 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAirV2X: Unified Air-Ground Vehicle-to-Everything Collaboration
Jun 24, 2025While multi-vehicular collaborative driving demonstrates clear advantages over single-vehicle autonomy, traditional infrastructure-based V2X systems remain constrained by substantial deployment costs and the creation of "uncovered danger zones" in rural and suburban areas. We present AirV2X-Perception, a large-scale dataset that leverages Unmanned Aerial Vehicles (UAVs) as a flexible alternative or complement to fixed Road-Side Units (RSUs). Drones offer unique advantages over ground-based perception: complementary bird's-eye-views that reduce occlusions, dynamic positioning capabilities that enable hovering, patrolling, and escorting navigation rules, and significantly lower deployment costs compared to fixed infrastructure. Our dataset comprises 6.73 hours of drone-assisted driving scenarios across urban, suburban, and rural environments with varied weather and lighting conditions. The AirV2X-Perception dataset facilitates the development and standardized evaluation of Vehicle-to-Drone (V2D) algorithms, addressing a critical gap in the rapidly expanding field of aerial-assisted autonomous driving systems. The dataset and development kits are open-sourced at https://github.com/taco-group/AirV2X-Perception.
Simulating the Unseen: Crash Prediction Must Learn from What Did Not Happen
May 27, 2025Traffic safety science has long been hindered by a fundamental data paradox: the crashes we most wish to prevent are precisely those events we rarely observe. Existing crash-frequency models and surrogate safety metrics rely heavily on sparse, noisy, and under-reported records, while even sophisticated, high-fidelity simulations undersample the long-tailed situations that trigger catastrophic outcomes such as fatalities. We argue that the path to achieving Vision Zero, i.e., the complete elimination of traffic fatalities and severe injuries, requires a paradigm shift from traditional crash-only learning to a new form of counterfactual safety learning: reasoning not only about what happened, but also about the vast set of plausible yet perilous scenarios that could have happened under slightly different circumstances. To operationalize this shift, our proposed agenda bridges macro to micro. Guided by crash-rate priors, generative scene engines, diverse driver models, and causal learning, near-miss events are synthesized and explained. A crash-focused digital twin testbed links micro scenes to macro patterns, while a multi-objective validator ensures that simulations maintain statistical realism. This pipeline transforms sparse crash data into rich signals for crash prediction, enabling the stress-testing of vehicles, roads, and policies before deployment. By learning from crashes that almost happened, we can shift traffic safety from reactive forensics to proactive prevention, advancing Vision Zero.
Generative AI for Autonomous Driving: Frontiers and Opportunities
May 13, 2025Generative Artificial Intelligence (GenAI) constitutes a transformative technological wave that reconfigures industries through its unparalleled capabilities for content creation, reasoning, planning, and multimodal understanding. This revolutionary force offers the most promising path yet toward solving one of engineering's grandest challenges: achieving reliable, fully autonomous driving, particularly the pursuit of Level 5 autonomy. This survey delivers a comprehensive and critical synthesis of the emerging role of GenAI across the autonomous driving stack. We begin by distilling the principles and trade-offs of modern generative modeling, encompassing VAEs, GANs, Diffusion Models, and Large Language Models (LLMs). We then map their frontier applications in image, LiDAR, trajectory, occupancy, video generation as well as LLM-guided reasoning and decision making. We categorize practical applications, such as synthetic data workflows, end-to-end driving strategies, high-fidelity digital twin systems, smart transportation networks, and cross-domain transfer to embodied AI. We identify key obstacles and possibilities such as comprehensive generalization across rare cases, evaluation and safety checks, budget-limited implementation, regulatory compliance, ethical concerns, and environmental effects, while proposing research plans across theoretical assurances, trust metrics, transport integration, and socio-technical influence. By unifying these threads, the survey provides a forward-looking reference for researchers, engineers, and policymakers navigating the convergence of generative AI and advanced autonomous mobility. An actively maintained repository of cited works is available at https://github.com/taco-group/GenAI4AD.
AI2-Active Safety: AI-enabled Interaction-aware Active Safety Analysis with Vehicle Dynamics
May 01, 2025This paper introduces an AI-enabled, interaction-aware active safety analysis framework that accounts for groupwise vehicle interactions. Specifically, the framework employs a bicycle model-augmented with road gradient considerations-to accurately capture vehicle dynamics. In parallel, a hypergraph-based AI model is developed to predict probabilistic trajectories of ambient traffic. By integrating these two components, the framework derives vehicle intra-spacing over a 3D road surface as the solution of a stochastic ordinary differential equation, yielding high-fidelity surrogate safety measures such as time-to-collision (TTC). To demonstrate its effectiveness, the framework is analyzed using stochastic numerical methods comprising 4th-order Runge-Kutta integration and AI inference, generating probability-weighted high-fidelity TTC (HF-TTC) distributions that reflect complex multi-agent maneuvers and behavioral uncertainties. Evaluated with HF-TTC against traditional constant-velocity TTC and non-interaction-aware approaches on highway datasets, the proposed framework offers a systematic methodology for active safety analysis with enhanced potential for improving safety perception in complex traffic environments.
Virtual Roads, Smarter Safety: A Digital Twin Framework for Mixed Autonomous Traffic Safety Analysis
Apr 24, 2025



This paper presents a digital-twin platform for active safety analysis in mixed traffic environments. The platform is built using a multi-modal data-enabled traffic environment constructed from drone-based aerial LiDAR, OpenStreetMap, and vehicle sensor data (e.g., GPS and inclinometer readings). High-resolution 3D road geometries are generated through AI-powered semantic segmentation and georeferencing of aerial LiDAR data. To simulate real-world driving scenarios, the platform integrates the CAR Learning to Act (CARLA) simulator, Simulation of Urban MObility (SUMO) traffic model, and NVIDIA PhysX vehicle dynamics engine. CARLA provides detailed micro-level sensor and perception data, while SUMO manages macro-level traffic flow. NVIDIA PhysX enables accurate modeling of vehicle behaviors under diverse conditions, accounting for mass distribution, tire friction, and center of mass. This integrated system supports high-fidelity simulations that capture the complex interactions between autonomous and conventional vehicles. Experimental results demonstrate the platform's ability to reproduce realistic vehicle dynamics and traffic scenarios, enhancing the analysis of active safety measures. Overall, the proposed framework advances traffic safety research by enabling in-depth, physics-informed evaluation of vehicle behavior in dynamic and heterogeneous traffic environments.
Planning Safety Trajectories with Dual-Phase, Physics-Informed, and Transportation Knowledge-Driven Large Language Models
Apr 06, 2025Foundation models have demonstrated strong reasoning and generalization capabilities in driving-related tasks, including scene understanding, planning, and control. However, they still face challenges in hallucinations, uncertainty, and long inference latency. While existing foundation models have general knowledge of avoiding collisions, they often lack transportation-specific safety knowledge. To overcome these limitations, we introduce LetsPi, a physics-informed, dual-phase, knowledge-driven framework for safe, human-like trajectory planning. To prevent hallucinations and minimize uncertainty, this hybrid framework integrates Large Language Model (LLM) reasoning with physics-informed social force dynamics. LetsPi leverages the LLM to analyze driving scenes and historical information, providing appropriate parameters and target destinations (goals) for the social force model, which then generates the future trajectory. Moreover, the dual-phase architecture balances reasoning and computational efficiency through its Memory Collection phase and Fast Inference phase. The Memory Collection phase leverages the physics-informed LLM to process and refine planning results through reasoning, reflection, and memory modules, storing safe, high-quality driving experiences in a memory bank. Surrogate safety measures and physics-informed prompt techniques are introduced to enhance the LLM's knowledge of transportation safety and physical force, respectively. The Fast Inference phase extracts similar driving experiences as few-shot examples for new scenarios, while simplifying input-output requirements to enable rapid trajectory planning without compromising safety. Extensive experiments using the HighD dataset demonstrate that LetsPi outperforms baseline models across five safety metrics.See PDF for project Github link.
V2X-LLM: Enhancing V2X Integration and Understanding in Connected Vehicle Corridors
Mar 04, 2025



The advancement of Connected and Automated Vehicles (CAVs) and Vehicle-to-Everything (V2X) offers significant potential for enhancing transportation safety, mobility, and sustainability. However, the integration and analysis of the diverse and voluminous V2X data, including Basic Safety Messages (BSMs) and Signal Phase and Timing (SPaT) data, present substantial challenges, especially on Connected Vehicle Corridors. These challenges include managing large data volumes, ensuring real-time data integration, and understanding complex traffic scenarios. Although these projects have developed an advanced CAV data pipeline that enables real-time communication between vehicles, infrastructure, and other road users for managing connected vehicle and roadside unit (RSU) data, significant hurdles in data comprehension and real-time scenario analysis and reasoning persist. To address these issues, we introduce the V2X-LLM framework, a novel enhancement to the existing CV data pipeline. V2X-LLM leverages Large Language Models (LLMs) to improve the understanding and real-time analysis of V2X data. The framework includes four key tasks: Scenario Explanation, offering detailed narratives of traffic conditions; V2X Data Description, detailing vehicle and infrastructure statuses; State Prediction, forecasting future traffic states; and Navigation Advisory, providing optimized routing instructions. By integrating LLM-driven reasoning with V2X data within the data pipeline, the V2X-LLM framework offers real-time feedback and decision support for traffic management. This integration enhances the accuracy of traffic analysis, safety, and traffic optimization. Demonstrations in a real-world urban corridor highlight the framework's potential to advance intelligent transportation systems.
FollowGen: A Scaled Noise Conditional Diffusion Model for Car-Following Trajectory Prediction
Nov 23, 2024



Vehicle trajectory prediction is crucial for advancing autonomous driving and advanced driver assistance systems (ADAS). Although deep learning-based approaches - especially those utilizing transformer-based and generative models - have markedly improved prediction accuracy by capturing complex, non-linear patterns in vehicle dynamics and traffic interactions, they frequently overlook detailed car-following behaviors and the inter-vehicle interactions critical for real-world driving applications, particularly in fully autonomous or mixed traffic scenarios. To address the issue, this study introduces a scaled noise conditional diffusion model for car-following trajectory prediction, which integrates detailed inter-vehicular interactions and car-following dynamics into a generative framework, improving both the accuracy and plausibility of predicted trajectories. The model utilizes a novel pipeline to capture historical vehicle dynamics by scaling noise with encoded historical features within the diffusion process. Particularly, it employs a cross-attention-based transformer architecture to model intricate inter-vehicle dependencies, effectively guiding the denoising process and enhancing prediction accuracy. Experimental results on diverse real-world driving scenarios demonstrate the state-of-the-art performance and robustness of the proposed method.
Real-World Data Inspired Interactive Connected Traffic Scenario Generation
Sep 25, 2024


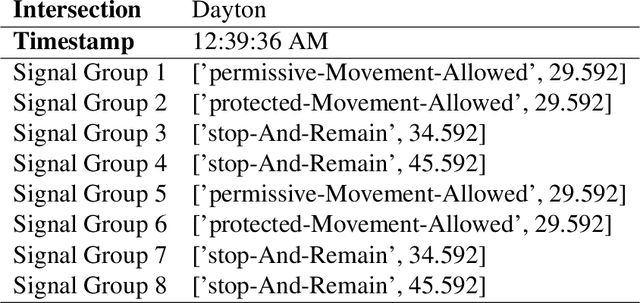
Simulation is a crucial step in ensuring accurate, efficient, and realistic Connected and Autonomous Vehicles (CAVs) testing and validation. As the adoption of CAV accelerates, the integration of real-world data into simulation environments becomes increasingly critical. Among various technologies utilized by CAVs, Vehicle-to-Everything (V2X) communication plays a crucial role in ensuring a seamless transmission of information between CAVs, infrastructure, and other road users. However, most existing studies have focused on developing and testing communication protocols, resource allocation strategies, and data dissemination techniques in V2X. There is a gap where real-world V2X data is integrated into simulations to generate diverse and high-fidelity traffic scenarios. To fulfill this research gap, we leverage real-world Signal Phase and Timing (SPaT) data from Roadside Units (RSUs) to enhance the fidelity of CAV simulations. Moreover, we developed an algorithm that enables Autonomous Vehicles (AVs) to respond dynamically to real-time traffic signal data, simulating realistic V2X communication scenarios. Such high-fidelity simulation environments can generate multimodal data, including trajectory, semantic camera, depth camera, and bird's eye view data for various traffic scenarios. The generated scenarios and data provide invaluable insights into AVs' interactions with traffic infrastructure and other road users. This work aims to bridge the gap between theoretical research and practical deployment of CAVs, facilitating the development of smarter and safer transportation systems.
Hypergraph-based Motion Generation with Multi-modal Interaction Relational Reasoning
Sep 18, 2024The intricate nature of real-world driving environments, characterized by dynamic and diverse interactions among multiple vehicles and their possible future states, presents considerable challenges in accurately predicting the motion states of vehicles and handling the uncertainty inherent in the predictions. Addressing these challenges requires comprehensive modeling and reasoning to capture the implicit relations among vehicles and the corresponding diverse behaviors. This research introduces an integrated framework for autonomous vehicles (AVs) motion prediction to address these complexities, utilizing a novel Relational Hypergraph Interaction-informed Neural mOtion generator (RHINO). RHINO leverages hypergraph-based relational reasoning by integrating a multi-scale hypergraph neural network to model group-wise interactions among multiple vehicles and their multi-modal driving behaviors, thereby enhancing motion prediction accuracy and reliability. Experimental validation using real-world datasets demonstrates the superior performance of this framework in improving predictive accuracy and fostering socially aware automated driving in dynamic traffic scenarios.