 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Shared Valence Axis Across Modern LLMs and Human EEG: The Saturation Regularity
May 28, 2026Large language models (LLMs) have emerged as powerful representation learners whose internal features increasingly align with human cognition. We study whether modern LLMs can serve as a lens for understanding neural representations in the human brain, focusing on emotional valence in EEG. We first build a one-dimensional valence direction, the V-axis, from modern LLMs using only nine emotion-evocative sentences. We validate it through zero-shot transfer to sentiment benchmarks and cross-model consistency across fourteen LLMs. We then show that this LLM-derived direction maps onto human neural activity. On a public EEG cohort of 123 subjects watching affective videos, a single linear projection on EEG features tracks the V-axis position of each stimulus. Moreover, 36 EEG emotion classifiers trained without exposure to the V-axis spontaneously rediscover the same direction in their internal representations, suggesting that the same valence structure emerges in both language models and human electrophysiology. Yet this convergence does not provide an effective training signal. We test twenty-five alignment strategies, including knowledge distillation, representational similarity, contrastive, and topographic losses; none improve decoding, and sixteen significantly reduce accuracy. We formalize this result as the saturation regularity: once task labels alone drive a brain-decoding network onto the target direction, additional supervision mainly distorts an already-saturated basin, while the load-bearing within-class residual receives little useful gradient. This regularity also indicates where improvement should come from: the residual subspace unreachable by supervision. Motivated by this insight, we ensemble across residual diversity rather than supervising the basin, improving balanced accuracy by 10.5% over the prior best on FACED, with the same effect replicated on SEED-V.
Automated Random Embedding for Practical Bayesian Optimization with Unknown Effective Dimension
May 25, 2026Bayesian optimization is widely employed for optimizing complex black-box functions but struggles with the curse of dimensionality. Random embedding, as a dimension reduction strategy, simplifies tasks that possess the effective dimension by optimizing within a low-dimensional subspace. However, determining the effective dimension of a task in advance remains a significant challenge, which influences the selection of the subspace dimensionality and the optimization performance. Traditional methods use fixed subspace dimensions provided by experts or rely on trial and error to estimate subspace dimensions with resources consumed. To this end, this paper proposes an automated random embedding for high-dimensional Bayesian optimization with unknown effective dimension, called Dynamic Shared Embedding Bayesian Optimization (DSEBO). DSEBO starts with a low dimension and switches to a higher subspace if the solutions in the current subspace show preliminary convergence. DSEBO dynamically determines the dimension of the next subspace based on the quality of the solutions in different subspaces and shares the queried solutions with the new subspace for a better initialization. Theoretically, we derive a regret bound for DSEBO and demonstrate that DSEBO can better balance approximation and optimization errors. Extensive experiments on functions with dimensionality of varying magnitudes and real-world tasks with unknown effective dimensions reveal that, compared with state-of-the-art methods, alternating optimization across different subspaces results in significant improvements in high-dimensional optimization, both in terms of optimization regret and time.
Motion Manipulation via Unsupervised Keypoint Positioning in Face Animation
Mar 04, 2026Face animation deals with controlling and generating facial features with a wide range of applications. The methods based on unsupervised keypoint positioning can produce realistic and detailed virtual portraits. However, they cannot achieve controllable face generation since the existing keypoint decomposition pipelines fail to fully decouple identity semantics and intertwined motion information (e.g., rotation, translation, and expression). To address these issues, we present a new method, Motion Manipulation via unsupervised keypoint positioning in Face Animation (MMFA). We first introduce self-supervised representation learning to encode and decode expressions in the latent feature space and decouple them from other motion information. Secondly, we propose a new way to compute keypoints aiming to achieve arbitrary motion control. Moreover, we design a variational autoencoder to map expression features to a continuous Gaussian distribution, allowing us for the first time to interpolate facial expressions in an unsupervised framework. We have conducted extensive experiments on publicly available datasets to validate the effectiveness of MMFA, which show that MMFA offers pronounced advantages over prior arts in creating realistic animation and manipulating face motion.
Unbiased Dynamic Pruning for Efficient Group-Based Policy Optimization
Mar 04, 2026Group Relative Policy Optimization (GRPO) effectively scales LLM reasoning but incurs prohibitive computational costs due to its extensive group-based sampling requirement. While recent selective data utilization methods can mitigate this overhead, they could induce estimation bias by altering the underlying sampling distribution, compromising theoretical rigor and convergence behavior. To address this limitation, we propose Dynamic Pruning Policy Optimization (DPPO), a framework that enables dynamic pruning while preserving unbiased gradient estimation through importance sampling-based correction. By incorporating mathematically derived rescaling factors, DPPO significantly accelerates GRPO training without altering the optimization objective of the full-batch baseline. Furthermore, to mitigate the data sparsity induced by pruning, we introduce Dense Prompt Packing, a window-based greedy strategy that maximizes valid token density and hardware utilization. Extensive experiments demonstrate that DPPO consistently accelerates training across diverse models and benchmarks. For instance, on Qwen3-4B trained on MATH, DPPO achieves 2.37$\times$ training speedup and outperforms GRPO by 3.36% in average accuracy across six mathematical reasoning benchmarks.
Dual Diffusion Models for Multi-modal Guided 3D Avatar Generation
Mar 04, 2026Generating high-fidelity 3D avatars from text or image prompts is highly sought after in virtual reality and human-computer interaction. However, existing text-driven methods often rely on iterative Score Distillation Sampling (SDS) or CLIP optimization, which struggle with fine-grained semantic control and suffer from excessively slow inference. Meanwhile, image-driven approaches are severely bottlenecked by the scarcity and high acquisition cost of high-quality 3D facial scans, limiting model generalization. To address these challenges, we first construct a novel, large-scale dataset comprising over 100,000 pairs across four modalities: fine-grained textual descriptions, in-the-wild face images, high-quality light-normalized texture UV maps, and 3D geometric shapes. Leveraging this comprehensive dataset, we propose PromptAvatar, a framework featuring dual diffusion models. Specifically, it integrates a Texture Diffusion Model (TDM) that supports flexible multi-condition guidance from text and/or image prompts, alongside a Geometry Diffusion Model (GDM) guided by text prompts. By learning the direct mapping from multi-modal prompts to 3D representations, PromptAvatar eliminates the need for time-consuming iterative optimization, successfully generating high-fidelity, shading-free 3D avatars in under 10 seconds. Extensive quantitative and qualitative experiments demonstrate that our method significantly outperforms existing state-of-the-art approaches in generation quality, fine-grained detail alignment, and computational efficiency.
Pixel Super-Resolved Fluorescence Lifetime Imaging Using Deep Learning
Dec 18, 2025



Fluorescence lifetime imaging microscopy (FLIM) is a powerful quantitative technique that provides metabolic and molecular contrast, offering strong translational potential for label-free, real-time diagnostics. However, its clinical adoption remains limited by long pixel dwell times and low signal-to-noise ratio (SNR), which impose a stricter resolution-speed trade-off than conventional optical imaging approaches. Here, we introduce FLIM_PSR_k, a deep learning-based multi-channel pixel super-resolution (PSR) framework that reconstructs high-resolution FLIM images from data acquired with up to a 5-fold increased pixel size. The model is trained using the conditional generative adversarial network (cGAN) framework, which, compared to diffusion model-based alternatives, delivers a more robust PSR reconstruction with substantially shorter inference times, a crucial advantage for practical deployment. FLIM_PSR_k not only enables faster image acquisition but can also alleviate SNR limitations in autofluorescence-based FLIM. Blind testing on held-out patient-derived tumor tissue samples demonstrates that FLIM_PSR_k reliably achieves a super-resolution factor of k = 5, resulting in a 25-fold increase in the space-bandwidth product of the output images and revealing fine architectural features lost in lower-resolution inputs, with statistically significant improvements across various image quality metrics. By increasing FLIM's effective spatial resolution, FLIM_PSR_k advances lifetime imaging toward faster, higher-resolution, and hardware-flexible implementations compatible with low-numerical-aperture and miniaturized platforms, better positioning FLIM for translational applications.
Surf3R: Rapid Surface Reconstruction from Sparse RGB Views in Seconds
Aug 06, 2025
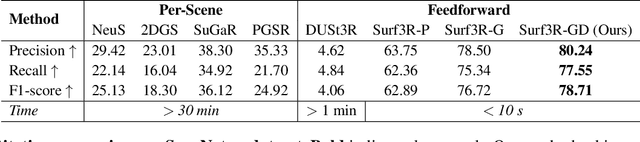
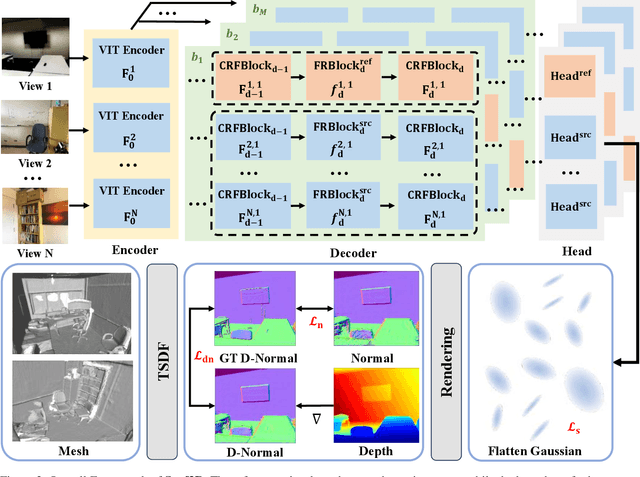

Current multi-view 3D reconstruction methods rely on accurate camera calibration and pose estimation, requiring complex and time-intensive pre-processing that hinders their practical deployment. To address this challenge, we introduce Surf3R, an end-to-end feedforward approach that reconstructs 3D surfaces from sparse views without estimating camera poses and completes an entire scene in under 10 seconds. Our method employs a multi-branch and multi-view decoding architecture in which multiple reference views jointly guide the reconstruction process. Through the proposed branch-wise processing, cross-view attention, and inter-branch fusion, the model effectively captures complementary geometric cues without requiring camera calibration. Moreover, we introduce a D-Normal regularizer based on an explicit 3D Gaussian representation for surface reconstruction. It couples surface normals with other geometric parameters to jointly optimize the 3D geometry, significantly improving 3D consistency and surface detail accuracy. Experimental results demonstrate that Surf3R achieves state-of-the-art performance on multiple surface reconstruction metrics on ScanNet++ and Replica datasets, exhibiting excellent generalization and efficiency.
Light of Normals: Unified Feature Representation for Universal Photometric Stereo
Jun 24, 2025
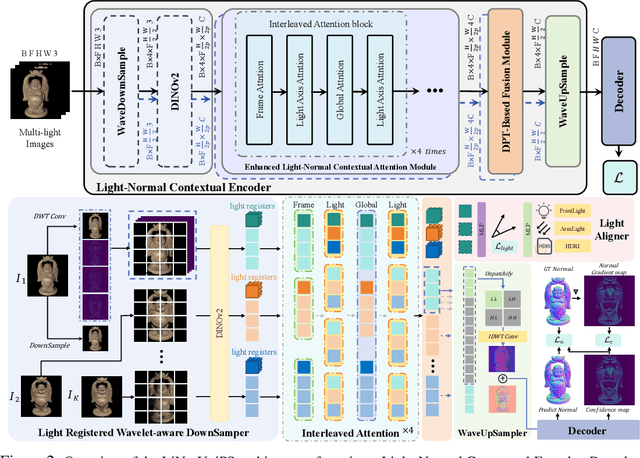
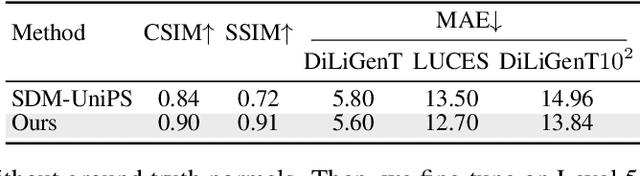

Universal photometric stereo (PS) aims to recover high-quality surface normals from objects under arbitrary lighting conditions without relying on specific illumination models. Despite recent advances such as SDM-UniPS and Uni MS-PS, two fundamental challenges persist: 1) the deep coupling between varying illumination and surface normal features, where ambiguity in observed intensity makes it difficult to determine whether brightness variations stem from lighting changes or surface orientation; and 2) the preservation of high-frequency geometric details in complex surfaces, where intricate geometries create self-shadowing, inter-reflections, and subtle normal variations that conventional feature processing operations struggle to capture accurately.
MASS: Multi-Agent Simulation Scaling for Portfolio Construction
May 15, 2025LLM-based multi-agent has gained significant attention for their potential in simulation and enhancing performance. However, existing works are limited to pure simulations or are constrained by predefined workflows, restricting their applicability and effectiveness. In this paper, we introduce the Multi-Agent Scaling Simulation (MASS) for portfolio construction. MASS achieves stable and continuous excess returns by progressively increasing the number of agents for large-scale simulations to gain a superior understanding of the market and optimizing agent distribution end-to-end through a reverse optimization process, rather than relying on a fixed workflow. We demonstrate its superiority through performance experiments, ablation studies, backtesting experiments, experiments on updated data and stock pools, scaling experiments, parameter sensitivity experiments, and visualization experiments, conducted in comparison with 6 state-of-the-art baselines on 3 challenging A-share stock pools. We expect the paradigm established by MASS to expand to other tasks with similar characteristics. The implementation of MASS has been open-sourced at https://github.com/gta0804/MASS.
Reconstruct Spine CT from Biplanar X-Rays via Diffusion Learning
Aug 21, 2024

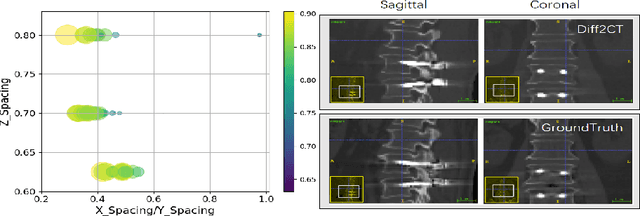
Intraoperative CT imaging serves as a crucial resource for surgical guidance; however, it may not always be readily accessible or practical to implement. In scenarios where CT imaging is not an option, reconstructing CT scans from X-rays can offer a viable alternative. In this paper, we introduce an innovative method for 3D CT reconstruction utilizing biplanar X-rays. Distinct from previous research that relies on conventional image generation techniques, our approach leverages a conditional diffusion process to tackle the task of reconstruction. More precisely, we employ a diffusion-based probabilistic model trained to produce 3D CT images based on orthogonal biplanar X-rays. To improve the structural integrity of the reconstructed images, we incorporate a novel projection loss function. Experimental results validate that our proposed method surpasses existing state-of-the-art benchmarks in both visual image quality and multiple evaluative metrics. Specifically, our technique achieves a higher Structural Similarity Index (SSIM) of 0.83, a relative increase of 10\%, and a lower Fr\'echet Inception Distance (FID) of 83.43, which represents a relative decrease of 25\%.