 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Pyramid Network for Efficient Multimodal Large Language Model
Mar 26, 2025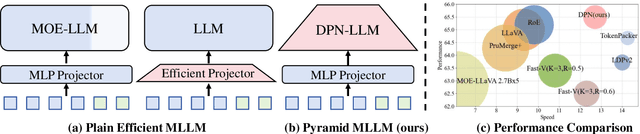

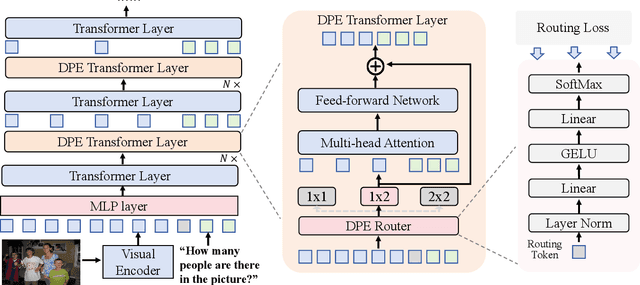

Multimodal large language models (MLLMs) have demonstrated impressive performance in various vision-language (VL) tasks, but their expensive computations still limit the real-world application. To address this issue, recent efforts aim to compress the visual features to save the computational costs of MLLMs. However, direct visual compression methods, e.g. efficient projectors, inevitably destroy the visual semantics in MLLM, especially in difficult samples. To overcome this shortcoming, we propose a novel dynamic pyramid network (DPN) for efficient MLLMs. Specifically, DPN formulates MLLM as a hierarchical structure where visual features are gradually compressed with increasing depth. In this case, even with a high compression ratio, fine-grained visual information can still be perceived in shallow layers. To maximize the benefit of DPN, we further propose an innovative Dynamic Pooling Experts (DPE) that can dynamically choose the optimal visual compression rate according to input features. With this design, harder samples will be assigned larger computations, thus preserving the model performance. To validate our approach, we conduct extensive experiments on two popular MLLMs and ten benchmarks. Experimental results show that DPN can save up to 56% average FLOPs on LLaVA while further achieving +0.74% performance gains. Besides, the generalization ability of DPN is also validated on the existing high-resolution MLLM called LLaVA-HR. Our source codes are anonymously released at https://github.com/aihao2000/DPN-LLaVA.
ShapefileGPT: A Multi-Agent Large Language Model Framework for Automated Shapefile Processing
Oct 16, 2024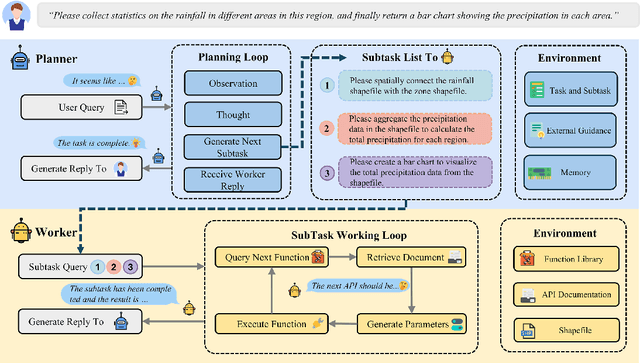


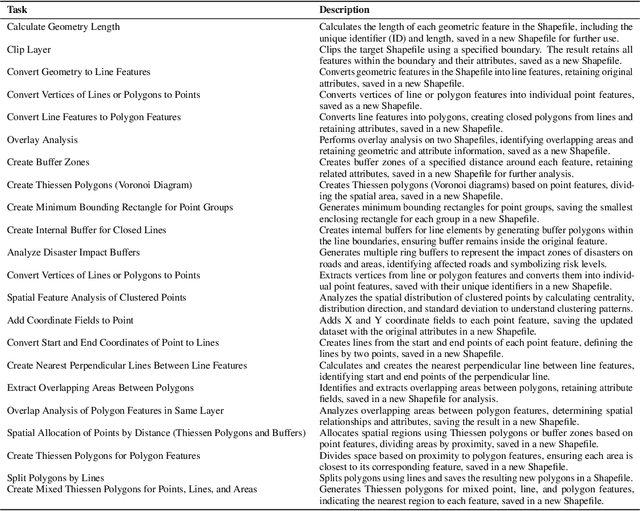
Vector data is one of the two core data structures in geographic information science (GIS), essential for accurately storing and representing geospatial information. Shapefile, the most widely used vector data format, has become the industry standard supported by all major geographic information systems. However, processing this data typically requires specialized GIS knowledge and skills, creating a barrier for researchers from other fields and impeding interdisciplinary research in spatial data analysis. Moreover, while large language models (LLMs) have made significant advancements in natural language processing and task automation, they still face challenges in handling the complex spatial and topological relationships inherent in GIS vector data. To address these challenges, we propose ShapefileGPT, an innovative framework powered by LLMs, specifically designed to automate Shapefile tasks. ShapefileGPT utilizes a multi-agent architecture, in which the planner agent is responsible for task decomposition and supervision, while the worker agent executes the tasks. We developed a specialized function library for handling Shapefiles and provided comprehensive API documentation, enabling the worker agent to operate Shapefiles efficiently through function calling. For evaluation, we developed a benchmark dataset based on authoritative textbooks, encompassing tasks in categories such as geometric operations and spatial queries. ShapefileGPT achieved a task success rate of 95.24%, outperforming the GPT series models. In comparison to traditional LLMs, ShapefileGPT effectively handles complex vector data analysis tasks, overcoming the limitations of traditional LLMs in spatial analysis. This breakthrough opens new pathways for advancing automation and intelligence in the GIS field, with significant potential in interdisciplinary data analysis and application contexts.
ControlCity: A Multimodal Diffusion Model Based Approach for Accurate Geospatial Data Generation and Urban Morphology Analysis
Sep 25, 2024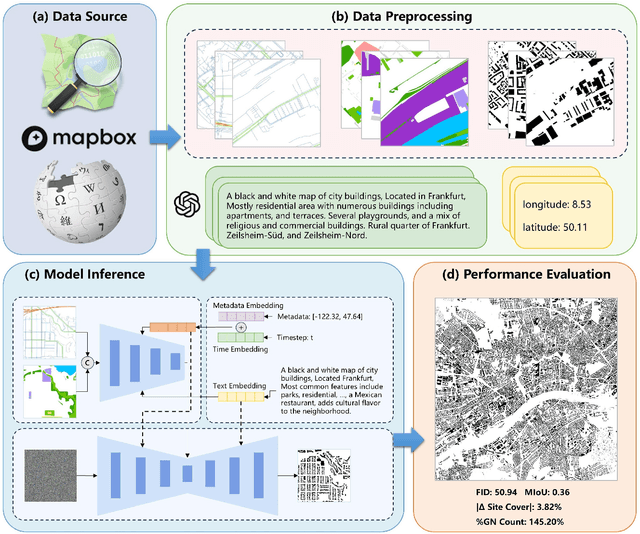
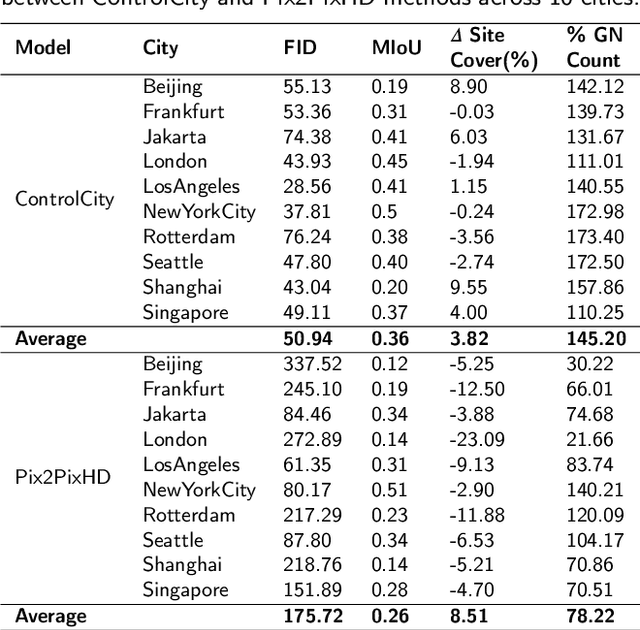

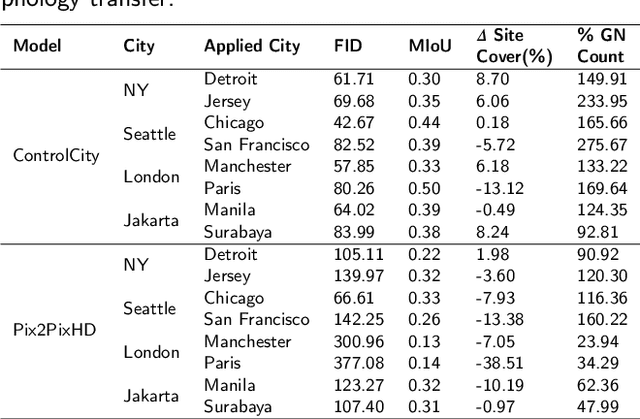
Volunteer Geographic Information (VGI), with its rich variety, large volume, rapid updates, and diverse sources, has become a critical source of geospatial data. However, VGI data from platforms like OSM exhibit significant quality heterogeneity across different data types, particularly with urban building data. To address this, we propose a multi-source geographic data transformation solution, utilizing accessible and complete VGI data to assist in generating urban building footprint data. We also employ a multimodal data generation framework to improve accuracy. First, we introduce a pipeline for constructing an 'image-text-metadata-building footprint' dataset, primarily based on road network data and supplemented by other multimodal data. We then present ControlCity, a geographic data transformation method based on a multimodal diffusion model. This method first uses a pre-trained text-to-image model to align text, metadata, and building footprint data. An improved ControlNet further integrates road network and land-use imagery, producing refined building footprint data. Experiments across 22 global cities demonstrate that ControlCity successfully simulates real urban building patterns, achieving state-of-the-art performance. Specifically, our method achieves an average FID score of 50.94, reducing error by 71.01% compared to leading methods, and a MIoU score of 0.36, an improvement of 38.46%. Additionally, our model excels in tasks like urban morphology transfer, zero-shot city generation, and spatial data completeness assessment. In the zero-shot city task, our method accurately predicts and generates similar urban structures, demonstrating strong generalization. This study confirms the effectiveness of our approach in generating urban building footprint data and capturing complex city characteristics.
Target-Driven Distillation: Consistency Distillation with Target Timestep Selection and Decoupled Guidance
Sep 02, 2024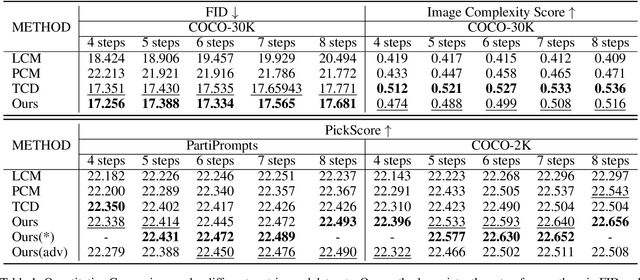
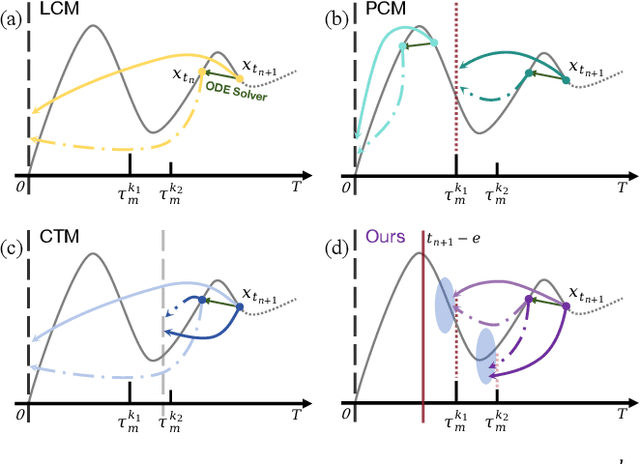
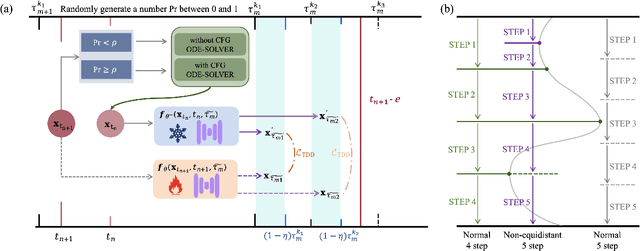

Consistency distillation methods have demonstrated significant success in accelerating generative tasks of diffusion models. However, since previous consistency distillation methods use simple and straightforward strategies in selecting target timesteps, they usually struggle with blurs and detail losses in generated images. To address these limitations, we introduce Target-Driven Distillation (TDD), which (1) adopts a delicate selection strategy of target timesteps, increasing the training efficiency; (2) utilizes decoupled guidances during training, making TDD open to post-tuning on guidance scale during inference periods; (3) can be optionally equipped with non-equidistant sampling and x0 clipping, enabling a more flexible and accurate way for image sampling. Experiments verify that TDD achieves state-of-the-art performance in few-step generation, offering a better choice among consistency distillation models.
GeoFormer: Learning Point Cloud Completion with Tri-Plane Integrated Transformer
Aug 13, 2024



Point cloud completion aims to recover accurate global geometry and preserve fine-grained local details from partial point clouds. Conventional methods typically predict unseen points directly from 3D point cloud coordinates or use self-projected multi-view depth maps to ease this task. However, these gray-scale depth maps cannot reach multi-view consistency, consequently restricting the performance. In this paper, we introduce a GeoFormer that simultaneously enhances the global geometric structure of the points and improves the local details. Specifically, we design a CCM Feature Enhanced Point Generator to integrate image features from multi-view consistent canonical coordinate maps (CCMs) and align them with pure point features, thereby enhancing the global geometry feature. Additionally, we employ the Multi-scale Geometry-aware Upsampler module to progressively enhance local details. This is achieved through cross attention between the multi-scale features extracted from the partial input and the features derived from previously estimated points. Extensive experiments on the PCN, ShapeNet-55/34, and KITTI benchmarks demonstrate that our GeoFormer outperforms recent methods, achieving the state-of-the-art performance. Our code is available at \href{https://github.com/Jinpeng-Yu/GeoFormer}{https://github.com/Jinpeng-Yu/GeoFormer}.
Unified Video-Language Pre-training with Synchronized Audio
May 12, 2024Video-language pre-training is a typical and challenging problem that aims at learning visual and textual representations from large-scale data in a self-supervised way. Existing pre-training approaches either captured the correspondence of image-text pairs or utilized temporal ordering of frames. However, they do not explicitly explore the natural synchronization between audio and the other two modalities. In this work, we propose an enhanced framework for Video-Language pre-training with Synchronized Audio, termed as VLSA, that can learn tri-modal representations in a unified self-supervised transformer. Specifically, our VLSA jointly aggregates embeddings of local patches and global tokens for video, text, and audio. Furthermore, we utilize local-patch masked modeling to learn modality-aware features, and leverage global audio matching to capture audio-guided features for video and text. We conduct extensive experiments on retrieval across text, video, and audio. Our simple model pre-trained on only 0.9M data achieves improving results against state-of-the-art baselines. In addition, qualitative visualizations vividly showcase the superiority of our VLSA in learning discriminative visual-textual representations.
StableGarment: Garment-Centric Generation via Stable Diffusion
Mar 16, 2024



In this paper, we introduce StableGarment, a unified framework to tackle garment-centric(GC) generation tasks, including GC text-to-image, controllable GC text-to-image, stylized GC text-to-image, and robust virtual try-on. The main challenge lies in retaining the intricate textures of the garment while maintaining the flexibility of pre-trained Stable Diffusion. Our solution involves the development of a garment encoder, a trainable copy of the denoising UNet equipped with additive self-attention (ASA) layers. These ASA layers are specifically devised to transfer detailed garment textures, also facilitating the integration of stylized base models for the creation of stylized images. Furthermore, the incorporation of a dedicated try-on ControlNet enables StableGarment to execute virtual try-on tasks with precision. We also build a novel data engine that produces high-quality synthesized data to preserve the model's ability to follow prompts. Extensive experiments demonstrate that our approach delivers state-of-the-art (SOTA) results among existing virtual try-on methods and exhibits high flexibility with broad potential applications in various garment-centric image generation.
Stable-Makeup: When Real-World Makeup Transfer Meets Diffusion Model
Mar 12, 2024Current makeup transfer methods are limited to simple makeup styles, making them difficult to apply in real-world scenarios. In this paper, we introduce Stable-Makeup, a novel diffusion-based makeup transfer method capable of robustly transferring a wide range of real-world makeup, onto user-provided faces. Stable-Makeup is based on a pre-trained diffusion model and utilizes a Detail-Preserving (D-P) makeup encoder to encode makeup details. It also employs content and structural control modules to preserve the content and structural information of the source image. With the aid of our newly added makeup cross-attention layers in U-Net, we can accurately transfer the detailed makeup to the corresponding position in the source image. After content-structure decoupling training, Stable-Makeup can maintain content and the facial structure of the source image. Moreover, our method has demonstrated strong robustness and generalizability, making it applicable to varioustasks such as cross-domain makeup transfer, makeup-guided text-to-image generation and so on. Extensive experiments have demonstrated that our approach delivers state-of-the-art (SOTA) results among existing makeup transfer methods and exhibits a highly promising with broad potential applications in various related fields.
InstantID: Zero-shot Identity-Preserving Generation in Seconds
Feb 02, 2024
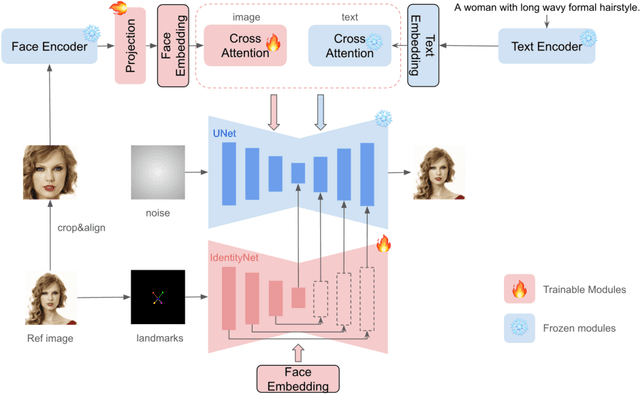


There has been significant progress in personalized image synthesis with methods such as Textual Inversion, DreamBooth, and LoRA. Yet, their real-world applicability is hindered by high storage demands, lengthy fine-tuning processes, and the need for multiple reference images. Conversely, existing ID embedding-based methods, while requiring only a single forward inference, face challenges: they either necessitate extensive fine-tuning across numerous model parameters, lack compatibility with community pre-trained models, or fail to maintain high face fidelity. Addressing these limitations, we introduce InstantID, a powerful diffusion model-based solution. Our plug-and-play module adeptly handles image personalization in various styles using just a single facial image, while ensuring high fidelity. To achieve this, we design a novel IdentityNet by imposing strong semantic and weak spatial conditions, integrating facial and landmark images with textual prompts to steer the image generation. InstantID demonstrates exceptional performance and efficiency, proving highly beneficial in real-world applications where identity preservation is paramount. Moreover, our work seamlessly integrates with popular pre-trained text-to-image diffusion models like SD1.5 and SDXL, serving as an adaptable plugin. Our codes and pre-trained checkpoints will be available at https://github.com/InstantID/InstantID.
SSR-Encoder: Encoding Selective Subject Representation for Subject-Driven Generation
Dec 26, 2023



Recent advancements in subject-driven image generation have led to zero-shot generation, yet precise selection and focus on crucial subject representations remain challenging. Addressing this, we introduce the SSR-Encoder, a novel architecture designed for selectively capturing any subject from single or multiple reference images. It responds to various query modalities including text and masks, without necessitating test-time fine-tuning. The SSR-Encoder combines a Token-to-Patch Aligner that aligns query inputs with image patches and a Detail-Preserving Subject Encoder for extracting and preserving fine features of the subjects, thereby generating subject embeddings. These embeddings, used in conjunction with original text embeddings, condition the generation process. Characterized by its model generalizability and efficiency, the SSR-Encoder adapts to a range of custom models and control modules. Enhanced by the Embedding Consistency Regularization Loss for improved training, our extensive experiments demonstrate its effectiveness in versatile and high-quality image generation, indicating its broad applicability. Project page: https://ssr-encoder.github.io