 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGIScience in the Era of Artificial Intelligence: A Research Agenda Towards Autonomous GIS
Apr 01, 2025The advent of generative AI exemplified by large language models (LLMs) opens new ways to represent and compute geographic information and transcend the process of geographic knowledge production, driving geographic information systems (GIS) towards autonomous GIS. Leveraging LLMs as the decision core, autonomous GIS can independently generate and execute geoprocessing workflows to perform spatial analysis. In this vision paper, we elaborate on the concept of autonomous GIS and present a framework that defines its five autonomous goals, five levels of autonomy, five core functions, and three operational scales. We demonstrate how autonomous GIS could perform geospatial data retrieval, spatial analysis, and map making with four proof-of-concept GIS agents. We conclude by identifying critical challenges and future research directions, including fine-tuning and self-growing decision cores, autonomous modeling, and examining the ethical and practical implications of autonomous GIS. By establishing the groundwork for a paradigm shift in GIScience, this paper envisions a future where GIS moves beyond traditional workflows to autonomously reason, derive, innovate, and advance solutions to pressing global challenges.
Building Extraction at Scale using Convolutional Neural Network: Mapping of the United States
May 23, 2018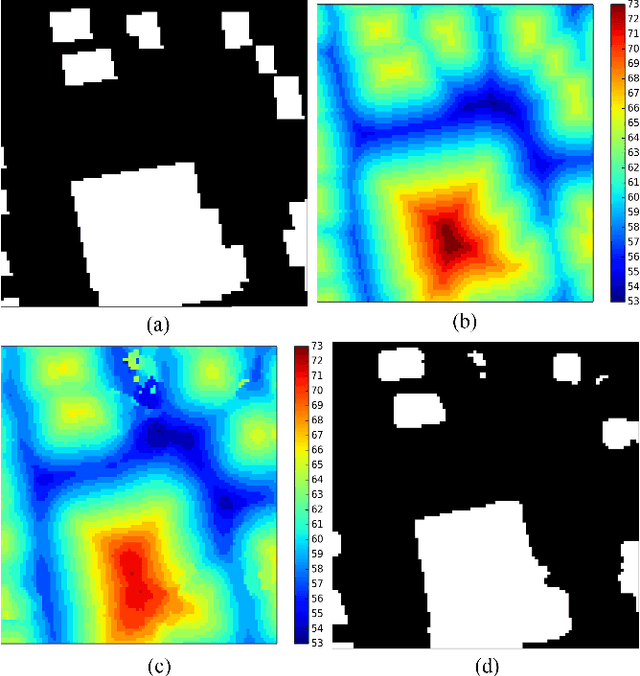
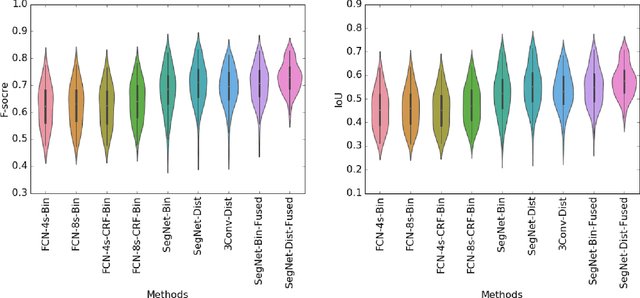
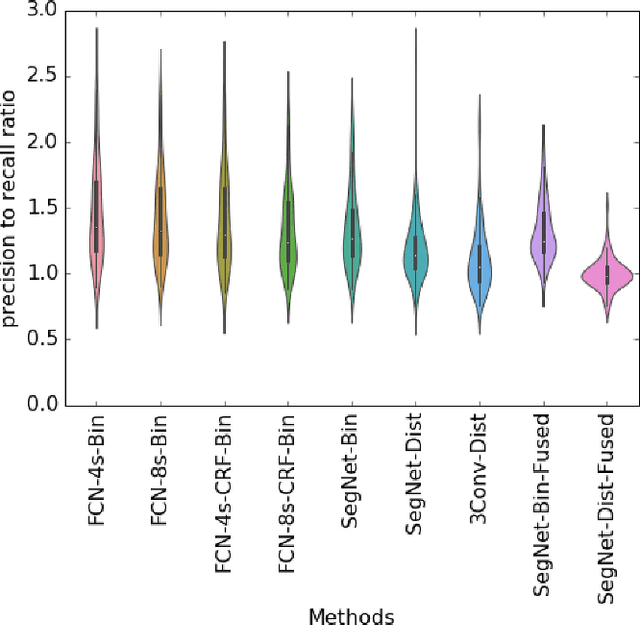
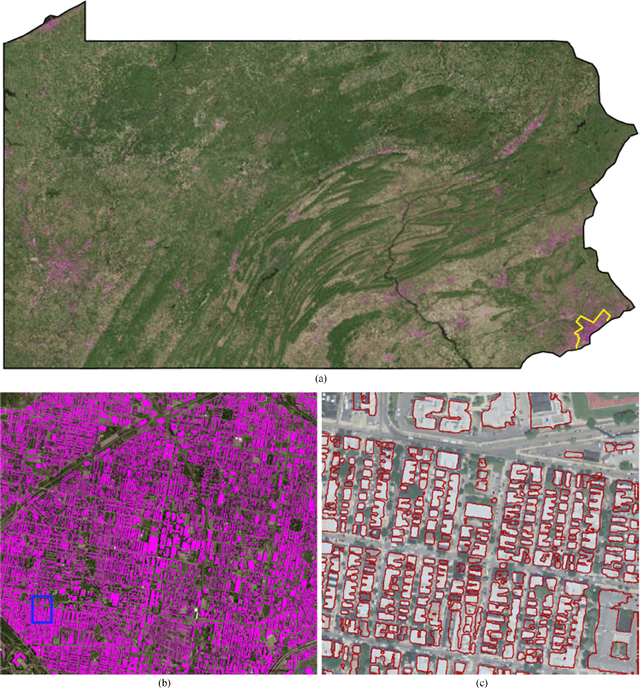
Establishing up-to-date large scale building maps is essential to understand urban dynamics, such as estimating population, urban planning and many other applications. Although many computer vision tasks has been successfully carried out with deep convolutional neural networks, there is a growing need to understand their large scale impact on building mapping with remote sensing imagery. Taking advantage of the scalability of CNNs and using only few areas with the abundance of building footprints, for the first time we conduct a comparative analysis of four state-of-the-art CNNs for extracting building footprints across the entire continental United States. The four CNN architectures namely: branch-out CNN, fully convolutional neural network (FCN), conditional random field as recurrent neural network (CRFasRNN), and SegNet, support semantic pixel-wise labeling and focus on capturing textural information at multi-scale. We use 1-meter resolution aerial images from National Agriculture Imagery Program (NAIP) as the test-bed, and compare the extraction results across the four methods. In addition, we propose to combine signed-distance labels with SegNet, the preferred CNN architecture identified by our extensive evaluations, to advance building extraction results to instance level. We further demonstrate the usefulness of fusing additional near IR information into the building extraction framework. Large scale experimental evaluations are conducted and reported using metrics that include: precision, recall rate, intersection over union, and the number of buildings extracted. With the improved CNN model and no requirement of further post-processing, we have generated building maps for the United States. The quality of extracted buildings and processing time demonstrated the proposed CNN-based framework fits the need of building extraction at scale.
Hashed Binary Search Sampling for Convolutional Network Training with Large Overhead Image Patches
Jul 18, 2017
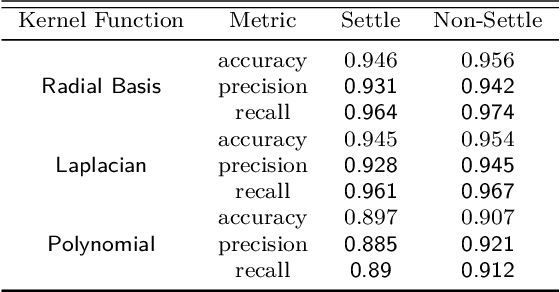
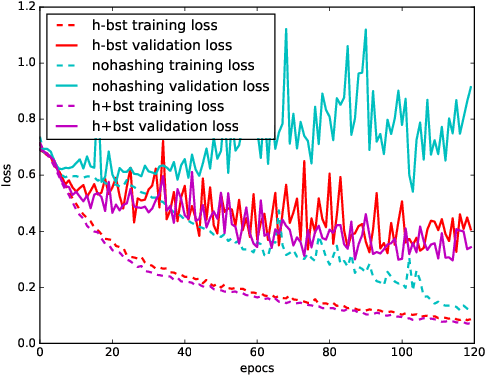

Very large overhead imagery associated with ground truth maps has the potential to generate billions of training image patches for machine learning algorithms. However, random sampling selection criteria often leads to redundant and noisy-image patches for model training. With minimal research efforts behind this challenge, the current status spells missed opportunities to develop supervised learning algorithms that generalize over wide geographical scenes. In addition, much of the computational cycles for large scale machine learning are poorly spent crunching through noisy and redundant image patches. We demonstrate a potential framework to address these challenges specifically, while evaluating a human settlement detection task. A novel binary search tree sampling scheme is fused with a kernel based hashing procedure that maps image patches into hash-buckets using binary codes generated from image content. The framework exploits inherent redundancy within billions of image patches to promote mostly high variance preserving samples for accelerating algorithmic training and increasing model generalization.