 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDigital Skin, Digital Bias: Uncovering Tone-Based Biases in LLMs and Emoji Embeddings
Apr 08, 2026Skin-toned emojis are crucial for fostering personal identity and social inclusion in online communication. As AI models, particularly Large Language Models (LLMs), increasingly mediate interactions on web platforms, the risk that these systems perpetuate societal biases through their representation of such symbols is a significant concern. This paper presents the first large-scale comparative study of bias in skin-toned emoji representations across two distinct model classes. We systematically evaluate dedicated emoji embedding models (emoji2vec, emoji-sw2v) against four modern LLMs (Llama, Gemma, Qwen, and Mistral). Our analysis first reveals a critical performance gap: while LLMs demonstrate robust support for skin tone modifiers, widely-used specialized emoji models exhibit severe deficiencies. More importantly, a multi-faceted investigation into semantic consistency, representational similarity, sentiment polarity, and core biases uncovers systemic disparities. We find evidence of skewed sentiment and inconsistent meanings associated with emojis across different skin tones, highlighting latent biases within these foundational models. Our findings underscore the urgent need for developers and platforms to audit and mitigate these representational harms, ensuring that AI's role on the web promotes genuine equity rather than reinforcing societal biases.
Earth Embeddings Reveal Diverse Urban Signals from Space
Apr 03, 2026Conventional urban indicators derived from censuses, surveys, and administrative records are often costly, spatially inconsistent, and slow to update. Recent geospatial foundation models enable Earth embeddings, compact satellite image representations transferable across downstream tasks, but their utility for neighborhood-scale urban monitoring remains unclear. Here, we benchmark three Earth embedding families, AlphaEarth, Prithvi, and Clay, for urban signal prediction across six U.S. metropolitan areas from 2020 to 2023. Using a unified supervised-learning framework, we predict 14 neighborhood-level indicators spanning crime, income, health, and travel behavior, and evaluate performance under four settings: global, city-wise, year-wise, and city-year. Results show that Earth embeddings capture substantial urban variation, with the highest predictive skill for outcomes more directly tied to built-environment structure, including chronic health burdens and dominant commuting modes. By contrast, indicators shaped more strongly by fine-scale behavior and local policy, such as cycling, remain difficult to infer. Predictive performance varies markedly across cities but remains comparatively stable across years, indicating strong spatial heterogeneity alongside temporal robustness. Exploratory analysis suggests that cross-city variation in predictive performance is associated with urban form in task-specific ways. Controlled dimensionality experiments show that representation efficiency is critical: compact 64-dimensional AlphaEarth embeddings remain more informative than 64-dimensional reductions of Prithvi and Clay. This study establishes a benchmark for evaluating Earth embeddings in urban remote sensing and demonstrates their potential as scalable, low-cost features for SDG-aligned neighborhood-scale urban monitoring.
Beta Distribution Learning for Reliable Roadway Crash Risk Assessment
Nov 07, 2025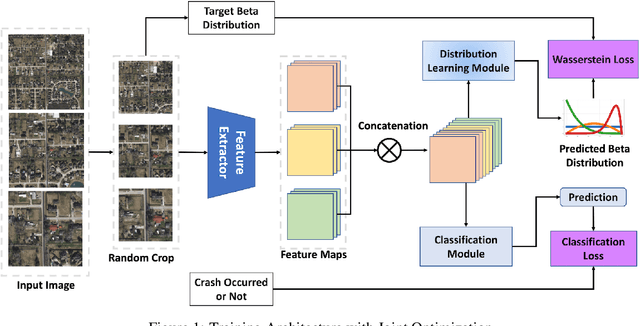

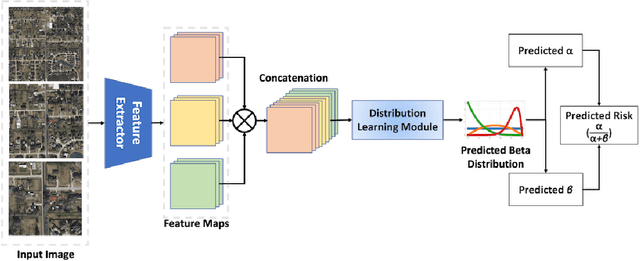

Roadway traffic accidents represent a global health crisis, responsible for over a million deaths annually and costing many countries up to 3% of their GDP. Traditional traffic safety studies often examine risk factors in isolation, overlooking the spatial complexity and contextual interactions inherent in the built environment. Furthermore, conventional Neural Network-based risk estimators typically generate point estimates without conveying model uncertainty, limiting their utility in critical decision-making. To address these shortcomings, we introduce a novel geospatial deep learning framework that leverages satellite imagery as a comprehensive spatial input. This approach enables the model to capture the nuanced spatial patterns and embedded environmental risk factors that contribute to fatal crash risks. Rather than producing a single deterministic output, our model estimates a full Beta probability distribution over fatal crash risk, yielding accurate and uncertainty-aware predictions--a critical feature for trustworthy AI in safety-critical applications. Our model outperforms baselines by achieving a 17-23% improvement in recall, a key metric for flagging potential dangers, while delivering superior calibration. By providing reliable and interpretable risk assessments from satellite imagery alone, our method enables safer autonomous navigation and offers a highly scalable tool for urban planners and policymakers to enhance roadway safety equitably and cost-effectively.
UQGNN: Uncertainty Quantification of Graph Neural Networks for Multivariate Spatiotemporal Prediction
Aug 12, 2025



Spatiotemporal prediction plays a critical role in numerous real-world applications such as urban planning, transportation optimization, disaster response, and pandemic control. In recent years, researchers have made significant progress by developing advanced deep learning models for spatiotemporal prediction. However, most existing models are deterministic, i.e., predicting only the expected mean values without quantifying uncertainty, leading to potentially unreliable and inaccurate outcomes. While recent studies have introduced probabilistic models to quantify uncertainty, they typically focus on a single phenomenon (e.g., taxi, bike, crime, or traffic crashes), thereby neglecting the inherent correlations among heterogeneous urban phenomena. To address the research gap, we propose a novel Graph Neural Network with Uncertainty Quantification, termed UQGNN for multivariate spatiotemporal prediction. UQGNN introduces two key innovations: (i) an Interaction-aware Spatiotemporal Embedding Module that integrates a multivariate diffusion graph convolutional network and an interaction-aware temporal convolutional network to effectively capture complex spatial and temporal interaction patterns, and (ii) a multivariate probabilistic prediction module designed to estimate both expected mean values and associated uncertainties. Extensive experiments on four real-world multivariate spatiotemporal datasets from Shenzhen, New York City, and Chicago demonstrate that UQGNN consistently outperforms state-of-the-art baselines in both prediction accuracy and uncertainty quantification. For example, on the Shenzhen dataset, UQGNN achieves a 5% improvement in both prediction accuracy and uncertainty quantification.
Tales of the 2025 Los Angeles Fire: Hotwash for Public Health Concerns in Reddit via LLM-Enhanced Topic Modeling
May 14, 2025Wildfires have become increasingly frequent, irregular, and severe in recent years. Understanding how affected populations perceive and respond during wildfire crises is critical for timely and empathetic disaster response. Social media platforms offer a crowd-sourced channel to capture evolving public discourse, providing hyperlocal information and insight into public sentiment. This study analyzes Reddit discourse during the 2025 Los Angeles wildfires, spanning from the onset of the disaster to full containment. We collect 385 posts and 114,879 comments related to the Palisades and Eaton fires. We adopt topic modeling methods to identify the latent topics, enhanced by large language models (LLMs) and human-in-the-loop (HITL) refinement. Furthermore, we develop a hierarchical framework to categorize latent topics, consisting of two main categories, Situational Awareness (SA) and Crisis Narratives (CN). The volume of SA category closely aligns with real-world fire progressions, peaking within the first 2-5 days as the fires reach the maximum extent. The most frequent co-occurring category set of public health and safety, loss and damage, and emergency resources expands on a wide range of health-related latent topics, including environmental health, occupational health, and one health. Grief signals and mental health risks consistently accounted for 60 percentage and 40 percentage of CN instances, respectively, with the highest total volume occurring at night. This study contributes the first annotated social media dataset on the 2025 LA fires, and introduces a scalable multi-layer framework that leverages topic modeling for crisis discourse analysis. By identifying persistent public health concerns, our results can inform more empathetic and adaptive strategies for disaster response, public health communication, and future research in comparable climate-related disaster events.
Generative AI for Autonomous Driving: Frontiers and Opportunities
May 13, 2025Generative Artificial Intelligence (GenAI) constitutes a transformative technological wave that reconfigures industries through its unparalleled capabilities for content creation, reasoning, planning, and multimodal understanding. This revolutionary force offers the most promising path yet toward solving one of engineering's grandest challenges: achieving reliable, fully autonomous driving, particularly the pursuit of Level 5 autonomy. This survey delivers a comprehensive and critical synthesis of the emerging role of GenAI across the autonomous driving stack. We begin by distilling the principles and trade-offs of modern generative modeling, encompassing VAEs, GANs, Diffusion Models, and Large Language Models (LLMs). We then map their frontier applications in image, LiDAR, trajectory, occupancy, video generation as well as LLM-guided reasoning and decision making. We categorize practical applications, such as synthetic data workflows, end-to-end driving strategies, high-fidelity digital twin systems, smart transportation networks, and cross-domain transfer to embodied AI. We identify key obstacles and possibilities such as comprehensive generalization across rare cases, evaluation and safety checks, budget-limited implementation, regulatory compliance, ethical concerns, and environmental effects, while proposing research plans across theoretical assurances, trust metrics, transport integration, and socio-technical influence. By unifying these threads, the survey provides a forward-looking reference for researchers, engineers, and policymakers navigating the convergence of generative AI and advanced autonomous mobility. An actively maintained repository of cited works is available at https://github.com/taco-group/GenAI4AD.
AI2-Active Safety: AI-enabled Interaction-aware Active Safety Analysis with Vehicle Dynamics
May 01, 2025This paper introduces an AI-enabled, interaction-aware active safety analysis framework that accounts for groupwise vehicle interactions. Specifically, the framework employs a bicycle model-augmented with road gradient considerations-to accurately capture vehicle dynamics. In parallel, a hypergraph-based AI model is developed to predict probabilistic trajectories of ambient traffic. By integrating these two components, the framework derives vehicle intra-spacing over a 3D road surface as the solution of a stochastic ordinary differential equation, yielding high-fidelity surrogate safety measures such as time-to-collision (TTC). To demonstrate its effectiveness, the framework is analyzed using stochastic numerical methods comprising 4th-order Runge-Kutta integration and AI inference, generating probability-weighted high-fidelity TTC (HF-TTC) distributions that reflect complex multi-agent maneuvers and behavioral uncertainties. Evaluated with HF-TTC against traditional constant-velocity TTC and non-interaction-aware approaches on highway datasets, the proposed framework offers a systematic methodology for active safety analysis with enhanced potential for improving safety perception in complex traffic environments.
The Role of Open-Source LLMs in Shaping the Future of GeoAI
Apr 24, 2025Large Language Models (LLMs) are transforming geospatial artificial intelligence (GeoAI), offering new capabilities in data processing, spatial analysis, and decision support. This paper examines the open-source paradigm's pivotal role in this transformation. While proprietary LLMs offer accessibility, they often limit the customization, interoperability, and transparency vital for specialized geospatial tasks. Conversely, open-source alternatives significantly advance Geographic Information Science (GIScience) by fostering greater adaptability, reproducibility, and community-driven innovation. Open frameworks empower researchers to tailor solutions, integrate cutting-edge methodologies (e.g., reinforcement learning, advanced spatial indexing), and align with FAIR principles. However, the growing reliance on any LLM necessitates careful consideration of security vulnerabilities, ethical risks, and robust governance for AI-generated geospatial outputs. Ongoing debates on accessibility, regulation, and misuse underscore the critical need for responsible AI development strategies. This paper argues that GIScience advances best not through a single model type, but by cultivating a diverse, interoperable ecosystem combining open-source foundations for innovation, bespoke geospatial models, and interdisciplinary collaboration. By critically evaluating the opportunities and challenges of open-source LLMs within the broader GeoAI landscape, this work contributes to a nuanced discourse on leveraging AI to effectively advance spatial research, policy, and decision-making in an equitable, sustainable, and scientifically rigorous manner.
GIScience in the Era of Artificial Intelligence: A Research Agenda Towards Autonomous GIS
Apr 01, 2025The advent of generative AI exemplified by large language models (LLMs) opens new ways to represent and compute geographic information and transcend the process of geographic knowledge production, driving geographic information systems (GIS) towards autonomous GIS. Leveraging LLMs as the decision core, autonomous GIS can independently generate and execute geoprocessing workflows to perform spatial analysis. In this vision paper, we elaborate on the concept of autonomous GIS and present a framework that defines its five autonomous goals, five levels of autonomy, five core functions, and three operational scales. We demonstrate how autonomous GIS could perform geospatial data retrieval, spatial analysis, and map making with four proof-of-concept GIS agents. We conclude by identifying critical challenges and future research directions, including fine-tuning and self-growing decision cores, autonomous modeling, and examining the ethical and practical implications of autonomous GIS. By establishing the groundwork for a paradigm shift in GIScience, this paper envisions a future where GIS moves beyond traditional workflows to autonomously reason, derive, innovate, and advance solutions to pressing global challenges.
Hypergraph-based Motion Generation with Multi-modal Interaction Relational Reasoning
Sep 18, 2024The intricate nature of real-world driving environments, characterized by dynamic and diverse interactions among multiple vehicles and their possible future states, presents considerable challenges in accurately predicting the motion states of vehicles and handling the uncertainty inherent in the predictions. Addressing these challenges requires comprehensive modeling and reasoning to capture the implicit relations among vehicles and the corresponding diverse behaviors. This research introduces an integrated framework for autonomous vehicles (AVs) motion prediction to address these complexities, utilizing a novel Relational Hypergraph Interaction-informed Neural mOtion generator (RHINO). RHINO leverages hypergraph-based relational reasoning by integrating a multi-scale hypergraph neural network to model group-wise interactions among multiple vehicles and their multi-modal driving behaviors, thereby enhancing motion prediction accuracy and reliability. Experimental validation using real-world datasets demonstrates the superior performance of this framework in improving predictive accuracy and fostering socially aware automated driving in dynamic traffic scenarios.