 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiMo-V2-Flash Technical Report
Jan 08, 2026We present MiMo-V2-Flash, a Mixture-of-Experts (MoE) model with 309B total parameters and 15B active parameters, designed for fast, strong reasoning and agentic capabilities. MiMo-V2-Flash adopts a hybrid attention architecture that interleaves Sliding Window Attention (SWA) with global attention, with a 128-token sliding window under a 5:1 hybrid ratio. The model is pre-trained on 27 trillion tokens with Multi-Token Prediction (MTP), employing a native 32k context length and subsequently extended to 256k. To efficiently scale post-training compute, MiMo-V2-Flash introduces a novel Multi-Teacher On-Policy Distillation (MOPD) paradigm. In this framework, domain-specialized teachers (e.g., trained via large-scale reinforcement learning) provide dense and token-level reward, enabling the student model to perfectly master teacher expertise. MiMo-V2-Flash rivals top-tier open-weight models such as DeepSeek-V3.2 and Kimi-K2, despite using only 1/2 and 1/3 of their total parameters, respectively. During inference, by repurposing MTP as a draft model for speculative decoding, MiMo-V2-Flash achieves up to 3.6 acceptance length and 2.6x decoding speedup with three MTP layers. We open-source both the model weights and the three-layer MTP weights to foster open research and community collaboration.
MiMo-Audio: Audio Language Models are Few-Shot Learners
Dec 29, 2025Existing audio language models typically rely on task-specific fine-tuning to accomplish particular audio tasks. In contrast, humans are able to generalize to new audio tasks with only a few examples or simple instructions. GPT-3 has shown that scaling next-token prediction pretraining enables strong generalization capabilities in text, and we believe this paradigm is equally applicable to the audio domain. By scaling MiMo-Audio's pretraining data to over one hundred million of hours, we observe the emergence of few-shot learning capabilities across a diverse set of audio tasks. We develop a systematic evaluation of these capabilities and find that MiMo-Audio-7B-Base achieves SOTA performance on both speech intelligence and audio understanding benchmarks among open-source models. Beyond standard metrics, MiMo-Audio-7B-Base generalizes to tasks absent from its training data, such as voice conversion, style transfer, and speech editing. MiMo-Audio-7B-Base also demonstrates powerful speech continuation capabilities, capable of generating highly realistic talk shows, recitations, livestreaming and debates. At the post-training stage, we curate a diverse instruction-tuning corpus and introduce thinking mechanisms into both audio understanding and generation. MiMo-Audio-7B-Instruct achieves open-source SOTA on audio understanding benchmarks (MMSU, MMAU, MMAR, MMAU-Pro), spoken dialogue benchmarks (Big Bench Audio, MultiChallenge Audio) and instruct-TTS evaluations, approaching or surpassing closed-source models. Model checkpoints and full evaluation suite are available at https://github.com/XiaomiMiMo/MiMo-Audio.
Framework, Standards, Applications and Best practices of Responsible AI : A Comprehensive Survey
Apr 18, 2025



Responsible Artificial Intelligence (RAI) is a combination of ethics associated with the usage of artificial intelligence aligned with the common and standard frameworks. This survey paper extensively discusses the global and national standards, applications of RAI, current technology and ongoing projects using RAI, and possible challenges in implementing and designing RAI in the industries and projects based on AI. Currently, ethical standards and implementation of RAI are decoupled which caters each industry to follow their own standards to use AI ethically. Many global firms and government organizations are taking necessary initiatives to design a common and standard framework. Social pressure and unethical way of using AI forces the RAI design rather than implementation.
CoMBO: Conflict Mitigation via Branched Optimization for Class Incremental Segmentation
Apr 05, 2025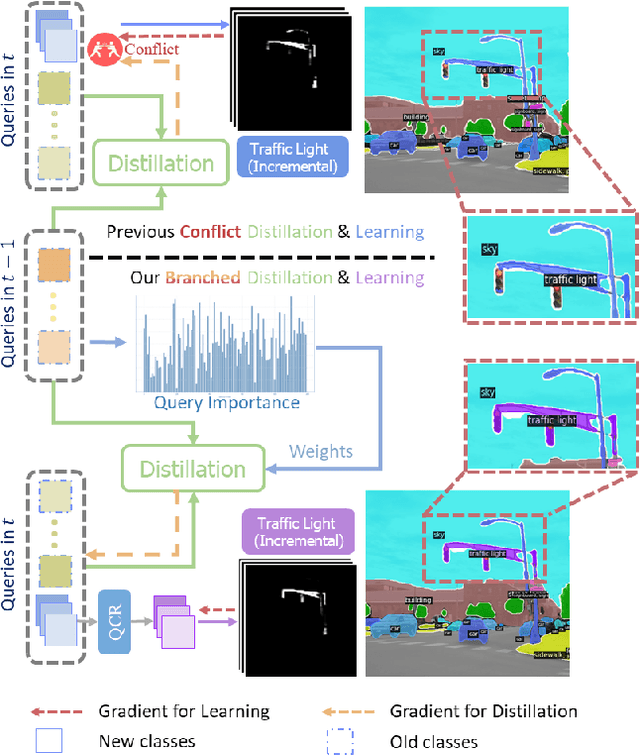
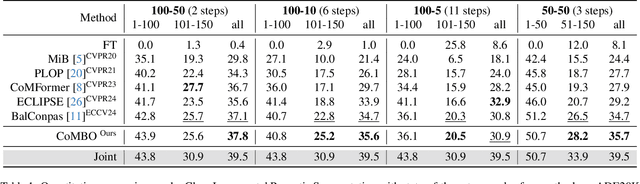
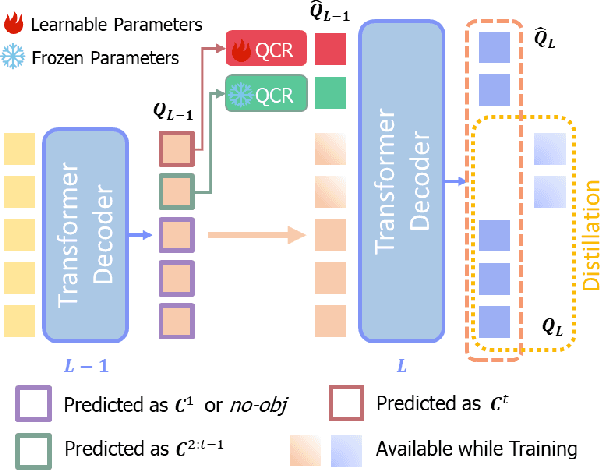
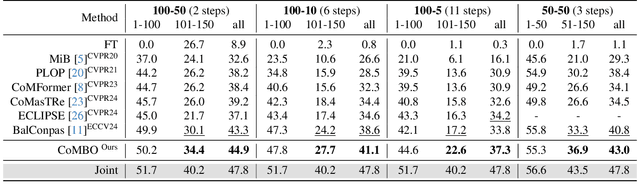
Effective Class Incremental Segmentation (CIS) requires simultaneously mitigating catastrophic forgetting and ensuring sufficient plasticity to integrate new classes. The inherent conflict above often leads to a back-and-forth, which turns the objective into finding the balance between the performance of previous~(old) and incremental~(new) classes. To address this conflict, we introduce a novel approach, Conflict Mitigation via Branched Optimization~(CoMBO). Within this approach, we present the Query Conflict Reduction module, designed to explicitly refine queries for new classes through lightweight, class-specific adapters. This module provides an additional branch for the acquisition of new classes while preserving the original queries for distillation. Moreover, we develop two strategies to further mitigate the conflict following the branched structure, \textit{i.e.}, the Half-Learning Half-Distillation~(HDHL) over classification probabilities, and the Importance-Based Knowledge Distillation~(IKD) over query features. HDHL selectively engages in learning for classification probabilities of queries that match the ground truth of new classes, while aligning unmatched ones to the corresponding old probabilities, thus ensuring retention of old knowledge while absorbing new classes via learning negative samples. Meanwhile, IKD assesses the importance of queries based on their matching degree to old classes, prioritizing the distillation of important features and allowing less critical features to evolve. Extensive experiments in Class Incremental Panoptic and Semantic Segmentation settings have demonstrated the superior performance of CoMBO. Project page: https://guangyu-ryan.github.io/CoMBO.
MoCFL: Mobile Cluster Federated Learning Framework for Highly Dynamic Network
Mar 03, 2025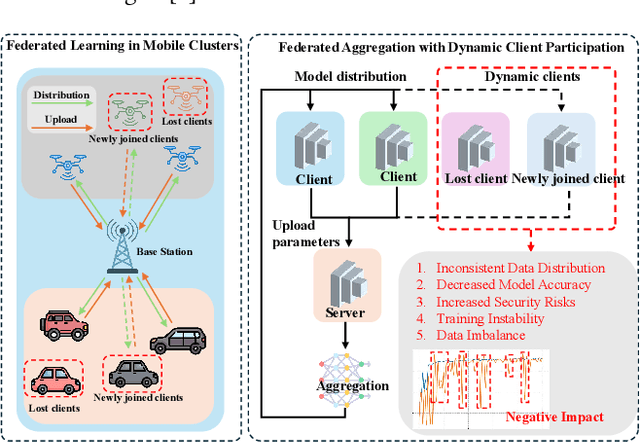
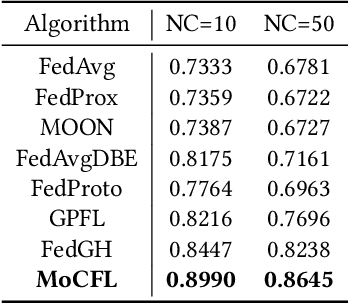
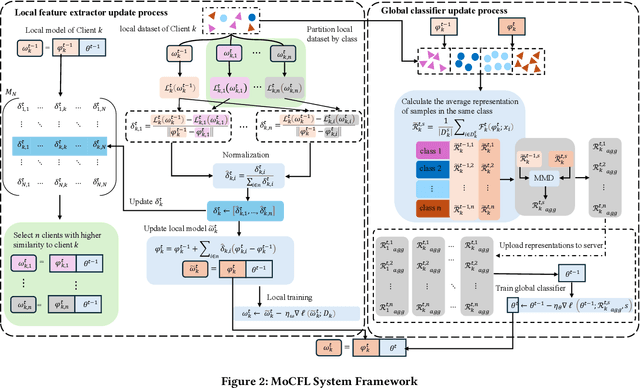
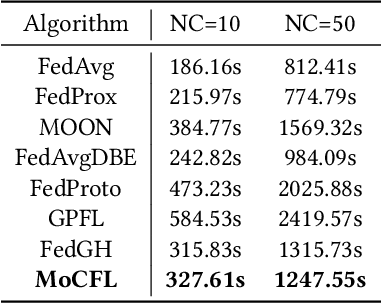
Frequent fluctuations of client nodes in highly dynamic mobile clusters can lead to significant changes in feature space distribution and data drift, posing substantial challenges to the robustness of existing federated learning (FL) strategies. To address these issues, we proposed a mobile cluster federated learning framework (MoCFL). MoCFL enhances feature aggregation by introducing an affinity matrix that quantifies the similarity between local feature extractors from different clients, addressing dynamic data distribution changes caused by frequent client churn and topology changes. Additionally, MoCFL integrates historical and current feature information when training the global classifier, effectively mitigating the catastrophic forgetting problem frequently encountered in mobile scenarios. This synergistic combination ensures that MoCFL maintains high performance and stability in dynamically changing mobile environments. Experimental results on the UNSW-NB15 dataset show that MoCFL excels in dynamic environments, demonstrating superior robustness and accuracy while maintaining reasonable training costs.
ShapefileGPT: A Multi-Agent Large Language Model Framework for Automated Shapefile Processing
Oct 16, 2024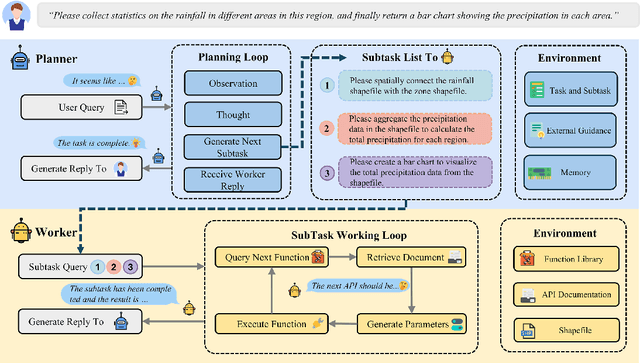


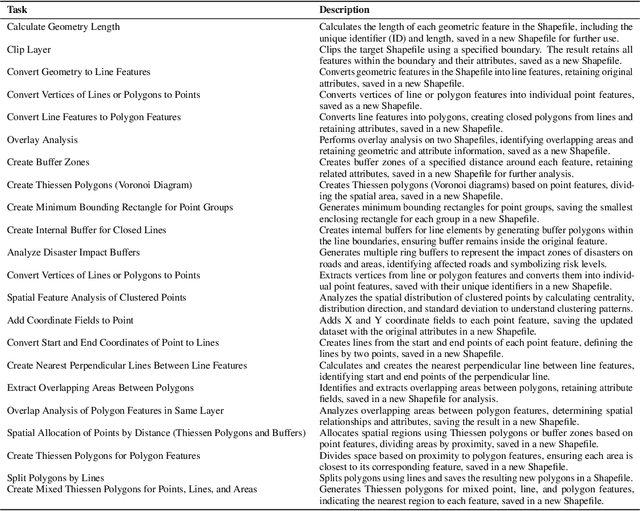
Vector data is one of the two core data structures in geographic information science (GIS), essential for accurately storing and representing geospatial information. Shapefile, the most widely used vector data format, has become the industry standard supported by all major geographic information systems. However, processing this data typically requires specialized GIS knowledge and skills, creating a barrier for researchers from other fields and impeding interdisciplinary research in spatial data analysis. Moreover, while large language models (LLMs) have made significant advancements in natural language processing and task automation, they still face challenges in handling the complex spatial and topological relationships inherent in GIS vector data. To address these challenges, we propose ShapefileGPT, an innovative framework powered by LLMs, specifically designed to automate Shapefile tasks. ShapefileGPT utilizes a multi-agent architecture, in which the planner agent is responsible for task decomposition and supervision, while the worker agent executes the tasks. We developed a specialized function library for handling Shapefiles and provided comprehensive API documentation, enabling the worker agent to operate Shapefiles efficiently through function calling. For evaluation, we developed a benchmark dataset based on authoritative textbooks, encompassing tasks in categories such as geometric operations and spatial queries. ShapefileGPT achieved a task success rate of 95.24%, outperforming the GPT series models. In comparison to traditional LLMs, ShapefileGPT effectively handles complex vector data analysis tasks, overcoming the limitations of traditional LLMs in spatial analysis. This breakthrough opens new pathways for advancing automation and intelligence in the GIS field, with significant potential in interdisciplinary data analysis and application contexts.
BianQue: Balancing the Questioning and Suggestion Ability of Health LLMs with Multi-turn Health Conversations Polished by ChatGPT
Oct 24, 2023Large language models (LLMs) have performed well in providing general and extensive health suggestions in single-turn conversations, exemplified by systems such as ChatGPT, ChatGLM, ChatDoctor, DoctorGLM, and etc. However, the limited information provided by users during single turn results in inadequate personalization and targeting of the generated suggestions, which requires users to independently select the useful part. It is mainly caused by the missing ability to engage in multi-turn questioning. In real-world medical consultations, doctors usually employ a series of iterative inquiries to comprehend the patient's condition thoroughly, enabling them to provide effective and personalized suggestions subsequently, which can be defined as chain of questioning (CoQ) for LLMs. To improve the CoQ of LLMs, we propose BianQue, a ChatGLM-based LLM finetuned with the self-constructed health conversation dataset BianQueCorpus that is consist of multiple turns of questioning and health suggestions polished by ChatGPT. Experimental results demonstrate that the proposed BianQue can simultaneously balance the capabilities of both questioning and health suggestions, which will help promote the research and application of LLMs in the field of proactive health.