 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFramework, Standards, Applications and Best practices of Responsible AI : A Comprehensive Survey
Apr 18, 2025



Responsible Artificial Intelligence (RAI) is a combination of ethics associated with the usage of artificial intelligence aligned with the common and standard frameworks. This survey paper extensively discusses the global and national standards, applications of RAI, current technology and ongoing projects using RAI, and possible challenges in implementing and designing RAI in the industries and projects based on AI. Currently, ethical standards and implementation of RAI are decoupled which caters each industry to follow their own standards to use AI ethically. Many global firms and government organizations are taking necessary initiatives to design a common and standard framework. Social pressure and unethical way of using AI forces the RAI design rather than implementation.
MoCFL: Mobile Cluster Federated Learning Framework for Highly Dynamic Network
Mar 03, 2025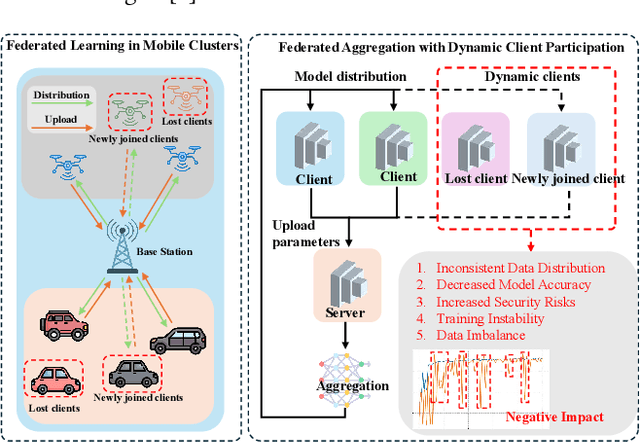
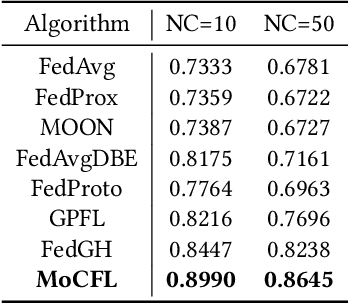
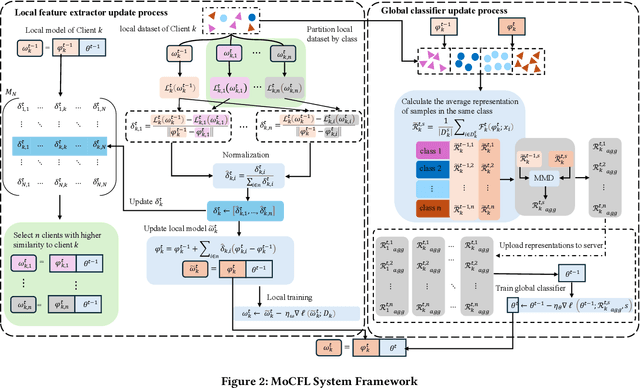
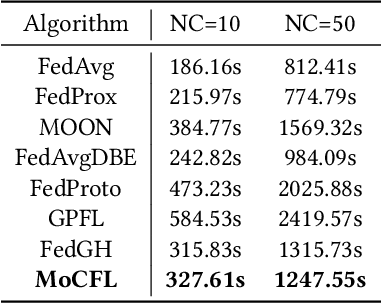
Frequent fluctuations of client nodes in highly dynamic mobile clusters can lead to significant changes in feature space distribution and data drift, posing substantial challenges to the robustness of existing federated learning (FL) strategies. To address these issues, we proposed a mobile cluster federated learning framework (MoCFL). MoCFL enhances feature aggregation by introducing an affinity matrix that quantifies the similarity between local feature extractors from different clients, addressing dynamic data distribution changes caused by frequent client churn and topology changes. Additionally, MoCFL integrates historical and current feature information when training the global classifier, effectively mitigating the catastrophic forgetting problem frequently encountered in mobile scenarios. This synergistic combination ensures that MoCFL maintains high performance and stability in dynamically changing mobile environments. Experimental results on the UNSW-NB15 dataset show that MoCFL excels in dynamic environments, demonstrating superior robustness and accuracy while maintaining reasonable training costs.
ShapefileGPT: A Multi-Agent Large Language Model Framework for Automated Shapefile Processing
Oct 16, 2024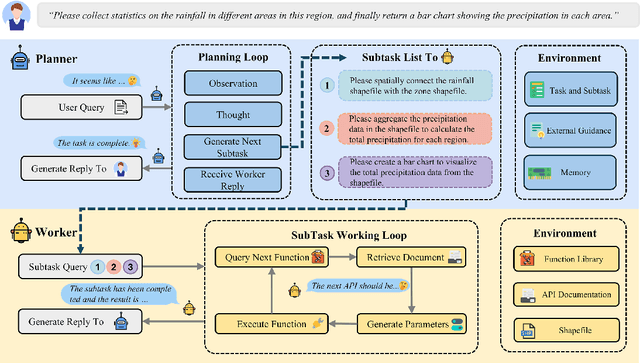


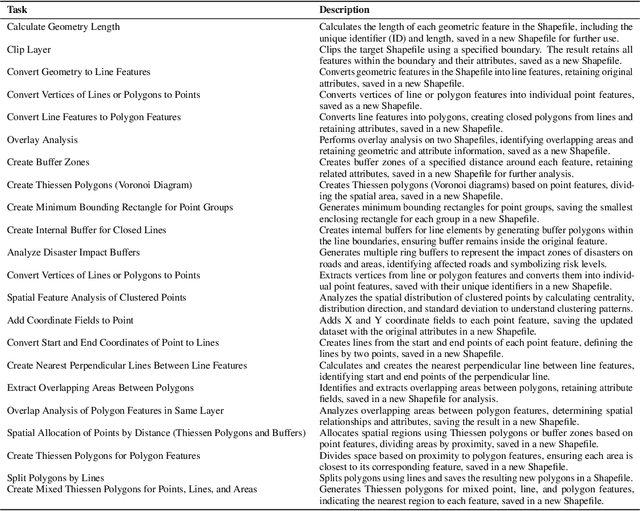
Vector data is one of the two core data structures in geographic information science (GIS), essential for accurately storing and representing geospatial information. Shapefile, the most widely used vector data format, has become the industry standard supported by all major geographic information systems. However, processing this data typically requires specialized GIS knowledge and skills, creating a barrier for researchers from other fields and impeding interdisciplinary research in spatial data analysis. Moreover, while large language models (LLMs) have made significant advancements in natural language processing and task automation, they still face challenges in handling the complex spatial and topological relationships inherent in GIS vector data. To address these challenges, we propose ShapefileGPT, an innovative framework powered by LLMs, specifically designed to automate Shapefile tasks. ShapefileGPT utilizes a multi-agent architecture, in which the planner agent is responsible for task decomposition and supervision, while the worker agent executes the tasks. We developed a specialized function library for handling Shapefiles and provided comprehensive API documentation, enabling the worker agent to operate Shapefiles efficiently through function calling. For evaluation, we developed a benchmark dataset based on authoritative textbooks, encompassing tasks in categories such as geometric operations and spatial queries. ShapefileGPT achieved a task success rate of 95.24%, outperforming the GPT series models. In comparison to traditional LLMs, ShapefileGPT effectively handles complex vector data analysis tasks, overcoming the limitations of traditional LLMs in spatial analysis. This breakthrough opens new pathways for advancing automation and intelligence in the GIS field, with significant potential in interdisciplinary data analysis and application contexts.
ControlCity: A Multimodal Diffusion Model Based Approach for Accurate Geospatial Data Generation and Urban Morphology Analysis
Sep 25, 2024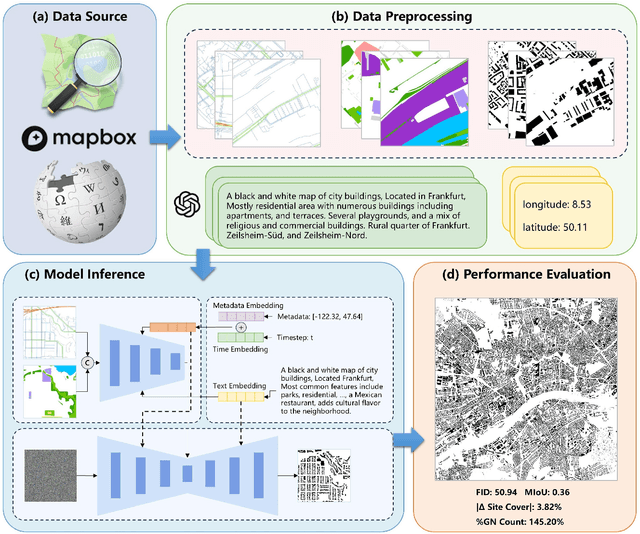
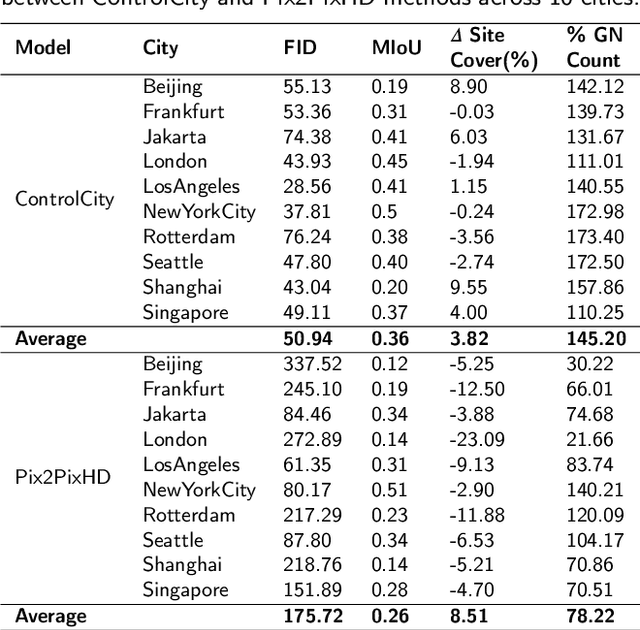

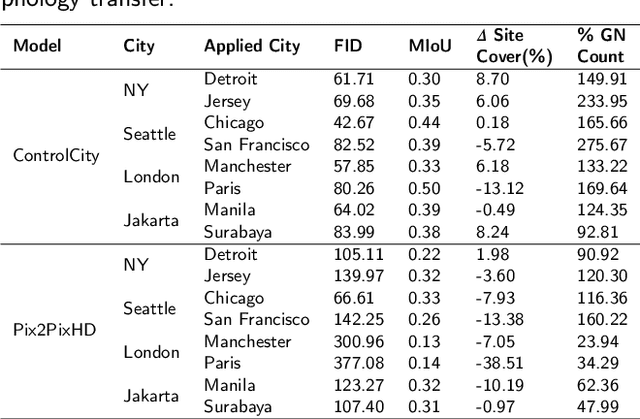
Volunteer Geographic Information (VGI), with its rich variety, large volume, rapid updates, and diverse sources, has become a critical source of geospatial data. However, VGI data from platforms like OSM exhibit significant quality heterogeneity across different data types, particularly with urban building data. To address this, we propose a multi-source geographic data transformation solution, utilizing accessible and complete VGI data to assist in generating urban building footprint data. We also employ a multimodal data generation framework to improve accuracy. First, we introduce a pipeline for constructing an 'image-text-metadata-building footprint' dataset, primarily based on road network data and supplemented by other multimodal data. We then present ControlCity, a geographic data transformation method based on a multimodal diffusion model. This method first uses a pre-trained text-to-image model to align text, metadata, and building footprint data. An improved ControlNet further integrates road network and land-use imagery, producing refined building footprint data. Experiments across 22 global cities demonstrate that ControlCity successfully simulates real urban building patterns, achieving state-of-the-art performance. Specifically, our method achieves an average FID score of 50.94, reducing error by 71.01% compared to leading methods, and a MIoU score of 0.36, an improvement of 38.46%. Additionally, our model excels in tasks like urban morphology transfer, zero-shot city generation, and spatial data completeness assessment. In the zero-shot city task, our method accurately predicts and generates similar urban structures, demonstrating strong generalization. This study confirms the effectiveness of our approach in generating urban building footprint data and capturing complex city characteristics.
TiM4Rec: An Efficient Sequential Recommendation Model Based on Time-Aware Structured State Space Duality Model
Sep 24, 2024
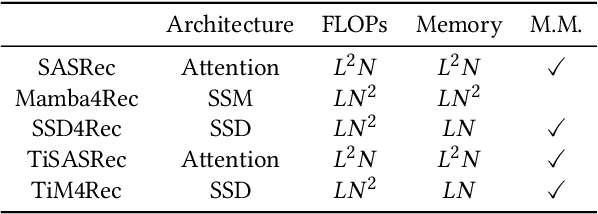
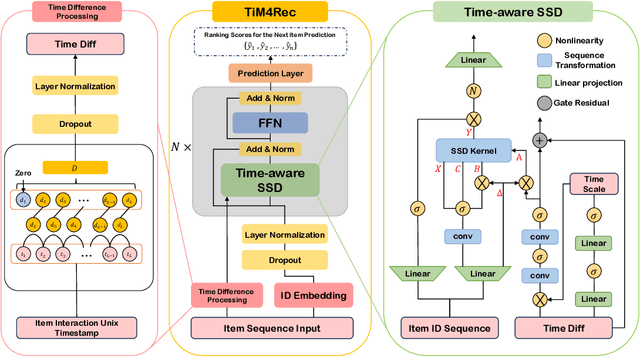
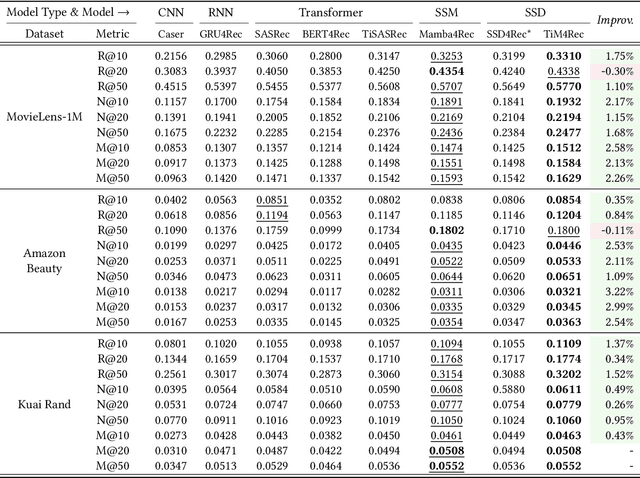
Sequential recommendation represents a pivotal branch of recommendation systems, centered around dynamically analyzing the sequential dependencies between user preferences and their interactive behaviors. Despite the Transformer architecture-based models achieving commendable performance within this domain, their quadratic computational complexity relative to the sequence dimension impedes efficient modeling. In response, the innovative Mamba architecture, characterized by linear computational complexity, has emerged. Mamba4Rec further pioneers the application of Mamba in sequential recommendation. Nonetheless, Mamba 1's hardware-aware algorithm struggles to efficiently leverage modern matrix computational units, which lead to the proposal of the improved State Space Duality (SSD), also known as Mamba 2. While the SSD4Rec successfully adapts the SSD architecture for sequential recommendation, showing promising results in high-dimensional contexts, it suffers significant performance drops in low-dimensional scenarios crucial for pure ID sequential recommendation tasks. Addressing this challenge, we propose a novel sequential recommendation backbone model, TiM4Rec, which ameliorates the low-dimensional performance loss of the SSD architecture while preserving its computational efficiency. Drawing inspiration from TiSASRec, we develop a time-aware enhancement method tailored for the linear computation demands of the SSD architecture, thereby enhancing its adaptability and achieving state-of-the-art (SOTA) performance in both low and high-dimensional modeling. The code for our model is publicly accessible at https://github.com/AlwaysFHao/TiM4Rec.
Evaluating Large Language Models on Spatial Tasks: A Multi-Task Benchmarking Study
Aug 26, 2024
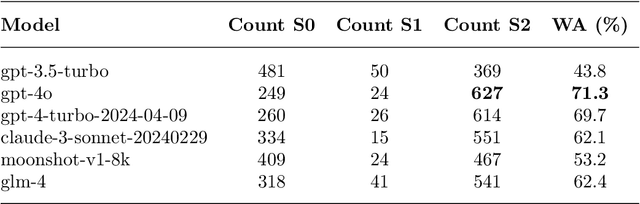
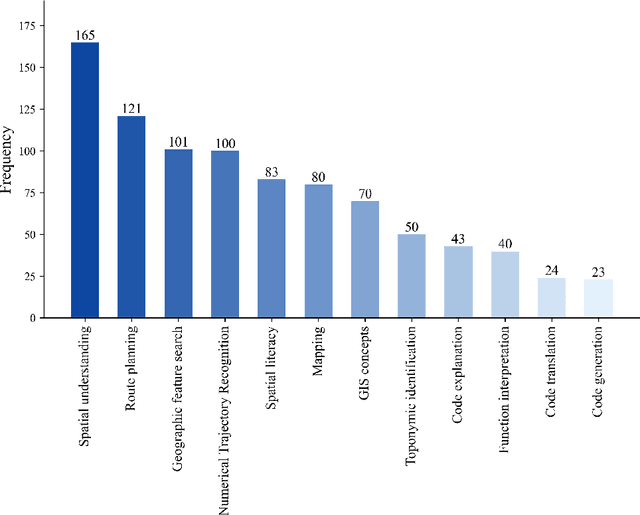
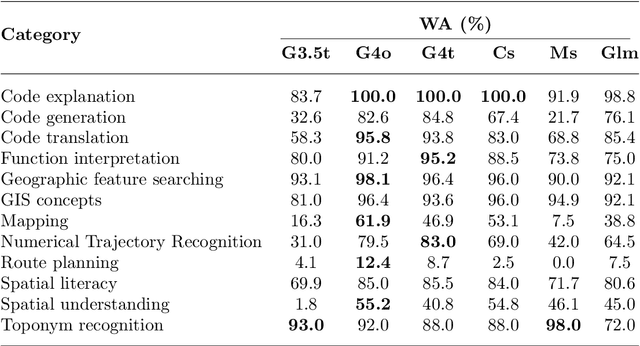
The advent of large language models such as ChatGPT, Gemini, and others has underscored the importance of evaluating their diverse capabilities, ranging from natural language understanding to code generation. However, their performance on spatial tasks has not been comprehensively assessed. This study addresses this gap by introducing a novel multi-task spatial evaluation dataset, designed to systematically explore and compare the performance of several advanced models on spatial tasks. The dataset encompasses twelve distinct task types, including spatial understanding and path planning, each with verified, accurate answers. We evaluated multiple models, including OpenAI's gpt-3.5-turbo, gpt-4o, and ZhipuAI's glm-4, through a two-phase testing approach. Initially, we conducted zero-shot testing, followed by categorizing the dataset by difficulty and performing prompt tuning tests. Results indicate that gpt-4o achieved the highest overall accuracy in the first phase, with an average of 71.3%. Although moonshot-v1-8k slightly underperformed overall, it surpassed gpt-4o in place name recognition tasks. The study also highlights the impact of prompt strategies on model performance in specific tasks. For example, the Chain-of-Thought (COT) strategy increased gpt-4o's accuracy in path planning from 12.4% to 87.5%, while a one-shot strategy enhanced moonshot-v1-8k's accuracy in mapping tasks from 10.1% to 76.3%.
Multitask Non-Autoregressive Model for Human Motion Prediction
Jul 13, 2020

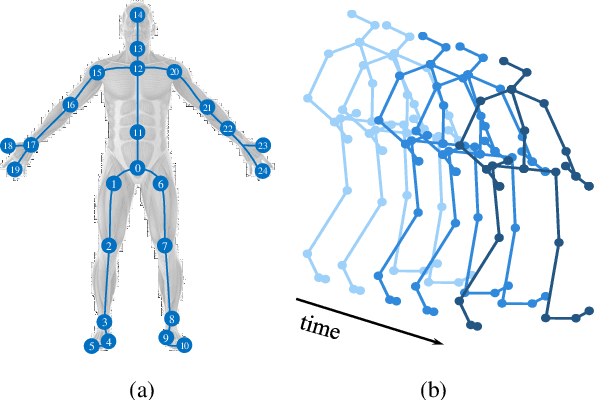
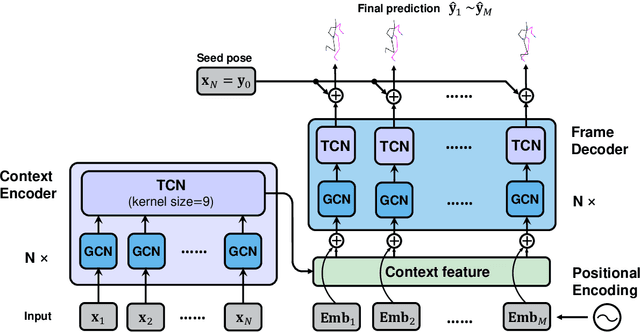
Human motion prediction, which aims at predicting future human skeletons given the past ones, is a typical sequence-to-sequence problem. Therefore, extensive efforts have been continued on exploring different RNN-based encoder-decoder architectures. However, by generating target poses conditioned on the previously generated ones, these models are prone to bringing issues such as error accumulation problem. In this paper, we argue that such issue is mainly caused by adopting autoregressive manner. Hence, a novel Non-auToregressive Model (NAT) is proposed with a complete non-autoregressive decoding scheme, as well as a context encoder and a positional encoding module. More specifically, the context encoder embeds the given poses from temporal and spatial perspectives. The frame decoder is responsible for predicting each future pose independently. The positional encoding module injects positional signal into the model to indicate temporal order. Moreover, a multitask training paradigm is presented for both low-level human skeleton prediction and high-level human action recognition, resulting in the convincing improvement for the prediction task. Our approach is evaluated on Human3.6M and CMU-Mocap benchmarks and outperforms state-of-the-art autoregressive methods.