 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous Latent Contexts Enable Efficient Online Learning in Transformers
May 11, 2026Large language models (LLMs) exhibit a strong capacity for in-context learning: Given labeled examples, they can generate good predictions without parameter updates. However, many interactive settings go beyond static prediction to online decision-making, in which effective behavior demands adaptation over long multi-turn horizons in response to feedback, and efficient algorithms in these domains must use compact representations of what they have learned. Recently, continuous transformer architectures with latent chain of thought have shown promise for offline iterative tasks such as directed graph-reachability. Motivated by this, we study whether continuous latent context tokens equip transformers to more effectively realize online learning. We give explicit constructions of constant-depth transformers that implement two foundational online decision-making procedures -- the weighted majority algorithm and $Q$-learning -- by storing their algorithmic state as linear combinations of feature embeddings, using a small number of latent context tokens. We further train a small GPT-2-style transformer with latent contexts using a multi-curriculum objective that does not directly supervise the latent states. On long synthetic online prediction sequences, this model outperforms larger and more complex LLMs, including Qwen-3-14B and DeepSeek-V3. Our results suggest that continuous latent contexts provide a simple and effective persistent state for transformers to implement online learning algorithms.
Provable Long-Range Benefits of Next-Token Prediction
Dec 08, 2025Why do modern language models, trained to do well on next-word prediction, appear to generate coherent documents and capture long-range structure? Here we show that next-token prediction is provably powerful for learning longer-range structure, even with common neural network architectures. Specifically, we prove that optimizing next-token prediction over a Recurrent Neural Network (RNN) yields a model that closely approximates the training distribution: for held-out documents sampled from the training distribution, no algorithm of bounded description length limited to examining the next $k$ tokens, for any $k$, can distinguish between $k$ consecutive tokens of such documents and $k$ tokens generated by the learned language model following the same prefix. We provide polynomial bounds (in $k$, independent of the document length) on the model size needed to achieve such $k$-token indistinguishability, offering a complexity-theoretic explanation for the long-range coherence observed in practice.
Simulating the Unseen: Crash Prediction Must Learn from What Did Not Happen
May 27, 2025Traffic safety science has long been hindered by a fundamental data paradox: the crashes we most wish to prevent are precisely those events we rarely observe. Existing crash-frequency models and surrogate safety metrics rely heavily on sparse, noisy, and under-reported records, while even sophisticated, high-fidelity simulations undersample the long-tailed situations that trigger catastrophic outcomes such as fatalities. We argue that the path to achieving Vision Zero, i.e., the complete elimination of traffic fatalities and severe injuries, requires a paradigm shift from traditional crash-only learning to a new form of counterfactual safety learning: reasoning not only about what happened, but also about the vast set of plausible yet perilous scenarios that could have happened under slightly different circumstances. To operationalize this shift, our proposed agenda bridges macro to micro. Guided by crash-rate priors, generative scene engines, diverse driver models, and causal learning, near-miss events are synthesized and explained. A crash-focused digital twin testbed links micro scenes to macro patterns, while a multi-objective validator ensures that simulations maintain statistical realism. This pipeline transforms sparse crash data into rich signals for crash prediction, enabling the stress-testing of vehicles, roads, and policies before deployment. By learning from crashes that almost happened, we can shift traffic safety from reactive forensics to proactive prevention, advancing Vision Zero.
StructComp: Substituting propagation with Structural Compression in Training Graph Contrastive Learning
Dec 08, 2023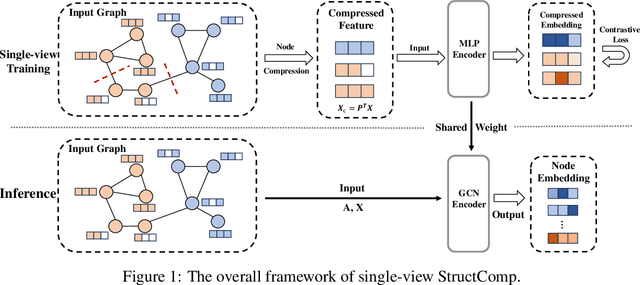
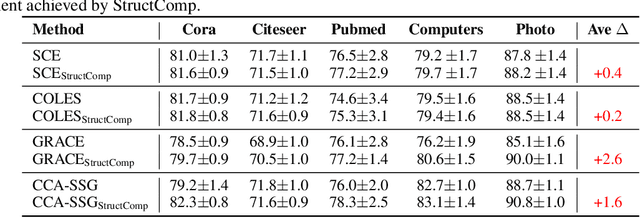
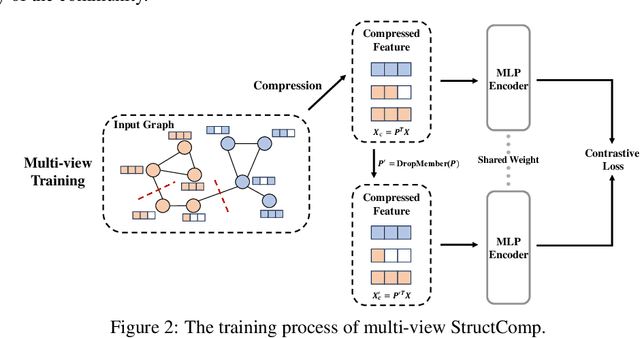
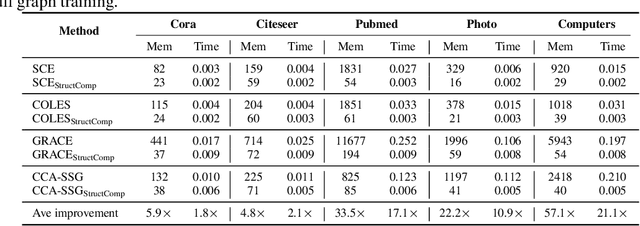
Graph contrastive learning (GCL) has become a powerful tool for learning graph data, but its scalability remains a significant challenge. In this work, we propose a simple yet effective training framework called Structural Compression (StructComp) to address this issue. Inspired by a sparse low-rank approximation on the diffusion matrix, StructComp trains the encoder with the compressed nodes. This allows the encoder not to perform any message passing during the training stage, and significantly reduces the number of sample pairs in the contrastive loss. We theoretically prove that the original GCL loss can be approximated with the contrastive loss computed by StructComp. Moreover, StructComp can be regarded as an additional regularization term for GCL models, resulting in a more robust encoder. Empirical studies on seven benchmark datasets show that StructComp greatly reduces the time and memory consumption while improving model performance compared to the vanilla GCL models and scalable training methods.
Contrastive Moments: Unsupervised Halfspace Learning in Polynomial Time
Nov 02, 2023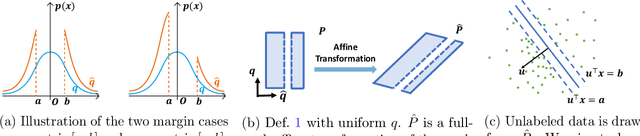
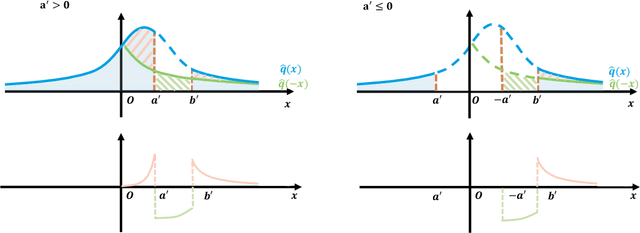
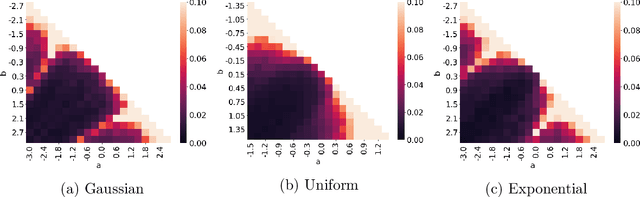
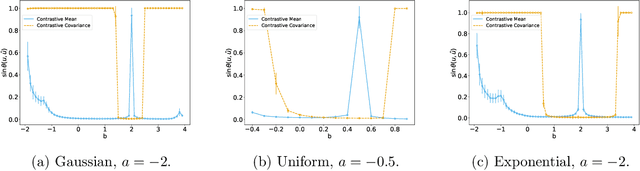
We give a polynomial-time algorithm for learning high-dimensional halfspaces with margins in $d$-dimensional space to within desired TV distance when the ambient distribution is an unknown affine transformation of the $d$-fold product of an (unknown) symmetric one-dimensional logconcave distribution, and the halfspace is introduced by deleting at least an $\epsilon$ fraction of the data in one of the component distributions. Notably, our algorithm does not need labels and establishes the unique (and efficient) identifiability of the hidden halfspace under this distributional assumption. The sample and time complexity of the algorithm are polynomial in the dimension and $1/\epsilon$. The algorithm uses only the first two moments of suitable re-weightings of the empirical distribution, which we call contrastive moments; its analysis uses classical facts about generalized Dirichlet polynomials and relies crucially on a new monotonicity property of the moment ratio of truncations of logconcave distributions. Such algorithms, based only on first and second moments were suggested in earlier work, but hitherto eluded rigorous guarantees. Prior work addressed the special case when the underlying distribution is Gaussian via Non-Gaussian Component Analysis. We improve on this by providing polytime guarantees based on Total Variation (TV) distance, in place of existing moment-bound guarantees that can be super-polynomial. Our work is also the first to go beyond Gaussians in this setting.
Towards Understanding Neural Collapse: The Effects of Batch Normalization and Weight Decay
Oct 02, 2023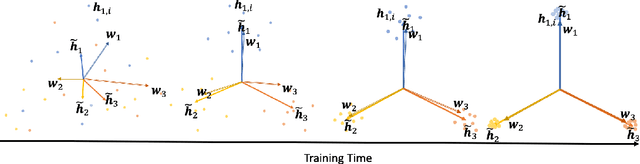
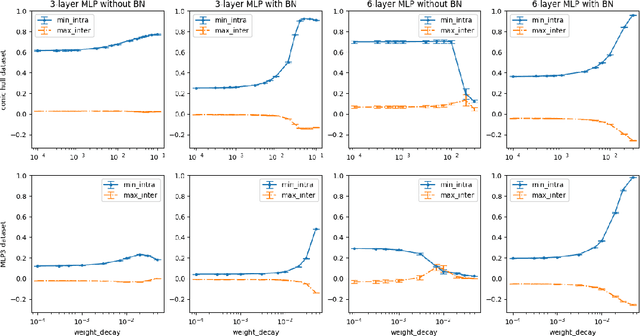
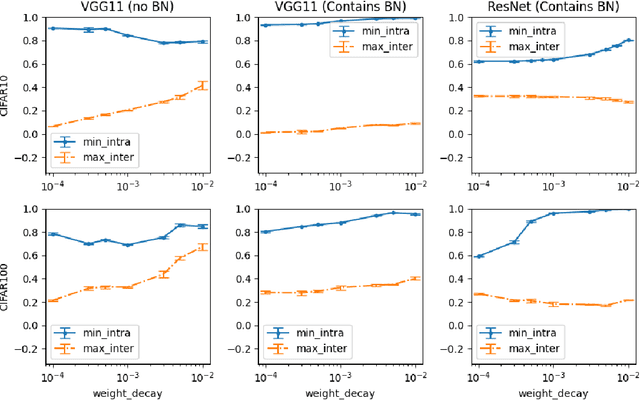
Neural Collapse (NC) is a geometric structure recently observed in the final layer of neural network classifiers. In this paper, we investigate the interrelationships between batch normalization (BN), weight decay, and proximity to the NC structure. Our work introduces the geometrically intuitive intra-class and inter-class cosine similarity measure, which encapsulates multiple core aspects of NC. Leveraging this measure, we establish theoretical guarantees for the emergence of NC under the influence of last-layer BN and weight decay, specifically in scenarios where the regularized cross-entropy loss is near-optimal. Experimental evidence substantiates our theoretical findings, revealing a pronounced occurrence of NC in models incorporating BN and appropriate weight-decay values. This combination of theoretical and empirical insights suggests a greatly influential role of BN and weight decay in the emergence of NC.
Graph-Level Embedding for Time-Evolving Graphs
Jun 01, 2023Graph representation learning (also known as network embedding) has been extensively researched with varying levels of granularity, ranging from nodes to graphs. While most prior work in this area focuses on node-level representation, limited research has been conducted on graph-level embedding, particularly for dynamic or temporal networks. However, learning low-dimensional graph-level representations for dynamic networks is critical for various downstream graph retrieval tasks such as temporal graph similarity ranking, temporal graph isomorphism, and anomaly detection. In this paper, we present a novel method for temporal graph-level embedding that addresses this gap. Our approach involves constructing a multilayer graph and using a modified random walk with temporal backtracking to generate temporal contexts for the graph's nodes. We then train a "document-level" language model on these contexts to generate graph-level embeddings. We evaluate our proposed model on five publicly available datasets for the task of temporal graph similarity ranking, and our model outperforms baseline methods. Our experimental results demonstrate the effectiveness of our method in generating graph-level embeddings for dynamic networks.
Provable Lifelong Learning of Representations
Oct 27, 2021
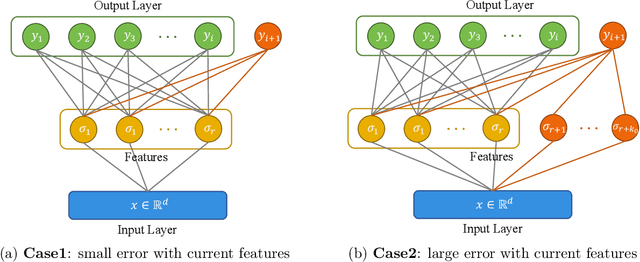
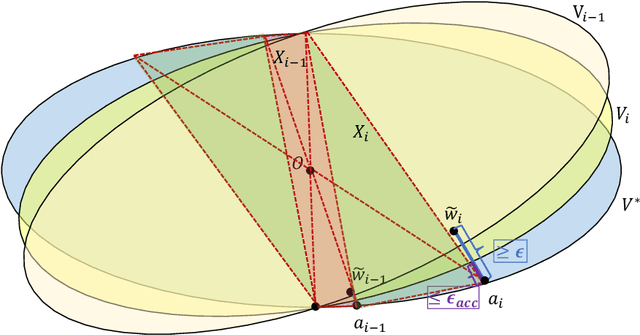
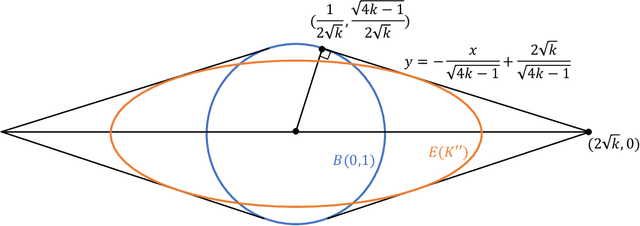
In lifelong learning, the tasks (or classes) to be learned arrive sequentially over time in arbitrary order. During training, knowledge from previous tasks can be captured and transferred to subsequent ones to improve sample efficiency. We consider the setting where all target tasks can be represented in the span of a small number of unknown linear or nonlinear features of the input data. We propose a provable lifelong learning algorithm that maintains and refines the internal feature representation. We prove that for any desired accuracy on all tasks, the dimension of the representation remains close to that of the underlying representation. The resulting sample complexity improves significantly on existing bounds. In the setting of linear features, our algorithm is provably efficient and the sample complexity for input dimension $d$, $m$ tasks with $k$ features up to error $\epsilon$ is $\tilde{O}(dk^{1.5}/\epsilon+km/\epsilon)$. We also prove a matching lower bound for any lifelong learning algorithm that uses a single task learner as a black box. Finally, we complement our analysis with an empirical study.
Graph Embedding via Diffusion-Wavelets-Based Node Feature Distribution Characterization
Sep 14, 2021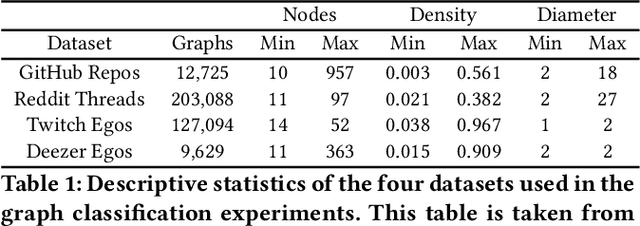
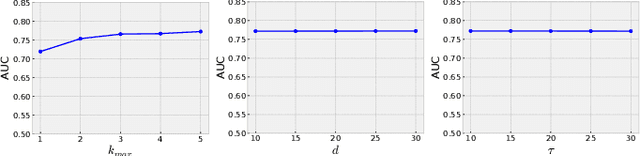
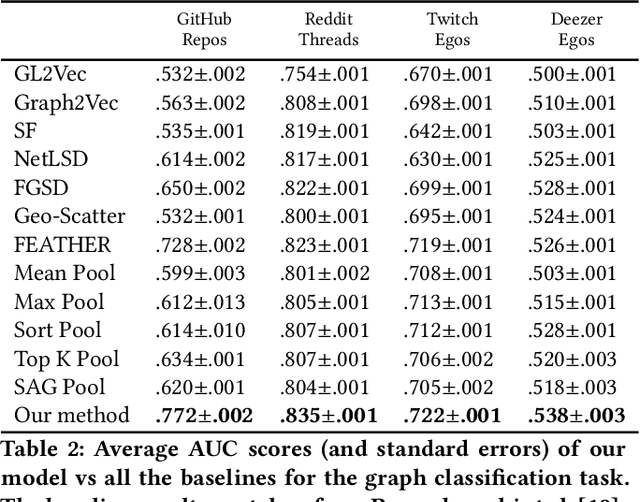
Recent years have seen a rise in the development of representational learning methods for graph data. Most of these methods, however, focus on node-level representation learning at various scales (e.g., microscopic, mesoscopic, and macroscopic node embedding). In comparison, methods for representation learning on whole graphs are currently relatively sparse. In this paper, we propose a novel unsupervised whole graph embedding method. Our method uses spectral graph wavelets to capture topological similarities on each k-hop sub-graph between nodes and uses them to learn embeddings for the whole graph. We evaluate our method against 12 well-known baselines on 4 real-world datasets and show that our method achieves the best performance across all experiments, outperforming the current state-of-the-art by a considerable margin.