 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZONE: Zero-Shot Instruction-Guided Local Editing
Dec 28, 2023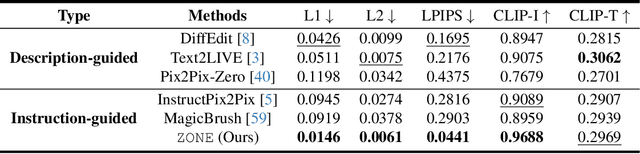
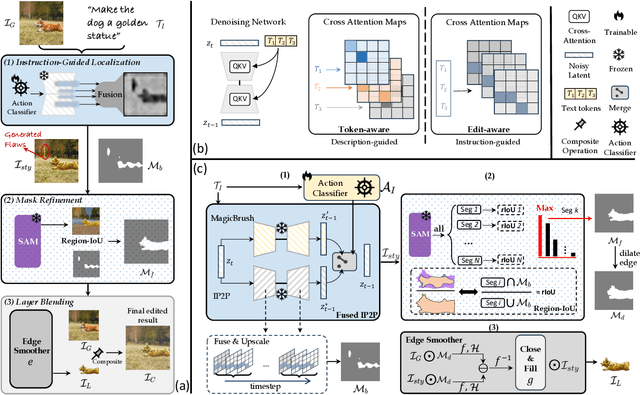
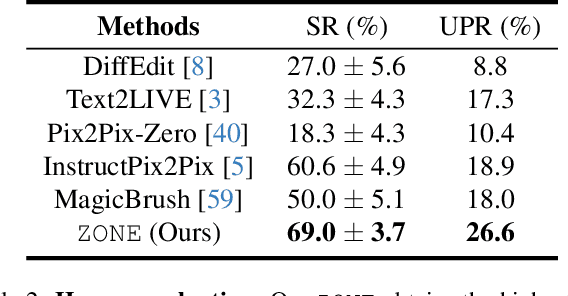
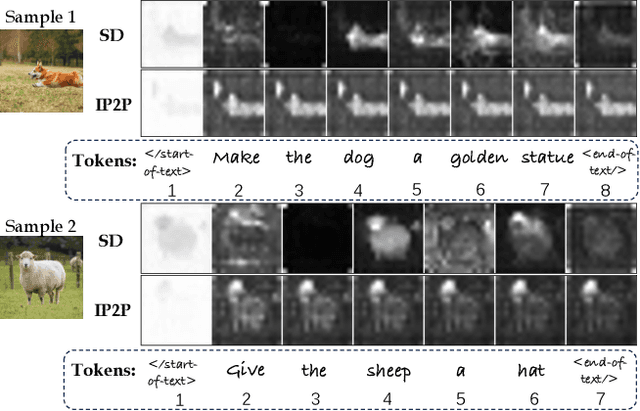
Recent advances in vision-language models like Stable Diffusion have shown remarkable power in creative image synthesis and editing.However, most existing text-to-image editing methods encounter two obstacles: First, the text prompt needs to be carefully crafted to achieve good results, which is not intuitive or user-friendly. Second, they are insensitive to local edits and can irreversibly affect non-edited regions, leaving obvious editing traces. To tackle these problems, we propose a Zero-shot instructiON-guided local image Editing approach, termed ZONE. We first convert the editing intent from the user-provided instruction (e.g., ``make his tie blue") into specific image editing regions through InstructPix2Pix. We then propose a Region-IoU scheme for precise image layer extraction from an off-the-shelf segment model. We further develop an edge smoother based on FFT for seamless blending between the layer and the image.Our method allows for arbitrary manipulation of a specific region with a single instruction while preserving the rest. Extensive experiments demonstrate that our ZONE achieves remarkable local editing results and user-friendliness, outperforming state-of-the-art methods.
IPDreamer: Appearance-Controllable 3D Object Generation with Image Prompts
Oct 09, 2023Recent advances in text-to-3D generation have been remarkable, with methods such as DreamFusion leveraging large-scale text-to-image diffusion-based models to supervise 3D generation. These methods, including the variational score distillation proposed by ProlificDreamer, enable the synthesis of detailed and photorealistic textured meshes. However, the appearance of 3D objects generated by these methods is often random and uncontrollable, posing a challenge in achieving appearance-controllable 3D objects. To address this challenge, we introduce IPDreamer, a novel approach that incorporates image prompts to provide specific and comprehensive appearance information for 3D object generation. Our results demonstrate that IPDreamer effectively generates high-quality 3D objects that are consistent with both the provided text and image prompts, demonstrating its promising capability in appearance-controllable 3D object generation.