 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise-Robust Tiny Object Localization with Flows
Jan 02, 2026Despite significant advances in generic object detection, a persistent performance gap remains for tiny objects compared to normal-scale objects. We demonstrate that tiny objects are highly sensitive to annotation noise, where optimizing strict localization objectives risks noise overfitting. To address this, we propose Tiny Object Localization with Flows (TOLF), a noise-robust localization framework leveraging normalizing flows for flexible error modeling and uncertainty-guided optimization. Our method captures complex, non-Gaussian prediction distributions through flow-based error modeling, enabling robust learning under noisy supervision. An uncertainty-aware gradient modulation mechanism further suppresses learning from high-uncertainty, noise-prone samples, mitigating overfitting while stabilizing training. Extensive experiments across three datasets validate our approach's effectiveness. Especially, TOLF boosts the DINO baseline by 1.2% AP on the AI-TOD dataset.
P4Q: Learning to Prompt for Quantization in Visual-language Models
Sep 26, 2024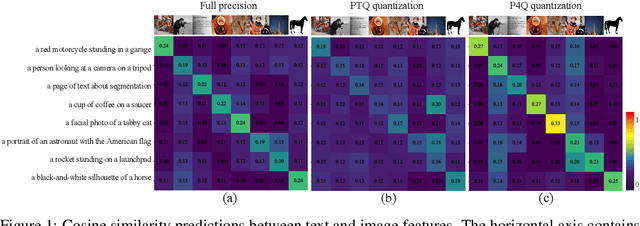
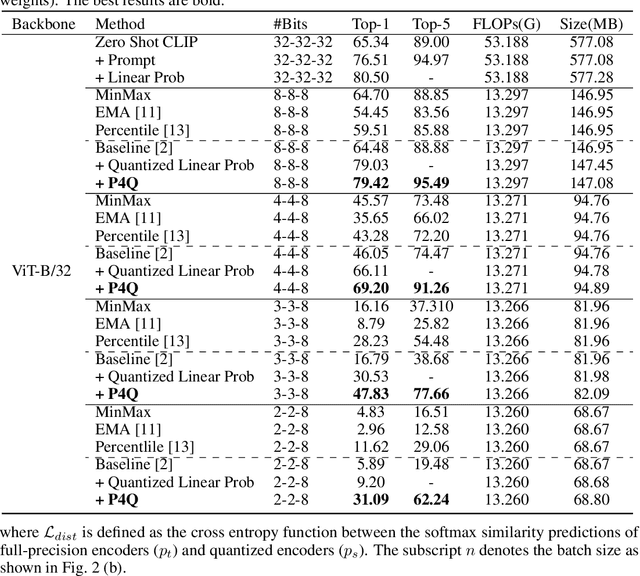
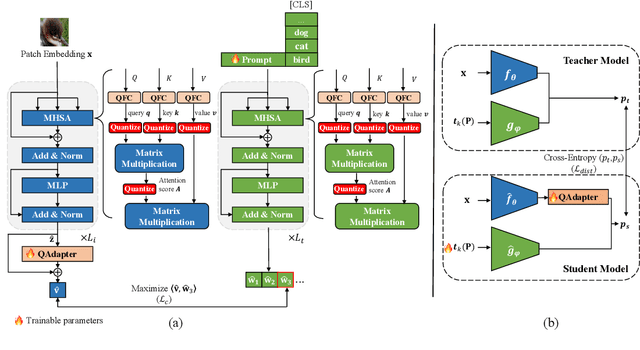
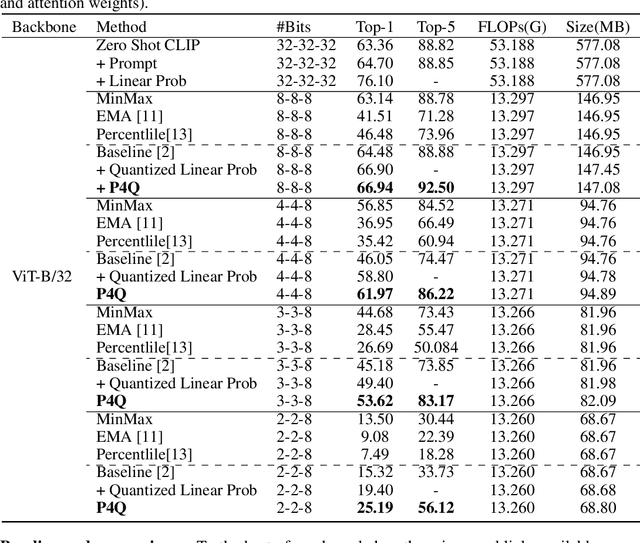
Large-scale pre-trained Vision-Language Models (VLMs) have gained prominence in various visual and multimodal tasks, yet the deployment of VLMs on downstream application platforms remains challenging due to their prohibitive requirements of training samples and computing resources. Fine-tuning and quantization of VLMs can substantially reduce the sample and computation costs, which are in urgent need. There are two prevailing paradigms in quantization, Quantization-Aware Training (QAT) can effectively quantize large-scale VLMs but incur a huge training cost, while low-bit Post-Training Quantization (PTQ) suffers from a notable performance drop. We propose a method that balances fine-tuning and quantization named ``Prompt for Quantization'' (P4Q), in which we design a lightweight architecture to leverage contrastive loss supervision to enhance the recognition performance of a PTQ model. Our method can effectively reduce the gap between image features and text features caused by low-bit quantization, based on learnable prompts to reorganize textual representations and a low-bit adapter to realign the distributions of image and text features. We also introduce a distillation loss based on cosine similarity predictions to distill the quantized model using a full-precision teacher. Extensive experimental results demonstrate that our P4Q method outperforms prior arts, even achieving comparable results to its full-precision counterparts. For instance, our 8-bit P4Q can theoretically compress the CLIP-ViT/B-32 by 4 $\times$ while achieving 66.94\% Top-1 accuracy, outperforming the learnable prompt fine-tuned full-precision model by 2.24\% with negligible additional parameters on the ImageNet dataset.
Q-YOLO: Efficient Inference for Real-time Object Detection
Jul 01, 2023Real-time object detection plays a vital role in various computer vision applications. However, deploying real-time object detectors on resource-constrained platforms poses challenges due to high computational and memory requirements. This paper describes a low-bit quantization method to build a highly efficient one-stage detector, dubbed as Q-YOLO, which can effectively address the performance degradation problem caused by activation distribution imbalance in traditional quantized YOLO models. Q-YOLO introduces a fully end-to-end Post-Training Quantization (PTQ) pipeline with a well-designed Unilateral Histogram-based (UH) activation quantization scheme, which determines the maximum truncation values through histogram analysis by minimizing the Mean Squared Error (MSE) quantization errors. Extensive experiments on the COCO dataset demonstrate the effectiveness of Q-YOLO, outperforming other PTQ methods while achieving a more favorable balance between accuracy and computational cost. This research contributes to advancing the efficient deployment of object detection models on resource-limited edge devices, enabling real-time detection with reduced computational and memory overhead.
Confidence-driven Bounding Box Localization for Small Object Detection
Mar 03, 2023Despite advancements in generic object detection, there remains a performance gap in detecting small objects compared to normal-scale objects. We for the first time observe that existing bounding box regression methods tend to produce distorted gradients for small objects and result in less accurate localization. To address this issue, we present a novel Confidence-driven Bounding Box Localization (C-BBL) method to rectify the gradients. C-BBL quantizes continuous labels into grids and formulates two-hot ground truth labels. In prediction, the bounding box head generates a confidence distribution over the grids. Unlike the bounding box regression paradigms in conventional detectors, we introduce a classification-based localization objective through cross entropy between ground truth and predicted confidence distribution, generating confidence-driven gradients. Additionally, C-BBL describes a uncertainty loss based on distribution entropy in labels and predictions to further reduce the uncertainty in small object localization. The method is evaluated on multiple detectors using three object detection benchmarks and consistently improves baseline detectors, achieving state-of-the-art performance. We also demonstrate the generalizability of C-BBL to different label systems and effectiveness for high resolution detection, which validates its prospect as a general solution.