 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLA-Thinker: Boosting Vision-Language-Action Models through Thinking-with-Image Reasoning
Mar 15, 2026Vision-Language-Action (VLA) models have shown promising capabilities for embodied intelligence, but most existing approaches rely on text-based chain-of-thought reasoning where visual inputs are treated as static context. This limits the ability of the model to actively revisit the environment and resolve ambiguities during long-horizon tasks. We propose VLA-Thinker, a thinking-with-image reasoning framework that models perception as a dynamically invocable reasoning action. To train such a system, we introduce a two-stage training pipeline consisting of (1) an SFT cold-start phase with curated visual Chain-of-Thought data to activate structured reasoning and tool-use behaviors, and (2) GRPO-based reinforcement learning to align complete reasoning-action trajectories with task-level success. Extensive experiments on LIBERO and RoboTwin 2.0 benchmarks demonstrate that VLA-Thinker significantly improves manipulation performance, achieving 97.5% success rate on LIBERO and strong gains across long-horizon robotic tasks. Project and Codes: https://cywang735.github.io/VLA-Thinker/ .
e5-omni: Explicit Cross-modal Alignment for Omni-modal Embeddings
Jan 07, 2026Modern information systems often involve different types of items, e.g., a text query, an image, a video clip, or an audio segment. This motivates omni-modal embedding models that map heterogeneous modalities into a shared space for direct comparison. However, most recent omni-modal embeddings still rely heavily on implicit alignment inherited from pretrained vision-language model (VLM) backbones. In practice, this causes three common issues: (i) similarity logits have modality-dependent sharpness, so scores are not on a consistent scale; (ii) in-batch negatives become less effective over time because mixed-modality batches create an imbalanced hardness distribution; as a result, many negatives quickly become trivial and contribute little gradient; and (iii) embeddings across modalities show mismatched first- and second-order statistics, which makes rankings less stable. To tackle these problems, we propose e5-omni, a lightweight explicit alignment recipe that adapts off-the-shelf VLMs into robust omni-modal embedding models. e5-omni combines three simple components: (1) modality-aware temperature calibration to align similarity scales, (2) a controllable negative curriculum with debiasing to focus on confusing negatives while reducing the impact of false negatives, and (3) batch whitening with covariance regularization to better match cross-modal geometry in the shared embedding space. Experiments on MMEB-V2 and AudioCaps show consistent gains over strong bi-modal and omni-modal baselines, and the same recipe also transfers well to other VLM backbones. We release our model checkpoint at https://huggingface.co/Haon-Chen/e5-omni-7B.
AdaTooler-V: Adaptive Tool-Use for Images and Videos
Dec 19, 2025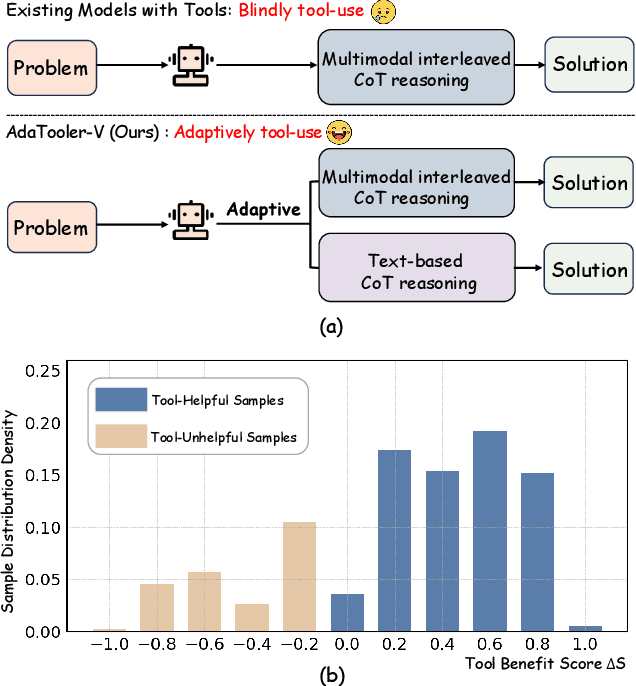
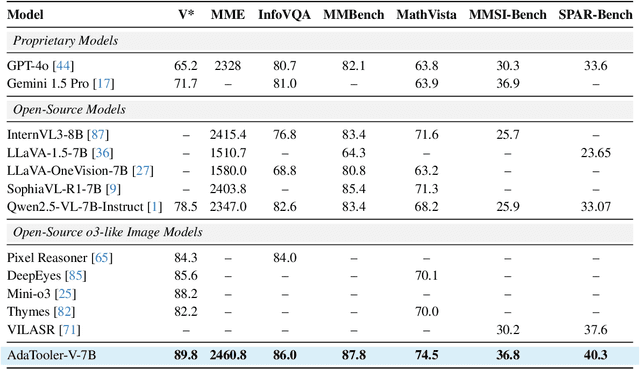
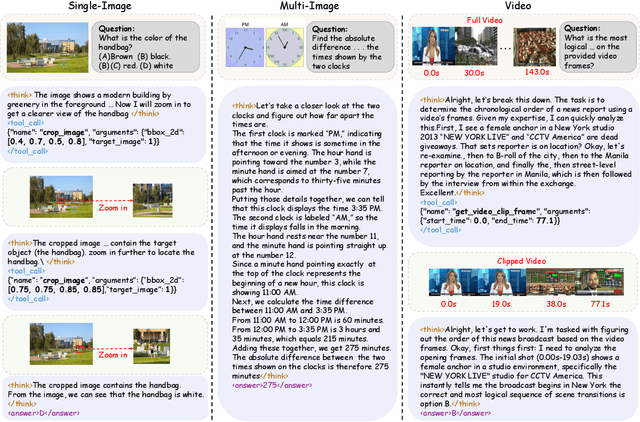
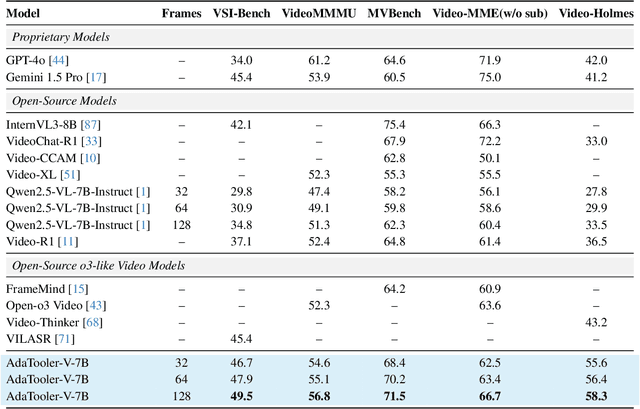
Recent advances have shown that multimodal large language models (MLLMs) benefit from multimodal interleaved chain-of-thought (CoT) with vision tool interactions. However, existing open-source models often exhibit blind tool-use reasoning patterns, invoking vision tools even when they are unnecessary, which significantly increases inference overhead and degrades model performance. To this end, we propose AdaTooler-V, an MLLM that performs adaptive tool-use by determining whether a visual problem truly requires tools. First, we introduce AT-GRPO, a reinforcement learning algorithm that adaptively adjusts reward scales based on the Tool Benefit Score of each sample, encouraging the model to invoke tools only when they provide genuine improvements. Moreover, we construct two datasets to support training: AdaTooler-V-CoT-100k for SFT cold start and AdaTooler-V-300k for RL with verifiable rewards across single-image, multi-image, and video data. Experiments across twelve benchmarks demonstrate the strong reasoning capability of AdaTooler-V, outperforming existing methods in diverse visual reasoning tasks. Notably, AdaTooler-V-7B achieves an accuracy of 89.8\% on the high-resolution benchmark V*, surpassing the commercial proprietary model GPT-4o and Gemini 1.5 Pro. All code, models, and data are released.
DiTVR: Zero-Shot Diffusion Transformer for Video Restoration
Aug 11, 2025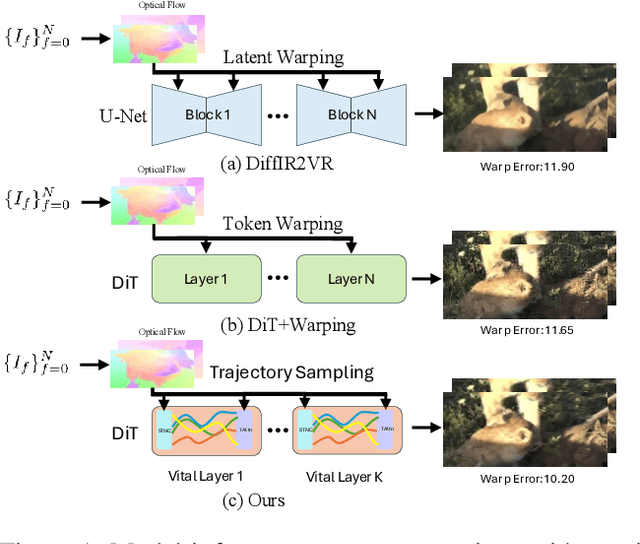


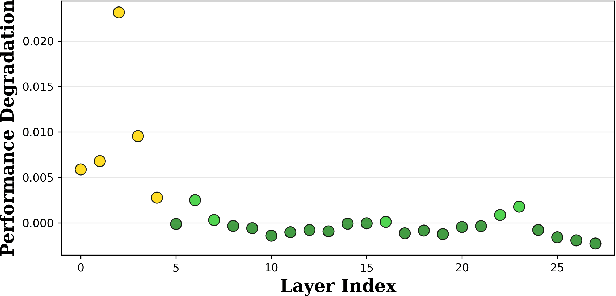
Video restoration aims to reconstruct high quality video sequences from low quality inputs, addressing tasks such as super resolution, denoising, and deblurring. Traditional regression based methods often produce unrealistic details and require extensive paired datasets, while recent generative diffusion models face challenges in ensuring temporal consistency. We introduce DiTVR, a zero shot video restoration framework that couples a diffusion transformer with trajectory aware attention and a wavelet guided, flow consistent sampler. Unlike prior 3D convolutional or frame wise diffusion approaches, our attention mechanism aligns tokens along optical flow trajectories, with particular emphasis on vital layers that exhibit the highest sensitivity to temporal dynamics. A spatiotemporal neighbour cache dynamically selects relevant tokens based on motion correspondences across frames. The flow guided sampler injects data consistency only into low-frequency bands, preserving high frequency priors while accelerating convergence. DiTVR establishes a new zero shot state of the art on video restoration benchmarks, demonstrating superior temporal consistency and detail preservation while remaining robust to flow noise and occlusions.
ZONE: Zero-Shot Instruction-Guided Local Editing
Dec 28, 2023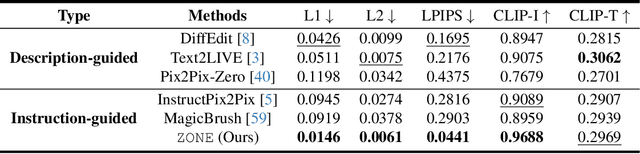
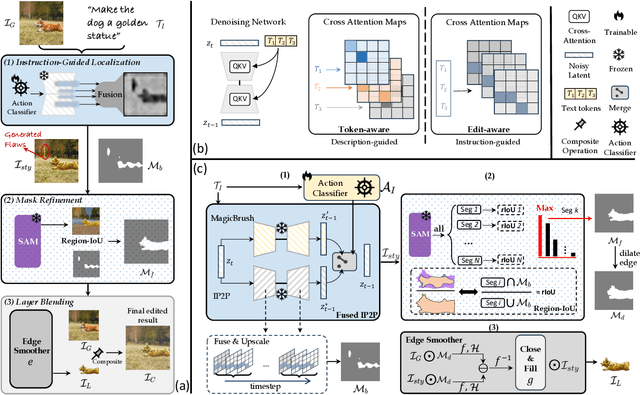
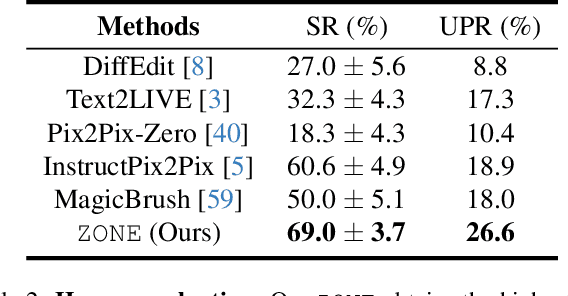
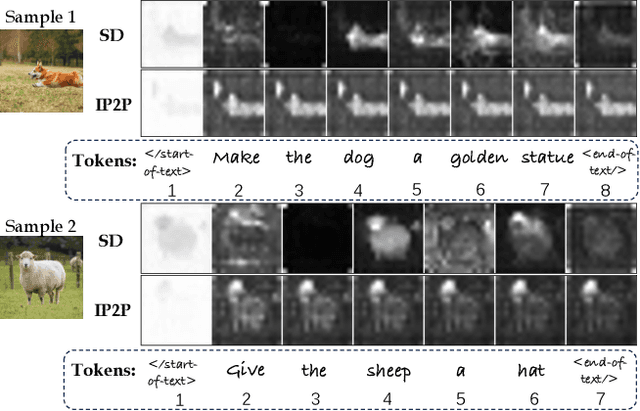
Recent advances in vision-language models like Stable Diffusion have shown remarkable power in creative image synthesis and editing.However, most existing text-to-image editing methods encounter two obstacles: First, the text prompt needs to be carefully crafted to achieve good results, which is not intuitive or user-friendly. Second, they are insensitive to local edits and can irreversibly affect non-edited regions, leaving obvious editing traces. To tackle these problems, we propose a Zero-shot instructiON-guided local image Editing approach, termed ZONE. We first convert the editing intent from the user-provided instruction (e.g., ``make his tie blue") into specific image editing regions through InstructPix2Pix. We then propose a Region-IoU scheme for precise image layer extraction from an off-the-shelf segment model. We further develop an edge smoother based on FFT for seamless blending between the layer and the image.Our method allows for arbitrary manipulation of a specific region with a single instruction while preserving the rest. Extensive experiments demonstrate that our ZONE achieves remarkable local editing results and user-friendliness, outperforming state-of-the-art methods.
IPDreamer: Appearance-Controllable 3D Object Generation with Image Prompts
Oct 09, 2023



Recent advances in text-to-3D generation have been remarkable, with methods such as DreamFusion leveraging large-scale text-to-image diffusion-based models to supervise 3D generation. These methods, including the variational score distillation proposed by ProlificDreamer, enable the synthesis of detailed and photorealistic textured meshes. However, the appearance of 3D objects generated by these methods is often random and uncontrollable, posing a challenge in achieving appearance-controllable 3D objects. To address this challenge, we introduce IPDreamer, a novel approach that incorporates image prompts to provide specific and comprehensive appearance information for 3D object generation. Our results demonstrate that IPDreamer effectively generates high-quality 3D objects that are consistent with both the provided text and image prompts, demonstrating its promising capability in appearance-controllable 3D object generation.
Controllable Mind Visual Diffusion Model
May 18, 2023Brain signal visualization has emerged as an active research area, serving as a critical interface between the human visual system and computer vision models. Although diffusion models have shown promise in analyzing functional magnetic resonance imaging (fMRI) data, including reconstructing high-quality images consistent with original visual stimuli, their accuracy in extracting semantic and silhouette information from brain signals remains limited. In this regard, we propose a novel approach, referred to as Controllable Mind Visual Diffusion Model (CMVDM). CMVDM extracts semantic and silhouette information from fMRI data using attribute alignment and assistant networks. Additionally, a residual block is incorporated to capture information beyond semantic and silhouette features. We then leverage a control model to fully exploit the extracted information for image synthesis, resulting in generated images that closely resemble the visual stimuli in terms of semantics and silhouette. Through extensive experimentation, we demonstrate that CMVDM outperforms existing state-of-the-art methods both qualitatively and quantitatively.
Face Animation with an Attribute-Guided Diffusion Model
Apr 06, 2023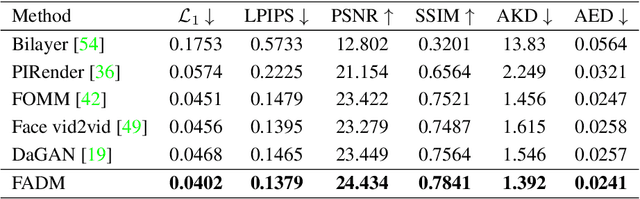
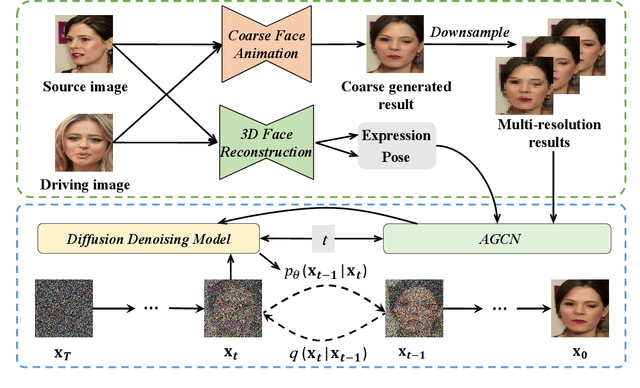
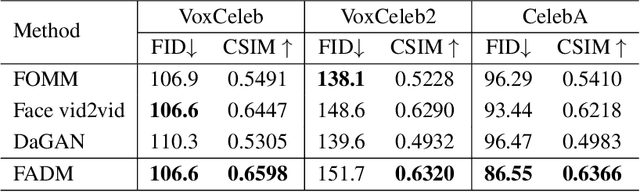
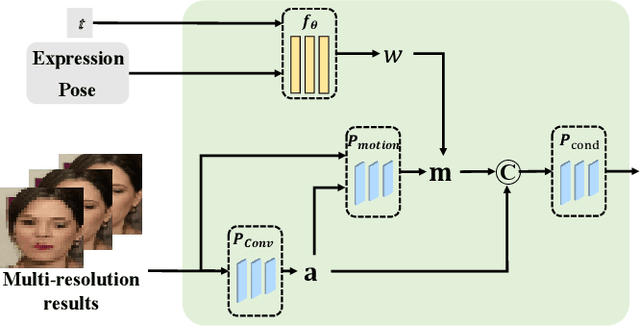
Face animation has achieved much progress in computer vision. However, prevailing GAN-based methods suffer from unnatural distortions and artifacts due to sophisticated motion deformation. In this paper, we propose a Face Animation framework with an attribute-guided Diffusion Model (FADM), which is the first work to exploit the superior modeling capacity of diffusion models for photo-realistic talking-head generation. To mitigate the uncontrollable synthesis effect of the diffusion model, we design an Attribute-Guided Conditioning Network (AGCN) to adaptively combine the coarse animation features and 3D face reconstruction results, which can incorporate appearance and motion conditions into the diffusion process. These specific designs help FADM rectify unnatural artifacts and distortions, and also enrich high-fidelity facial details through iterative diffusion refinements with accurate animation attributes. FADM can flexibly and effectively improve existing animation videos. Extensive experiments on widely used talking-head benchmarks validate the effectiveness of FADM over prior arts.
Implicit Diffusion Models for Continuous Super-Resolution
Mar 29, 2023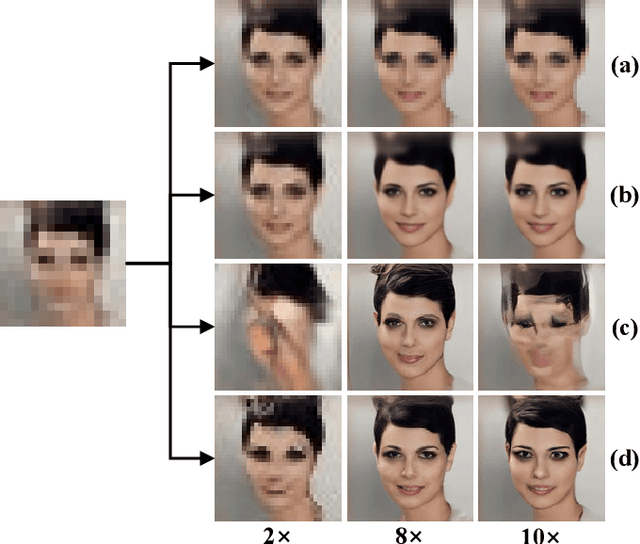


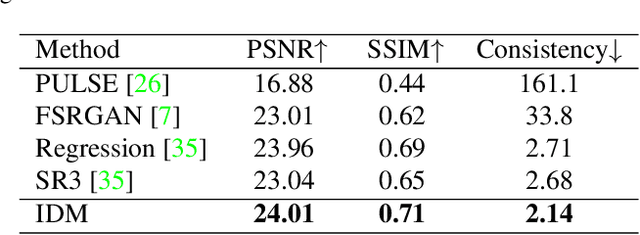
Image super-resolution (SR) has attracted increasing attention due to its wide applications. However, current SR methods generally suffer from over-smoothing and artifacts, and most work only with fixed magnifications. This paper introduces an Implicit Diffusion Model (IDM) for high-fidelity continuous image super-resolution. IDM integrates an implicit neural representation and a denoising diffusion model in a unified end-to-end framework, where the implicit neural representation is adopted in the decoding process to learn continuous-resolution representation. Furthermore, we design a scale-controllable conditioning mechanism that consists of a low-resolution (LR) conditioning network and a scaling factor. The scaling factor regulates the resolution and accordingly modulates the proportion of the LR information and generated features in the final output, which enables the model to accommodate the continuous-resolution requirement. Extensive experiments validate the effectiveness of our IDM and demonstrate its superior performance over prior arts.