 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHashed Binary Search Sampling for Convolutional Network Training with Large Overhead Image Patches
Paper and Code
Jul 18, 2017
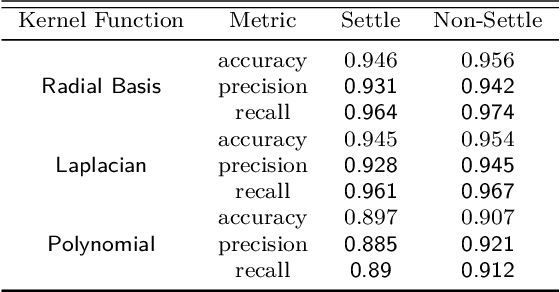
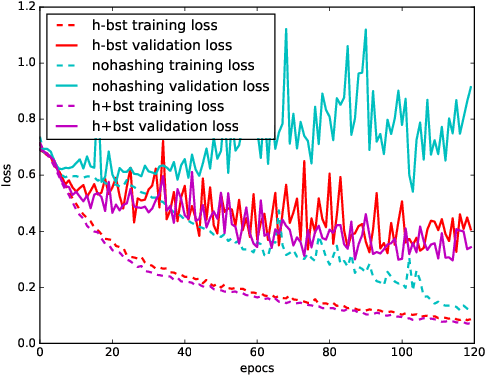

Very large overhead imagery associated with ground truth maps has the potential to generate billions of training image patches for machine learning algorithms. However, random sampling selection criteria often leads to redundant and noisy-image patches for model training. With minimal research efforts behind this challenge, the current status spells missed opportunities to develop supervised learning algorithms that generalize over wide geographical scenes. In addition, much of the computational cycles for large scale machine learning are poorly spent crunching through noisy and redundant image patches. We demonstrate a potential framework to address these challenges specifically, while evaluating a human settlement detection task. A novel binary search tree sampling scheme is fused with a kernel based hashing procedure that maps image patches into hash-buckets using binary codes generated from image content. The framework exploits inherent redundancy within billions of image patches to promote mostly high variance preserving samples for accelerating algorithmic training and increasing model generalization.