 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpAgent: Operator Agent for Web Navigation
Feb 14, 2026To fulfill user instructions, autonomous web agents must contend with the inherent complexity and volatile nature of real-world websites. Conventional paradigms predominantly rely on Supervised Fine-Tuning (SFT) or Offline Reinforcement Learning (RL) using static datasets. However, these methods suffer from severe distributional shifts, as offline trajectories fail to capture the stochastic state transitions and real-time feedback of unconstrained wide web environments. In this paper, we propose a robust Online Reinforcement Learning WebAgent, designed to optimize its policy through direct, iterative interactions with unconstrained wide websites. Our approach comprises three core innovations: 1) Hierarchical Multi-Task Fine-tuning: We curate a comprehensive mixture of datasets categorized by functional primitives -- Planning, Acting, and Grounding -- establishing a Vision-Language Model (VLM) with strong instruction-following capabilities for Web GUI tasks. 2) Online Agentic RL in the Wild: We develop an online interaction environment and fine-tune the VLM using a specialized RL pipeline. We introduce a Hybrid Reward Mechanism that combines a ground-truth-agnostic WebJudge for holistic outcome assessment with a Rule-based Decision Tree (RDT) for progress reward. This system effectively mitigates the credit assignment challenge in long-horizon navigation. Notably, our RL-enhanced model achieves a 38.1\% success rate (pass@5) on WebArena, outperforming all existing monolithic baselines. 3) Operator Agent: We introduce a modular agentic framework, namely \textbf{OpAgent}, orchestrating a Planner, Grounder, Reflector, and Summarizer. This synergy enables robust error recovery and self-correction, elevating the agent's performance to a new State-of-the-Art (SOTA) success rate of \textbf{71.6\%}.
Right Is Not Enough: The Pitfalls of Outcome Supervision in Training LLMs for Math Reasoning
Jun 07, 2025Outcome-rewarded Large Language Models (LLMs) have demonstrated remarkable success in mathematical problem-solving. However, this success often masks a critical issue: models frequently achieve correct answers through fundamentally unsound reasoning processes, a phenomenon indicative of reward hacking. We introduce MathOlympiadEval, a new dataset with fine-grained annotations, which reveals a significant gap between LLMs' answer correctness and their low process correctness. Existing automated methods like LLM-as-a-judge struggle to reliably detect these reasoning flaws. To address this, we propose ParaStepVerifier, a novel methodology for meticulous, step-by-step verification of mathematical solutions. ParaStepVerifier identifies incorrect reasoning steps. Empirical results demonstrate that ParaStepVerifier substantially improves the accuracy of identifying flawed solutions compared to baselines, especially for complex, multi-step problems. This offers a more robust path towards evaluating and training LLMs with genuine mathematical reasoning.
TAT-R1: Terminology-Aware Translation with Reinforcement Learning and Word Alignment
May 27, 2025Recently, deep reasoning large language models(LLMs) like DeepSeek-R1 have made significant progress in tasks such as mathematics and coding. Inspired by this, several studies have employed reinforcement learning(RL) to enhance models' deep reasoning capabilities and improve machine translation(MT) quality. However, the terminology translation, an essential task in MT, remains unexplored in deep reasoning LLMs. In this paper, we propose \textbf{TAT-R1}, a terminology-aware translation model trained with reinforcement learning and word alignment. Specifically, we first extract the keyword translation pairs using a word alignment model. Then we carefully design three types of rule-based alignment rewards with the extracted alignment relationships. With those alignment rewards, the RL-trained translation model can learn to focus on the accurate translation of key information, including terminology in the source text. Experimental results show the effectiveness of TAT-R1. Our model significantly improves terminology translation accuracy compared to the baseline models while maintaining comparable performance on general translation tasks. In addition, we conduct detailed ablation studies of the DeepSeek-R1-like training paradigm for machine translation and reveal several key findings.
SSR-Zero: Simple Self-Rewarding Reinforcement Learning for Machine Translation
May 22, 2025Large language models (LLMs) have recently demonstrated remarkable capabilities in machine translation (MT). However, most advanced MT-specific LLMs heavily rely on external supervision signals during training, such as human-annotated reference data or trained reward models (RMs), which are often expensive to obtain and challenging to scale. To overcome this limitation, we propose a Simple Self-Rewarding (SSR) Reinforcement Learning (RL) framework for MT that is reference-free, fully online, and relies solely on self-judging rewards. Training with SSR using 13K monolingual examples and Qwen-2.5-7B as the backbone, our model SSR-Zero-7B outperforms existing MT-specific LLMs, e.g., TowerInstruct-13B and GemmaX-28-9B, as well as larger general LLMs like Qwen2.5-32B-Instruct in English $\leftrightarrow$ Chinese translation tasks from WMT23, WMT24, and Flores200 benchmarks. Furthermore, by augmenting SSR with external supervision from COMET, our strongest model, SSR-X-Zero-7B, achieves state-of-the-art performance in English $\leftrightarrow$ Chinese translation, surpassing all existing open-source models under 72B parameters and even outperforming closed-source models, e.g., GPT-4o and Gemini 1.5 Pro. Our analysis highlights the effectiveness of the self-rewarding mechanism compared to the external LLM-as-a-judge approach in MT and demonstrates its complementary benefits when combined with trained RMs. Our findings provide valuable insight into the potential of self-improving RL methods. We have publicly released our code, data and models.
FastCuRL: Curriculum Reinforcement Learning with Progressive Context Extension for Efficient Training R1-like Reasoning Models
Mar 21, 2025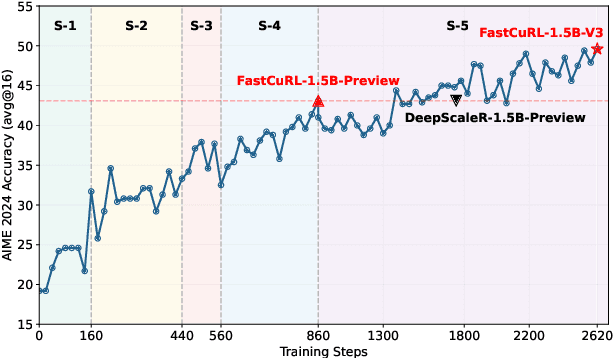



In this paper, we propose \textbf{\textsc{FastCuRL}}, a simple yet efficient \textbf{Cu}rriculum \textbf{R}einforcement \textbf{L}earning approach with context window extending strategy to accelerate the reinforcement learning training efficiency for R1-like reasoning models while enhancing their performance in tackling complex reasoning tasks with long chain-of-thought rationales, particularly with a 1.5B parameter language model. \textbf{\textsc{FastCuRL}} consists of two main procedures: length-aware training data segmentation and context window extension training. Specifically, the former first splits the original training data into three different levels by the input prompt length, and then the latter leverages segmented training datasets with a progressively increasing context window length to train the reasoning model. Experimental results demonstrate that \textbf{\textsc{FastCuRL}}-1.5B-Preview surpasses DeepScaleR-1.5B-Preview across all five datasets (including MATH 500, AIME 2024, AMC 2023, Minerva Math, and OlympiadBench) while only utilizing 50\% of training steps. Furthermore, all training stages for FastCuRL-1.5B-Preview are completed using just a single node with 8 GPUs.
Your Graph Recommender is Provably a Single-view Graph Contrastive Learning
Jul 25, 2024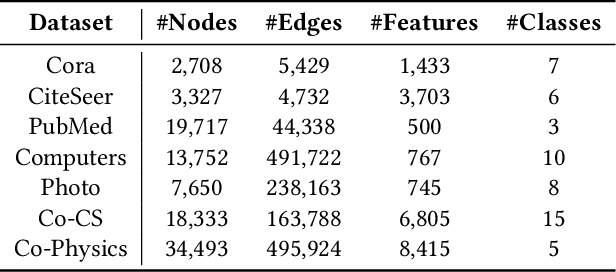
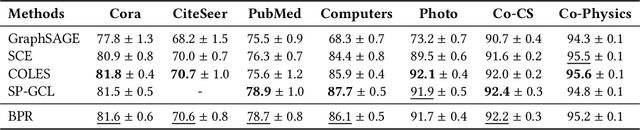
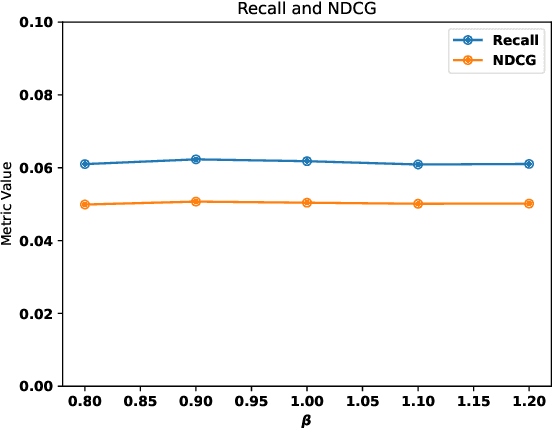
Graph recommender (GR) is a type of graph neural network (GNNs) encoder that is customized for extracting information from the user-item interaction graph. Due to its strong performance on the recommendation task, GR has gained significant attention recently. Graph contrastive learning (GCL) is also a popular research direction that aims to learn, often unsupervised, GNNs with certain contrastive objectives. As a general graph representation learning method, GCLs have been widely adopted with the supervised recommendation loss for joint training of GRs. Despite the intersection of GR and GCL research, theoretical understanding of the relationship between the two fields is surprisingly sparse. This vacancy inevitably leads to inefficient scientific research. In this paper, we aim to bridge the gap between the field of GR and GCL from the perspective of encoders and loss functions. With mild assumptions, we theoretically show an astonishing fact that graph recommender is equivalent to a commonly-used single-view graph contrastive model. Specifically, we find that (1) the classic encoder in GR is essentially a linear graph convolutional network with one-hot inputs, and (2) the loss function in GR is well bounded by a single-view GCL loss with certain hyperparameters. The first observation enables us to explain crucial designs of GR models, e.g., the removal of self-loop and nonlinearity. And the second finding can easily prompt many cross-field research directions. We empirically show a remarkable result that the recommendation loss and the GCL loss can be used interchangeably. The fact that we can train GR models solely with the GCL loss is particularly insightful, since before this work, GCLs were typically viewed as unsupervised methods that need fine-tuning. We also discuss some potential future works inspired by our theory.
Understanding Community Bias Amplification in Graph Representation Learning
Dec 08, 2023In this work, we discover a phenomenon of community bias amplification in graph representation learning, which refers to the exacerbation of performance bias between different classes by graph representation learning. We conduct an in-depth theoretical study of this phenomenon from a novel spectral perspective. Our analysis suggests that structural bias between communities results in varying local convergence speeds for node embeddings. This phenomenon leads to bias amplification in the classification results of downstream tasks. Based on the theoretical insights, we propose random graph coarsening, which is proved to be effective in dealing with the above issue. Finally, we propose a novel graph contrastive learning model called Random Graph Coarsening Contrastive Learning (RGCCL), which utilizes random coarsening as data augmentation and mitigates community bias by contrasting the coarsened graph with the original graph. Extensive experiments on various datasets demonstrate the advantage of our method when dealing with community bias amplification.
StructComp: Substituting propagation with Structural Compression in Training Graph Contrastive Learning
Dec 08, 2023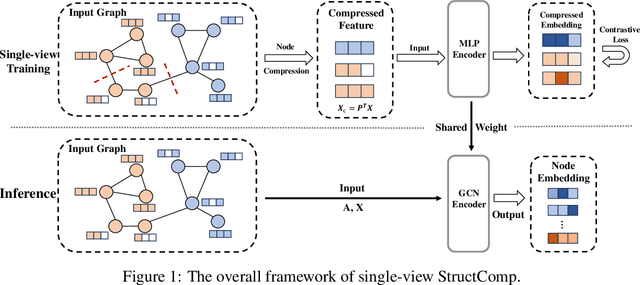
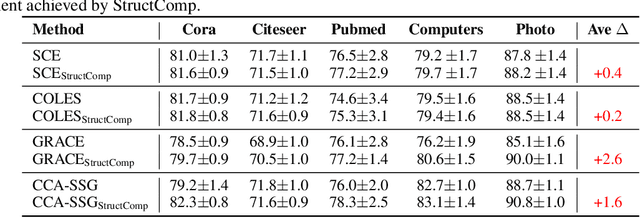
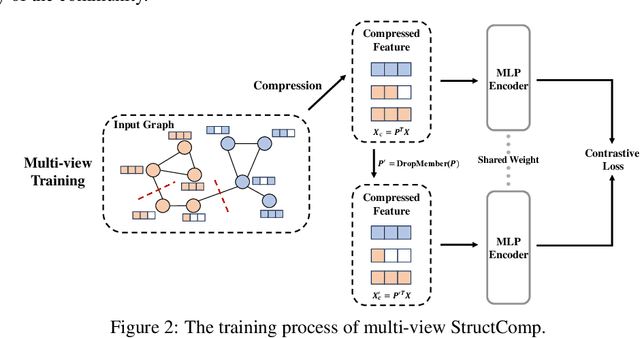
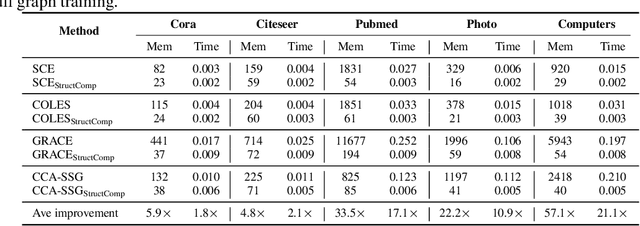
Graph contrastive learning (GCL) has become a powerful tool for learning graph data, but its scalability remains a significant challenge. In this work, we propose a simple yet effective training framework called Structural Compression (StructComp) to address this issue. Inspired by a sparse low-rank approximation on the diffusion matrix, StructComp trains the encoder with the compressed nodes. This allows the encoder not to perform any message passing during the training stage, and significantly reduces the number of sample pairs in the contrastive loss. We theoretically prove that the original GCL loss can be approximated with the contrastive loss computed by StructComp. Moreover, StructComp can be regarded as an additional regularization term for GCL models, resulting in a more robust encoder. Empirical studies on seven benchmark datasets show that StructComp greatly reduces the time and memory consumption while improving model performance compared to the vanilla GCL models and scalable training methods.
Cross-view Semantic Alignment for Livestreaming Product Recognition
Aug 19, 2023



Live commerce is the act of selling products online through live streaming. The customer's diverse demands for online products introduce more challenges to Livestreaming Product Recognition. Previous works have primarily focused on fashion clothing data or utilize single-modal input, which does not reflect the real-world scenario where multimodal data from various categories are present. In this paper, we present LPR4M, a large-scale multimodal dataset that covers 34 categories, comprises 3 modalities (image, video, and text), and is 50x larger than the largest publicly available dataset. LPR4M contains diverse videos and noise modality pairs while exhibiting a long-tailed distribution, resembling real-world problems. Moreover, a cRoss-vIew semantiC alignmEnt (RICE) model is proposed to learn discriminative instance features from the image and video views of the products. This is achieved through instance-level contrastive learning and cross-view patch-level feature propagation. A novel Patch Feature Reconstruction loss is proposed to penalize the semantic misalignment between cross-view patches. Extensive experiments demonstrate the effectiveness of RICE and provide insights into the importance of dataset diversity and expressivity. The dataset and code are available at https://github.com/adxcreative/RICE
Cross-Domain Product Representation Learning for Rich-Content E-Commerce
Aug 10, 2023The proliferation of short video and live-streaming platforms has revolutionized how consumers engage in online shopping. Instead of browsing product pages, consumers are now turning to rich-content e-commerce, where they can purchase products through dynamic and interactive media like short videos and live streams. This emerging form of online shopping has introduced technical challenges, as products may be presented differently across various media domains. Therefore, a unified product representation is essential for achieving cross-domain product recognition to ensure an optimal user search experience and effective product recommendations. Despite the urgent industrial need for a unified cross-domain product representation, previous studies have predominantly focused only on product pages without taking into account short videos and live streams. To fill the gap in the rich-content e-commerce area, in this paper, we introduce a large-scale cRoss-dOmain Product Ecognition dataset, called ROPE. ROPE covers a wide range of product categories and contains over 180,000 products, corresponding to millions of short videos and live streams. It is the first dataset to cover product pages, short videos, and live streams simultaneously, providing the basis for establishing a unified product representation across different media domains. Furthermore, we propose a Cross-dOmain Product rEpresentation framework, namely COPE, which unifies product representations in different domains through multimodal learning including text and vision. Extensive experiments on downstream tasks demonstrate the effectiveness of COPE in learning a joint feature space for all product domains.