- and low-altitude unmanned aerial vehicles (UAVs) are a new regime for providing quickly, robustly, and cost-efficiently sensing and communication services. Precipitated by innovations and breakthroughs in manufacturing, materials, communications, electronics, and control technologies, NSIN have emerged as an essential component of the emerging sixth-generation of mobile communication systems. This article aims at providing and discussing the latest advances in NSIN in the research areas of channel modeling, networking, and transmission from a forward-looking, comparative, and technological evolutionary perspective. In this article, we highlight the characteristics of NSIN and present the promising use-cases of NSIN. The impact of airborne platforms' unstable movements on the phase delays of onboard antenna arrays with diverse structures is mathematically analyzed. The recent advancements in HAP channel modeling are elaborated on, along with the significant differences between HAP and UAV channel modeling. A comprehensive review of the networking technologies of NSIN in network deployment, handoff management, and network management aspects is provided. Besides, the promising technologies and communication protocols of the physical layer, medium access control (MAC) layer, network layer, and transport layer of NSIN for achieving efficient transmission over NSIN are overviewed. Finally, we outline some open issues and promising directions of NSIN deserved for future study and discuss the corresponding challenges.
Heterogeneous Generative Knowledge Distillation with Masked Image Modeling
Sep 18, 2023



Small CNN-based models usually require transferring knowledge from a large model before they are deployed in computationally resource-limited edge devices. Masked image modeling (MIM) methods achieve great success in various visual tasks but remain largely unexplored in knowledge distillation for heterogeneous deep models. The reason is mainly due to the significant discrepancy between the Transformer-based large model and the CNN-based small network. In this paper, we develop the first Heterogeneous Generative Knowledge Distillation (H-GKD) based on MIM, which can efficiently transfer knowledge from large Transformer models to small CNN-based models in a generative self-supervised fashion. Our method builds a bridge between Transformer-based models and CNNs by training a UNet-style student with sparse convolution, which can effectively mimic the visual representation inferred by a teacher over masked modeling. Our method is a simple yet effective learning paradigm to learn the visual representation and distribution of data from heterogeneous teacher models, which can be pre-trained using advanced generative methods. Extensive experiments show that it adapts well to various models and sizes, consistently achieving state-of-the-art performance in image classification, object detection, and semantic segmentation tasks. For example, in the Imagenet 1K dataset, H-GKD improves the accuracy of Resnet50 (sparse) from 76.98% to 80.01%.
Representation Disparity-aware Distillation for 3D Object Detection
Aug 20, 2023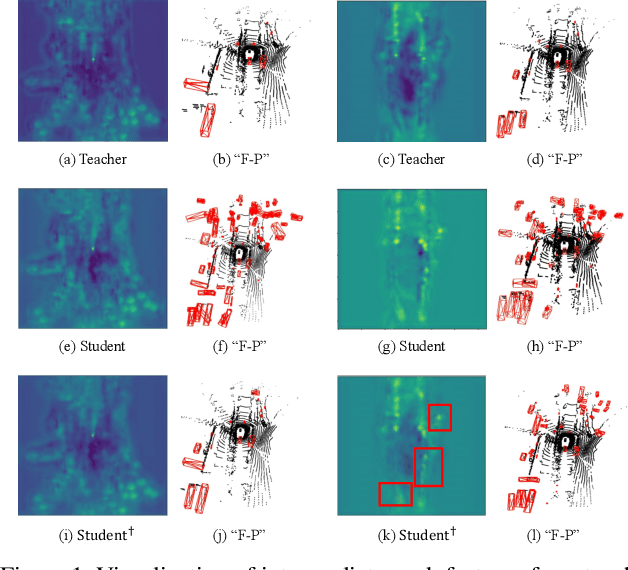
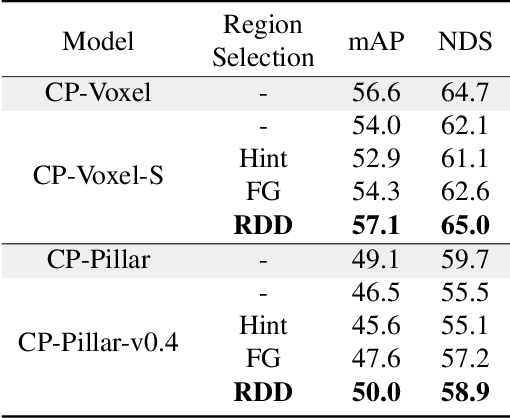
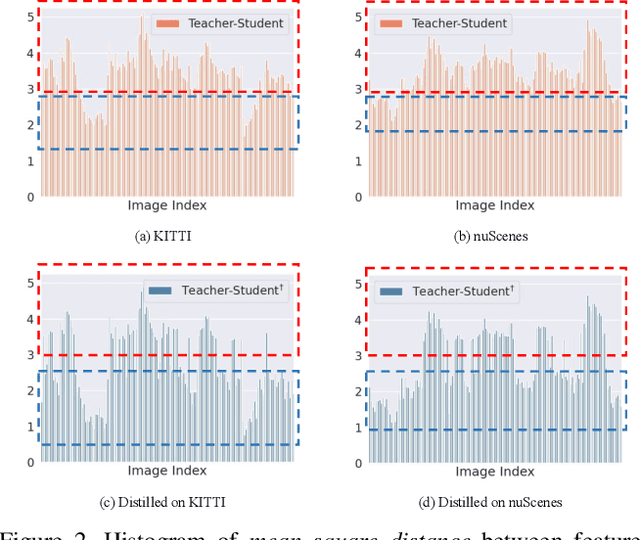
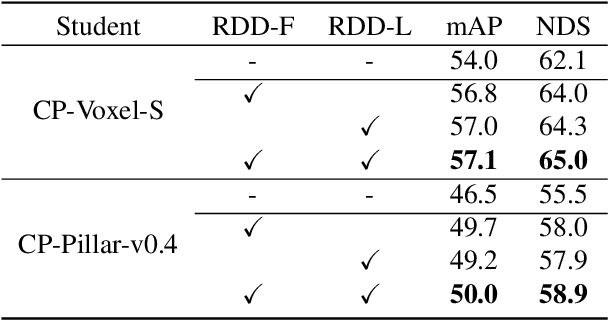
In this paper, we focus on developing knowledge distillation (KD) for compact 3D detectors. We observe that off-the-shelf KD methods manifest their efficacy only when the teacher model and student counterpart share similar intermediate feature representations. This might explain why they are less effective in building extreme-compact 3D detectors where significant representation disparity arises due primarily to the intrinsic sparsity and irregularity in 3D point clouds. This paper presents a novel representation disparity-aware distillation (RDD) method to address the representation disparity issue and reduce performance gap between compact students and over-parameterized teachers. This is accomplished by building our RDD from an innovative perspective of information bottleneck (IB), which can effectively minimize the disparity of proposal region pairs from student and teacher in features and logits. Extensive experiments are performed to demonstrate the superiority of our RDD over existing KD methods. For example, our RDD increases mAP of CP-Voxel-S to 57.1% on nuScenes dataset, which even surpasses teacher performance while taking up only 42% FLOPs.