 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupled Orthogonal Dynamics: Regularization for Deep Network Optimizers
Feb 04, 2026Is the standard weight decay in AdamW truly optimal? Although AdamW decouples weight decay from adaptive gradient scaling, a fundamental conflict remains: the Radial Tug-of-War. In deep learning, gradients tend to increase parameter norms to expand effective capacity while steering directions to learn features, whereas weight decay indiscriminately suppresses norm growth. This push--pull interaction induces radial oscillations, injecting noise into Adam's second-moment estimates and potentially degrading delicate tangential feature learning. We argue that magnitude and direction play distinct roles and should be decoupled in optimizer dynamics. We propose Orthogonal Dynamics Decoupling and instantiate it as AdamO: an SGD-style update handles the one-dimensional norm control, while Adam's adaptive preconditioning is confined to the tangential subspace. AdamO further incorporates curvature-adaptive radial step sizing and architecture-aware rules and projections for scale-invariant layers and low-dimensional parameters. Experiments on vision and language tasks show that AdamO improves generalization and stability over AdamW without introducing additional complex constraints.
Cooperation of Experts: Fusing Heterogeneous Information with Large Margin
May 28, 2025Fusing heterogeneous information remains a persistent challenge in modern data analysis. While significant progress has been made, existing approaches often fail to account for the inherent heterogeneity of object patterns across different semantic spaces. To address this limitation, we propose the Cooperation of Experts (CoE) framework, which encodes multi-typed information into unified heterogeneous multiplex networks. By overcoming modality and connection differences, CoE provides a powerful and flexible model for capturing the intricate structures of real-world complex data. In our framework, dedicated encoders act as domain-specific experts, each specializing in learning distinct relational patterns in specific semantic spaces. To enhance robustness and extract complementary knowledge, these experts collaborate through a novel large margin mechanism supported by a tailored optimization strategy. Rigorous theoretical analyses guarantee the framework's feasibility and stability, while extensive experiments across diverse benchmarks demonstrate its superior performance and broad applicability. Our code is available at https://github.com/strangeAlan/CoE.
Riemannian Optimization on Relaxed Indicator Matrix Manifold
Mar 26, 2025The indicator matrix plays an important role in machine learning, but optimizing it is an NP-hard problem. We propose a new relaxation of the indicator matrix and prove that this relaxation forms a manifold, which we call the Relaxed Indicator Matrix Manifold (RIM manifold). Based on Riemannian geometry, we develop a Riemannian toolbox for optimization on the RIM manifold. Specifically, we provide several methods of Retraction, including a fast Retraction method to obtain geodesics. We point out that the RIM manifold is a generalization of the double stochastic manifold, and it is much faster than existing methods on the double stochastic manifold, which has a complexity of \( \mathcal{O}(n^3) \), while RIM manifold optimization is \( \mathcal{O}(n) \) and often yields better results. We conducted extensive experiments, including image denoising, with millions of variables to support our conclusion, and applied the RIM manifold to Ratio Cut, achieving clustering results that outperform the state-of-the-art methods. Our Code in \href{https://github.com/Yuan-Jinghui/Riemannian-Optimization-on-Relaxed-Indicator-Matrix-Manifold}{https://github.com/Yuan-Jinghui/Riemannian-Optimization-on-Relaxed-Indicator-Matrix-Manifold}.
Dual-Bounded Nonlinear Optimal Transport for Size Constrained Min Cut Clustering
Jan 30, 2025



Min cut is an important graph partitioning method. However, current solutions to the min cut problem suffer from slow speeds, difficulty in solving, and often converge to simple solutions. To address these issues, we relax the min cut problem into a dual-bounded constraint and, for the first time, treat the min cut problem as a dual-bounded nonlinear optimal transport problem. Additionally, we develop a method for solving dual-bounded nonlinear optimal transport based on the Frank-Wolfe method (abbreviated as DNF). Notably, DNF not only solves the size constrained min cut problem but is also applicable to all dual-bounded nonlinear optimal transport problems. We prove that for convex problems satisfying Lipschitz smoothness, the DNF method can achieve a convergence rate of \(\mathcal{O}(\frac{1}{t})\). We apply the DNF method to the min cut problem and find that it achieves state-of-the-art performance in terms of both the loss function and clustering accuracy at the fastest speed, with a convergence rate of \(\mathcal{O}(\frac{1}{\sqrt{t}})\). Moreover, the DNF method for the size constrained min cut problem requires no parameters and exhibits better stability.
GenAI-powered Multi-Agent Paradigm for Smart Urban Mobility: Opportunities and Challenges for Integrating Large Language Models (LLMs) and Retrieval-Augmented Generation (RAG) with Intelligent Transportation Systems
Aug 31, 2024

Leveraging recent advances in generative AI, multi-agent systems are increasingly being developed to enhance the functionality and efficiency of smart city applications. This paper explores the transformative potential of large language models (LLMs) and emerging Retrieval-Augmented Generation (RAG) technologies in Intelligent Transportation Systems (ITS), paving the way for innovative solutions to address critical challenges in urban mobility. We begin by providing a comprehensive overview of the current state-of-the-art in mobility data, ITS, and Connected Vehicles (CV) applications. Building on this review, we discuss the rationale behind RAG and examine the opportunities for integrating these Generative AI (GenAI) technologies into the smart mobility sector. We propose a conceptual framework aimed at developing multi-agent systems capable of intelligently and conversationally delivering smart mobility services to urban commuters, transportation operators, and decision-makers. Our approach seeks to foster an autonomous and intelligent approach that (a) promotes science-based advisory to reduce traffic congestion, accidents, and carbon emissions at multiple scales, (b) facilitates public education and engagement in participatory mobility management, and (c) automates specialized transportation management tasks and the development of critical ITS platforms, such as data analytics and interpretation, knowledge representation, and traffic simulations. By integrating LLM and RAG, our approach seeks to overcome the limitations of traditional rule-based multi-agent systems, which rely on fixed knowledge bases and limited reasoning capabilities. This integration paves the way for a more scalable, intuitive, and automated multi-agent paradigm, driving advancements in ITS and urban mobility.
Multi-Task Curriculum Graph Contrastive Learning with Clustering Entropy Guidance
Aug 22, 2024Recent advances in unsupervised deep graph clustering have been significantly promoted by contrastive learning. Despite the strides, most graph contrastive learning models face challenges: 1) graph augmentation is used to improve learning diversity, but commonly used random augmentation methods may destroy inherent semantics and cause noise; 2) the fixed positive and negative sample selection strategy is limited to deal with complex real data, thereby impeding the model's capability to capture fine-grained patterns and relationships. To reduce these problems, we propose the Clustering-guided Curriculum Graph contrastive Learning (CCGL) framework. CCGL uses clustering entropy as the guidance of the following graph augmentation and contrastive learning. Specifically, according to the clustering entropy, the intra-class edges and important features are emphasized in augmentation. Then, a multi-task curriculum learning scheme is proposed, which employs the clustering guidance to shift the focus from the discrimination task to the clustering task. In this way, the sample selection strategy of contrastive learning can be adjusted adaptively from early to late stage, which enhances the model's flexibility for complex data structure. Experimental results demonstrate that CCGL has achieved excellent performance compared to state-of-the-art competitors.
Doubly Stochastic Adaptive Neighbors Clustering via the Marcus Mapping
Aug 06, 2024

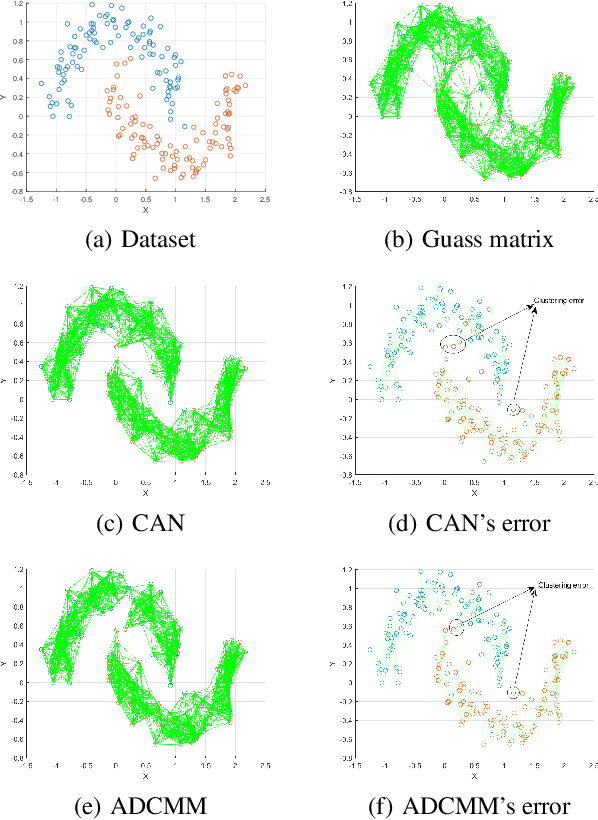
Clustering is a fundamental task in machine learning and data science, and similarity graph-based clustering is an important approach within this domain. Doubly stochastic symmetric similarity graphs provide numerous benefits for clustering problems and downstream tasks, yet learning such graphs remains a significant challenge. Marcus theorem states that a strictly positive symmetric matrix can be transformed into a doubly stochastic symmetric matrix by diagonal matrices. However, in clustering, learning sparse matrices is crucial for computational efficiency. We extend Marcus theorem by proposing the Marcus mapping, which indicates that certain sparse matrices can also be transformed into doubly stochastic symmetric matrices via diagonal matrices. Additionally, we introduce rank constraints into the clustering problem and propose the Doubly Stochastic Adaptive Neighbors Clustering algorithm based on the Marcus Mapping (ANCMM). This ensures that the learned graph naturally divides into the desired number of clusters. We validate the effectiveness of our algorithm through extensive comparisons with state-of-the-art algorithms. Finally, we explore the relationship between the Marcus mapping and optimal transport. We prove that the Marcus mapping solves a specific type of optimal transport problem and demonstrate that solving this problem through Marcus mapping is more efficient than directly applying optimal transport methods.
Achieving More with Less: A Tensor-Optimization-Powered Ensemble Method
Aug 06, 2024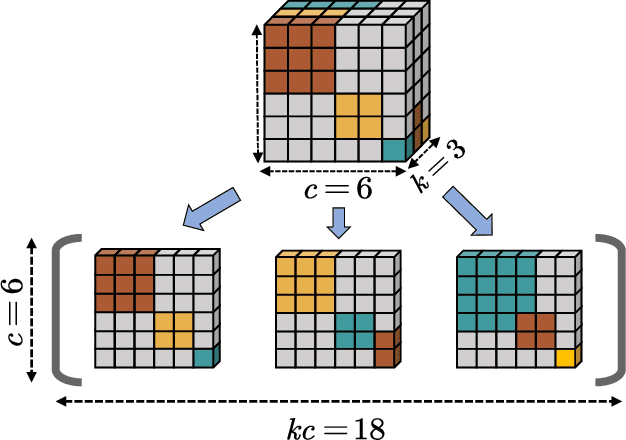
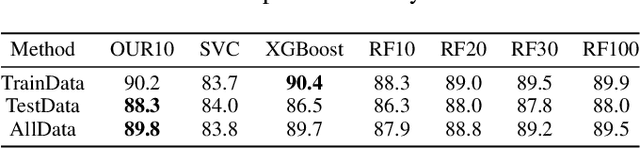
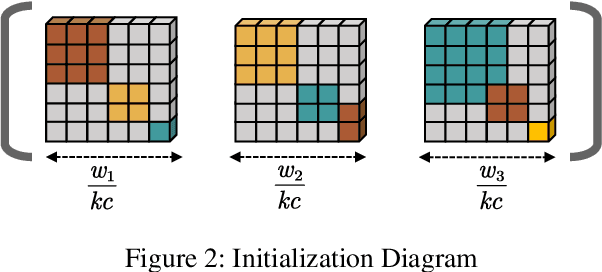
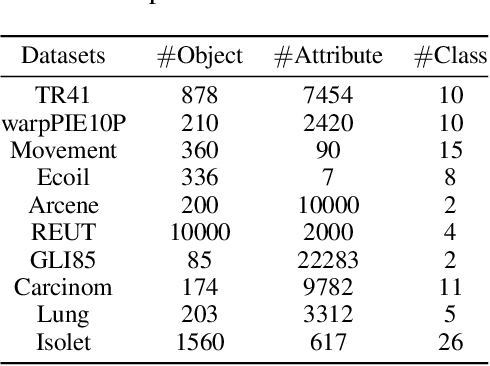
Ensemble learning is a method that leverages weak learners to produce a strong learner. However, obtaining a large number of base learners requires substantial time and computational resources. Therefore, it is meaningful to study how to achieve the performance typically obtained with many base learners using only a few. We argue that to achieve this, it is essential to enhance both classification performance and generalization ability during the ensemble process. To increase model accuracy, each weak base learner needs to be more efficiently integrated. It is observed that different base learners exhibit varying levels of accuracy in predicting different classes. To capitalize on this, we introduce confidence tensors $\tilde{\mathbf{\Theta}}$ and $\tilde{\mathbf{\Theta}}_{rst}$ signifies that the $t$-th base classifier assigns the sample to class $r$ while it actually belongs to class $s$. To the best of our knowledge, this is the first time an evaluation of the performance of base classifiers across different classes has been proposed. The proposed confidence tensor compensates for the strengths and weaknesses of each base classifier in different classes, enabling the method to achieve superior results with a smaller number of base learners. To enhance generalization performance, we design a smooth and convex objective function that leverages the concept of margin, making the strong learner more discriminative. Furthermore, it is proved that in gradient matrix of the loss function, the sum of each column's elements is zero, allowing us to solve a constrained optimization problem using gradient-based methods. We then compare our algorithm with random forests of ten times the size and other classical methods across numerous datasets, demonstrating the superiority of our approach.